
Training, Loading, and Merging QDoRA, QLoRA, and LoftQ Adapters
And How to Quantize LLMs After a Merge


LoRA is a method for parameter-efficient fine-tuning. It fine-tunes specialized adapters instead of fine-tuning the full model. Since the introduction of QLoRA, it has also become customary to fine-tune LoRA on top of quantized LLMs and several alternatives to QLoRA have been proposed, such as QDoRA, QA-LoRA, LQ-LoRA, and LoftQ to improve fine-tuning for quantized LLMs.
In this article, I compare and experiment with QDoRA, LoftQ, and QLoRA, and benchmark their performance and inference throughput. I especially compared three different configurations:
With the adapter loaded on top of the quantized model
With the adapter merged into the unquantized model
The same as 2. but followed by the quantization of the model
Merging an adapter and then quantizing the model might yield a significant drop in the model’s accuracy. In this article, I also show how to recover most of the lost accuracy using different quantization algorithms.
The notebook implementing the QLoRA, QDoRA, and LoftQ fine-tuning and adapter’s merging is available here:
QLoRA, QDoRA, and LoftQ
I used Mistral 7B as the base model and the openassistant-guanaco as training/validation data.
To train adapters with the three methods, I used the code I described in these articles:



The fine-tuning code is also available in the notebook (#61).
For QDoRA, I simply applied DoRA on top of the LLM quantized with bitsandbytes. Note: It wasn’t possible when I wrote the article about DoRA but now Hugging Face PEFT can apply DoRA to quantized layers.
I trained the adapter for one epoch with a batch size of 8.
Here are the learning curves:
Training loss:

Validation loss:
They are all very similar curves. In theory, DoRA is better than LoRA. It is expected to yield better results with smaller ranks than LoRA. LoftQ, in theory, is also better than QLoRA thanks to a better initialization of the adapter.
Which one should you use?
DoRA and LoftQ could be used together but, to the best of my knowledge, no one tried it. Hugging Face PEFT can’t do LoftQ with DoRA, yet.
Let’s see whether one is faster than the other for inference.
With the Adapter Loaded on Top of the Quantized Model
I loaded each adapter as follows:
model_name = "mistralai/Mistral-7B-v0.1"
adapter = "../qlora/checkpoint-1231"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
loading_start = time.time()
model = AutoModelForCausalLM.from_pretrained(
model_name, quantization_config=bnb_config, device_map={"": 0}, torch_dtype=compute_dtype, attn_implementation=attn_implementation
)
loading_adapter_start = time.time()
model = PeftModel.from_pretrained(model, adapter)Replace the content of “adapter” with the path of the adapter you want to load.
Then, I benchmarked their perplexity on the openassistant-guanaco’s test split and measured inference speed.
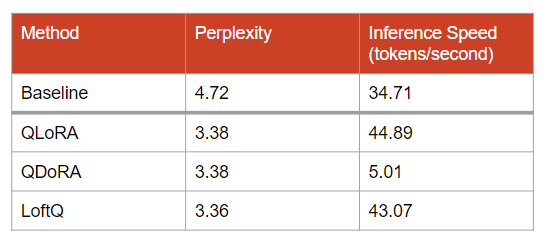
Note: I used Google Colab’s L4 instance to obtain these results.
The baseline system is Mistral 7B quantized with bitsandbytes and without any adapters loaded. All configurations yield a perplexity significantly lower than the baseline. Note: Lower perplexity is better.
As for the inference speed, QDoRA appears extremely slow. Using DoRA’s magnitude vector seems poorly optimized in PEFT. The DoRA adapter is so slow that it’s almost unusable.
Inference speed with QLoRA and LoftQ is comparable.
What is more surprising to me is that they are faster than the baseline. Note: I’m not sure I can explain it but I would assume that it is related to the adapters’ parameters not being quantized. There is no need to dequantize them during inference. However, the base model’s parameters are quantized, so it can’t fully explain this acceleration.
With the Adapter Merged into the Unquantized Model
Now, we are going to check the performance once the adapter is merged into the base model.
For the merge, I used the same method that I presented in this article:

The code for merging is in the notebook:
If you don’t follow this procedure, you may obtain a model significantly worse than when the adapter is simply loaded.
This procedure consists of:
quantizing the base model as we did for fine-tuning, i.e., using bitsandbytes NF4 with double quantization and with the same compute dtype
dequantizing the model to the same data type as the compute dtype used for fine-tuning
merging the adapter into the dequantized model
For this section, we will keep the model resulting from the merge in half-precision, i.e., not quantized. It makes it 4 times larger.
I ran the same benchmarks as in the previous section:
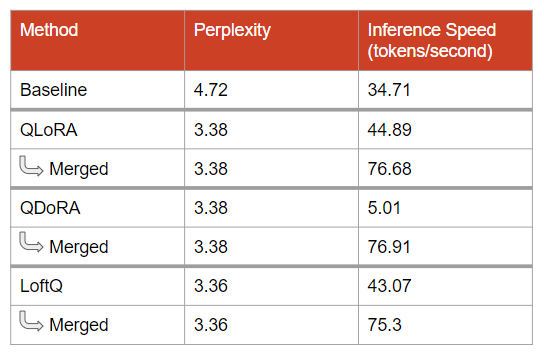
The models after the merge yield the same perplexity. However, they are much faster. This is because of the absence of quantization. Both the model’s parameters and activations, i.e., all the tensors created during inference, are 16-bit. There is no need to dequantize anything.
The DoRA adapter becomes usable after the merge.
With the Model Quantized After the Merge
The model after the merge is faster but also much larger. If we want to get a model with the same memory footprint we had during fine-tuning, we must quantize it again.
Following the merge, I quantize the model with the same bitsandbytes configuration used for fine-tuning and ran again the benchmark:

The perplexity significantly worsens. It is not as bad as the original model even though when using the model it may seem as if the model completely forgot what it learned during fine-tuning.
I have already given my assumptions on why this happens in a previous article:

When the adapter’s parameters are fine-tuned, they are not quantized. However, after the merge and the following quantization, they are now quantized to 4-bit. For the first time, we see the performance of the model with the adapter’s parameters quantized to 4-bit. This quantization yields a significant drop in the model’s accuracy.
However, it was still difficult to understand why this happens since 4-bit quantization is usually accurate enough to preserve most of the performance.
To confirm that this was really a problem with the 4-bit quantization, I ran additional experiments with other quantization algorithms.
After the merge, instead of quantizing the model with bitsandbytes, I quantized it with AWQ. Here are the results:

Note: I also tried with the GPTQ and obtained results very close to the one I obtained with AWQ but AWQ’s perplexity was consistently lower than GPTQ’s.
“NF4” configurations are the same as “quantized” in the previous table of results.
AWQ yields a much better perplexity than NF4. It is only slightly worse than the original perplexity that we had before quantization.
So, what’s happening with bitsandbytes’ NF4 quantization?
I assume that the adapter’s parameters are outliers that are “crushed” by this quantization scheme. Or, the implementation is bugged and doesn’t properly deal with the adapter’s parameters.
On the other hand, AWQ is “activation-aware”. In other words, AWQ automatically identifies that the adapter’s parameters are important and should be preserved from quantization.
Conclusion
Using the same hyperparameters, QLoRA, QDoRA, and LoftQ perform very similarly. QDoRA and LoftQ are better in theory than QLoRA. However, QDoRA’s adapters are very slow which leaves LoftQ as one of the best alternatives to QLoRA.
Merging the adapter into the base model yields significantly faster models, if left unquantized. For the quantization of the models after the merge, bitsandbytes NF4 should be avoided. AWQ and GPTQ are two alternatives that yield much better results for this specific situation.
In your notebook, I can't find dequantize_model function, so can't do experiment