
Mixtral-8x7B: Understanding and Running the Sparse Mixture of Experts by Mistral AI
How to efficiently outperform GPT-3.5 and Llama 2 70B using your computer


Mistral AI released this week their new LLM:
mistralai/Mixtral-8x7B-v0.1 (Apache 2.0 license)
Mixtral-8x7B is a sparse mixture of 8 expert models. In total, it contains 46.7B parameters and occupies 96.8 GB on the hard drive.
Yet, thanks to this architecture, Mixtral-8x7B can efficiently run on consumer hardware. Inference with Mixtral-8x7B is indeed significantly faster than other models of similar size while outperforming them in most tasks.
In this article, I explain what a sparse mixture of experts is and why it is faster for inference than a standard model. Then, we will see how to use and fine-tune Mixtral-8x7B on consumer hardware.
I have implemented a notebook demonstrating QLoRA fine-tuning and inference with Mixtral-8x7B:
A Sparse Mixture of Experts

A sparse mixture of experts (SMoE) is a type of neural network architecture designed to improve the efficiency and scalability of traditional models. The concept of a mixture of experts was introduced to allow a model to learn different parts of the input space using specialized “expert” sub-networks. In Mixtral, there are 8 expert sub-networks.
Note that the “8x7B” in the name of the model is slightly misleading. The model has a total of 46.7B parameters which is almost 10B parameters less than what 8x7B parameters would yield. Indeed, Mixtral-8x7b is not a 56B parameter model since several modules, such as the ones for self-attention, are shared with the 8 expert sub-networks.
If you load and print the model with Transformers, the structure of the model is easier to understand:
MixtralForCausalLM(
(model): MixtralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MixtralDecoderLayer(
(self_attn): MixtralAttention(
(q_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MixtralRotaryEmbedding()
)
(block_sparse_moe): MixtralSparseMoeBlock(
(gate): Linear4bit(in_features=4096, out_features=8, bias=False)
(experts): ModuleList(
(0-7): 8 x MixtralBLockSparseTop2MLP(
(w1): Linear4bit(in_features=4096, out_features=14336, bias=False)
(w2): Linear4bit(in_features=14336, out_features=4096, bias=False)
(w3): Linear4bit(in_features=4096, out_features=14336, bias=False)
(act_fn): SiLU()
)
)
)
(input_layernorm): MixtralRMSNorm()
(post_attention_layernorm): MixtralRMSNorm()
)
)
(norm): MixtralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)I put in bold the MoE modules. We can see that the MoE blocks are separated from the self-attention blocks.
Each expert is responsible for handling a specific region or aspect of the input data, and a gating (or router) network determines how much each expert contributes to the final prediction. In the case of Mixtral, only 2 experts are activated at the same time. Around 13B parameters are used during inference, hence the more efficient inference compared to other models of similar size.
This sparse activation can be beneficial for several reasons:
1. Computational Efficiency: Activating only a subset of experts reduces the computational cost of evaluating the entire expert pool for every input.
2. Parameter Efficiency: By allowing only a few experts to be active for a given input, the model can allocate its parameters more efficiently.
3. Generalization: Sparse activation can encourage the model to learn more specialized and fine-grained features for different regions of the input space. This can lead to better generalization and performance on diverse inputs. For instance, Mistral AI claims that Mixtral has been trained in Italian, German, French, Spanish, and also for coding. We can imagine that they may have trained some of the 8 experts to be especially better for these languages and tasks.
While SMoEs are faster than standard models of a similar size, they still occupy the same amount of memory. Quantization is one way to reduce the memory consumption. Offloading some experts to a slower memory, e.g., the CPU RAM, may also be a good alternative when we know in advance which expert will be solicited for a given task.
What We Know about Mixtral
So far, not much.
Most of the details we know were published in this post by Mistral AI:
Mixtral is a model with 8 sub-networks acting as experts. At each layer and for each token, only 2 of these sub-networks are activated. Another set of parameters, the router network, decides on which ones to activate.
As for the training data, Mistral AI is again not very open:
Mixtral is pre-trained on data extracted from the open Web
I wonder what is the “open Web”.
They have evaluated the model on various public benchmarks to demonstrate that Mixtral is outperforming Llama 2 70B and GPT-3.5 on most of them.
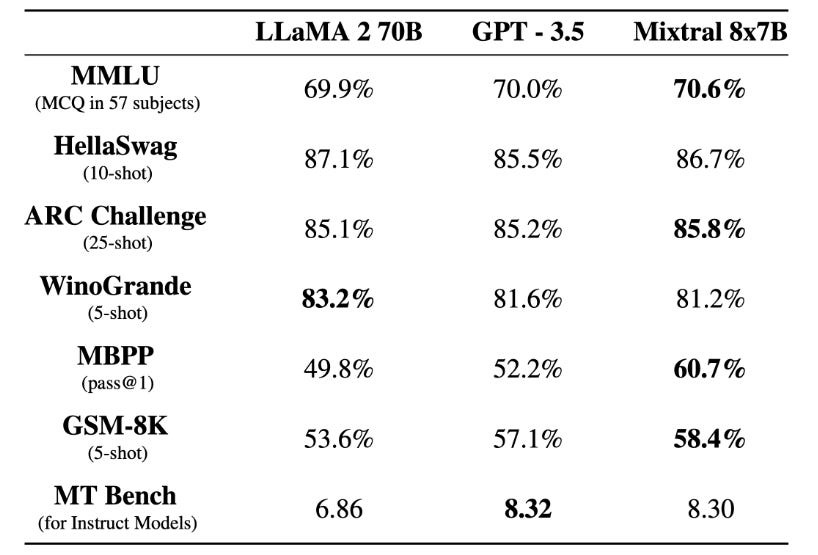
Running Mixtral on Your Computer
Mixtral is already supported by Hugging Face Transformers (from version 4.36.0) and bitsandbytes. We can quantize the model to fine-tune or run it on consumer hardware.
It also supports FlashAttention 2 which helps to reduce the memory consumption for the inference and fine-tuning with long sequences (up to 32k tokens).

In the model card, Mistral AI proposes a code sample to run the model:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, use_flash_attention_2=True)
text = "The mistral is"
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
In a Google Colab notebook, it only works with the A100 GPU (you need Google Colab Pro). The model has 46.7B parameters. Since the parameters are bfloat16, we need 2 bytes of memory per parameter, i.e., almost 100 GB free on your hard drive to download the model.
The model is available in the safetensors format. It is divided into 20 shards of around 4.95 GB. Once downloaded, it can take up to 7 minutes to load the model on the GPU.
When quantized to 4-bit, the model occupies 23 GB of VRAM. To run it smoothly on your computer, you will need at least two GPUs with 16 GB of VRAM each, for instance, 2 NVIDIA RTX 4060 16 GB* (which would cost around $900 in total), or even better, 2 NVIDIA RTX 4080 16 GB*.
For more recommendations on hardware configurations for LLMs, check this page:
*: Amazon affiliate links
Fine-tuning Mixtral on Your Computer
Mixtral also supports QLoRA fine-tuning. You can simply follow my previous tutorials fine-tuning Mistral 7B. It would work the same.


Here is a code sample for loading the model and preparing it for fine-tuning:
model_name = "mistralai/Mixtral-8x7B-v0.1"
#Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, add_eos_token=True, use_fast=True)
tokenizer.pad_token = tokenizer.unk_token
tokenizer.pad_token_id = tokenizer.unk_token_id
tokenizer.padding_side = 'left'
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name, quantization_config=bnb_config, device_map={"": 0}
)
model = prepare_model_for_kbit_training(model)You could also try to fine-tune it with IPO to make a strong Mixtral chat model.

Conclusion
The sparse mixture of experts is an efficient model architecture that allows faster inference than standard models of similar size. Nonetheless, while Mixtral only uses around 1/4 of its parameters at inference time, it still requires to have all the parameters loaded in memory.
One way to reduce the memory footprint of LLM is quantization. For instance, we can use bitsandbytes NF4 to quantize Mixtral to 4-bit. It’s then possible to run or fine-tune Mixtral on consumer hardware but you’ll need at least two GPUs.
Hopefully, Mistral AI will publish a technical paper disclosing more information about the method used to train the 8 experts of Mixtral.