


The Weekly Kaitchup #35
QuaRot - 1-bit LLMs - Mixture-of-Depths


Hi Everyone,
In this edition of The Weekly Kaitchup:
QuaRot: Full 4-bit Inference
Are “1-Bit” LLMs Really That Good?
Mixture-of-Depths: Dynamically Allocating Compute for the Forward Pass
The Kaitchup has now 2,845 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (50+) and more than 100 articles. There is a 7-day trial.
The yearly subscription is currently 38% cheaper than the monthly subscription.
QuaRot: Full 4-bit Inference
There are now many methods to quantize LLMs to 4-bit. For instance, in The Kaitchup, I have presented: GPTQ, AWQ, SqueezeLLM, AQLM, and llama.cpp with GGUF.


All these methods are capable of quantizing the parameters of the models, but only some of them can also quantize the activations.
Activations
Starting from the input layer, activations propagate through hidden layers, undergoing transformations via weighted sums and activation functions, until reaching the output layer. Here, the final activations are converted into the model's predictions, such as token probabilities.
All these operations are done with the (b)float16 or float32 data types, even when the model’s parameters are quantized.
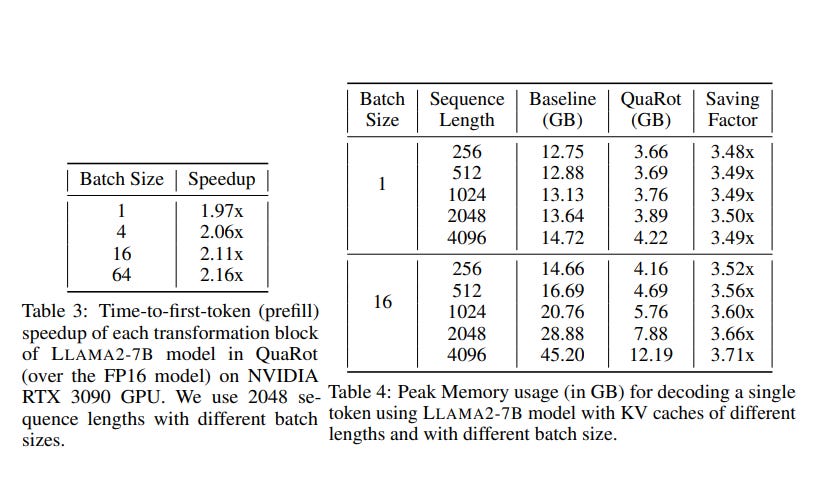
None of these quantization methods enables full 4-bit inference. Inference has to dequantize to perform operations. That’s why even if your model is quantized, increasing the batch size for inference still costs a lot of memory.
To the best of my knowledge, QuaRot is the first method to preserve 4-bit quantization at all stages of inference.
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs
The main idea behind QuaRot is to remove the outliers that are the main bottleneck. They are usually left unquantized to preserve the model’s accuracy.

This removal of outliers by QuaRot doesn’t impact the model’s performance. For instance, QuaRot retains most of the accuracy of Llama 2 70B.
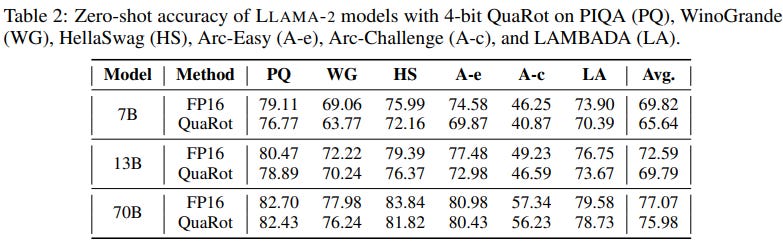
QuaRot quantizes everything: parameters, activations, and the KV cache. It makes quantized LLM very fast and memory-efficient for inference.
The authors made their code available on GitHub but I think it will take some time before we see it integrated into the main deep learning frameworks:
GitHub: spcl/QuaRot
Are “1-Bit” LLMs Really That Good?
Almost one month ago, Microsoft was publishing this paper:
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
This work found that 1-bit LLMs could achieve the same performance as their equivalent full-precision LLMs, trained on the same data and with similar hyperparameters. Many in the AI community, including me, were skeptical about these results.
No code and no models were released to support the claims.
These results needed to be reproduced independently for confirmation.
This is done. NousResearch could obtain similar results using OLMo-1B. They compared their ternary version of OLMo-1B, where each parameter is either -1, 0, or 1, to the fp16 version and observed similar learning curves.
These learning curves are publicly available:
wandb: Learning curves of OLMo-1B

The model is also released:
NousResearch/OLMo-Bitnet-1B (the model weights have been converted to fp16)
The next step is to optimize the hardware for such LLMs. Current GPUs are bad at performing operations with ternary weights.
It would also be interesting to see whether the claims still hold for larger models.
Mixture-of-Depths: Dynamically Allocating Compute for the Forward Pass
Google DeepMind presents a new method to better exploit computational resources for inference with transformer models:
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
The idea is simple. Instead of allocating the same compute to all tokens, the method trains the model to learn which tokens don’t need to go through certain layers of the models.
They called their technique “Mixture-of-Depths” (MoD), inspired by the Mixture of Experts (MoE) approach used in transformers, but with distinct differences in its application.

Unlike MoE, MoD dynamically determines at the token level whether to perform computations on a token using the standard transformer mechanism or bypass it via a residual connection, which doesn’t involve any computations.
This dynamic routing is applied across both the model's forward multilayer perceptrons (MLPs) and its multi-head attention mechanisms, affecting not only the processing of tokens but also their availability for attention interactions.

MoDs introduce a trade-off between accuracy and computational cost. Specifically, it enables the creation of MoD transformers that either outperform traditional transformers with the same computational cost or achieve similar performance levels while significantly reducing the necessary computations by up to 50%.
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) I have checked and updated, with a brief description of what I have done.
This week, I have checked and updated the following notebook:
#12 Quantize and Fine-tune LLMs with GPTQ Using Transformers and TRL - Examples with Llama 2
The notebook now fine-tunes GPTQ models for three epochs and achieves a loss similar to what I obtain with standard QLoRA fine-tuning. The quantization part itself didn’t change as it was still working, except that “disable_exllama” became “use_exllama” in Transformers which is much less confusing.
I have updated the related article to reflect these changes:

The Salt
The Salt is my other newsletter that takes a more scientific approach. In it, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week in the Salt, I reviewed:
⭐Jamba: A Hybrid Transformer-Mamba Language Model
sDPO: Don't Use Your Data All at Once
Long-form factuality in large language models
The Unreasonable Ineffectiveness of the Deeper Layers

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!