
Don't Merge Your LoRA Adapter Into a 4-bit LLM
16-bit and quantization-unaware adapters


LoRA is a method for parameter-efficient fine-tuning (PEFT). It adds a small amount of trainable parameters on top of a frozen large language model (LLM). Since only the added parameters are trained, LoRA saves a lot of memory.
QLoRA is an even more memory-efficient method as it quantizes the base LLM on top of which the trainable parameters are added.
Typically, during QLoRA training, only the adapter’s parameters are saved. Then, we have two different methods to use the adapter for inference:
Loading it on top of the base LLM
Merging it into the base LLM
Preserving the base model while loading the adapter is convenient as we can easily replace the adapter with another one, almost seamlessly. Also since adapters are small, they are easy to store and distribute.
We can also merge the LoRA adapter into the base LLMs, for instance, to make the model easier to use, to hide the adapter, or to facilitate the training of yet another adapter on top of the merged model. The authors of LoRA demonstrated that merging a LoRA adapter into the base model can be perfectly done, i.e., without performance loss.
However, in the case of QLoRA and quantized LLMs, it doesn’t work as well. In a previous article: I compared different methods to merge adapters fine-tuned with QLoRA:

We saw that none of them were perfect. When I wrote this article, merging the adapter directly into the 4-bit quantized LLM fine-tuned with QLoRA wasn’t possible. We had to dequantize the model to make the merge possible.
Now, with the last version of the PEFT library, we can directly merge a LoRA adapter into the 4-bit LLM. It seems convenient...
But should we do it? What are the consequences?
In this article, I explain why we can’t perfectly merge an adapter fine-tuned with QLoRA into a quantized LLM. With simple experiments, I show that merging the adapter to the 4-bit LLM may lead to a significant performance drop.
If you want to reproduce my experiments, they are implemented in this notebook:
The Consequences of Merging a LoRA Adapter into a 4-bit LLM
Let’s have a look at the architecture of a 4-bit Llama 2 7B quantized with bitsandbytes NF4:
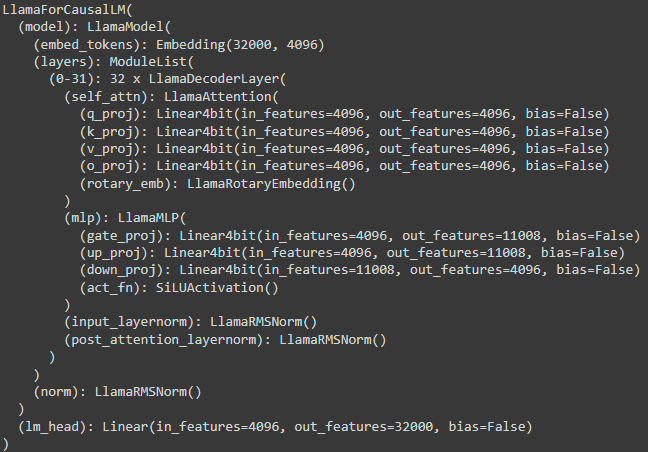
“Linear4bit” is applied for quantization to (almost) all the modules of the model:
The self-attention modules: q_proj, v_proj, o_proj, and k_proj
The MLP modules: gate_proj, up_proj, and down_proj
Note that the “lm_head” is not quantized. We can see it as the standard “Linear” is applied to this module.
Now, let’s add, on top of this model, LoRA for all the MLP modules. The architecture changes as follows:
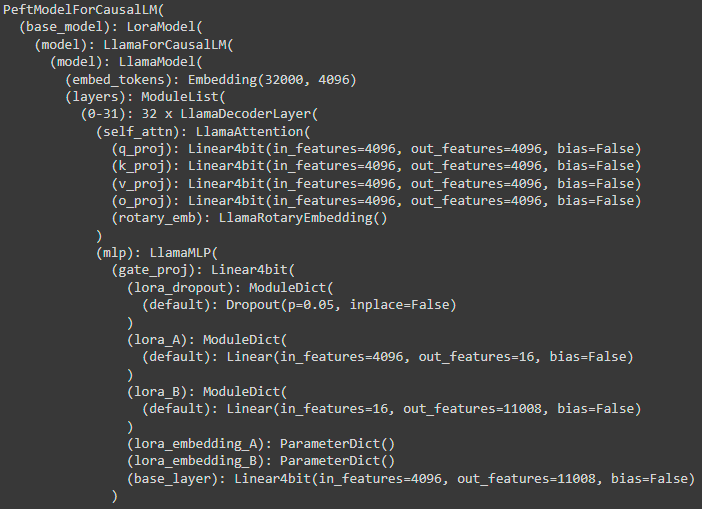
Note: I only print the beginning of the model’s architecture. The remaining MLP modules are not shown.
We can see that three new modules are introduced into the gate_proj module: lora_dropout and LoRA’s tensors A and B.
A and B’s parameters are trained during QLoRA fine-tuning. As we can see with “Linear”, these parameters are not quantized. In the QLoRA paper this is also illustrated as follows:
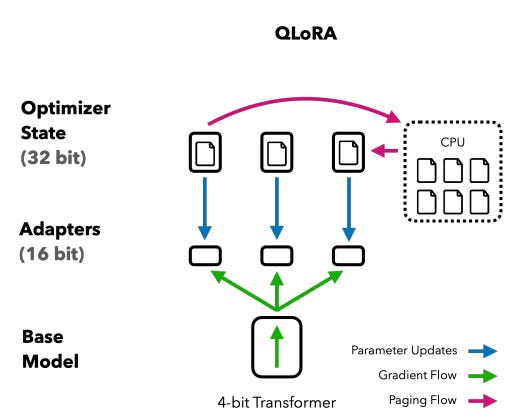
The adapters are 16-bit while the base model is 4-bit.
LoRA’s parameters are never quantized during QLoRA fine-tuning.
The values that are reported in the QLoRA training logs for the training loss and the validation loss are for LoRA’s parameter with a 16-bit precision.
When merged, LoRA’s modules disappear as their parameters are fully integrated into the existing 4-bit modules of the model. The model’s architecture after merging LoRA looks exactly the same as before we added LoRA:
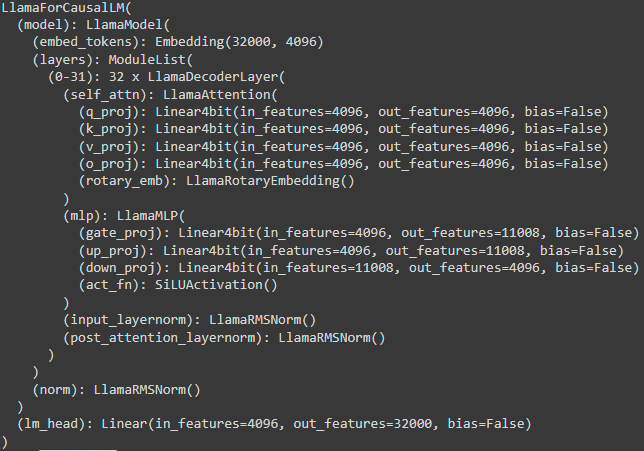
After the merge, LoRA’s parameters are virtually quantized (“virtually”, because these parameters are now indistinguishable from the base model’s parameters). Even though quantization can be very accurate, it still loses more or less information. In other words, we may get a model, after merging, that performs worse than the model we had at the end of QLoRA fine-tuning.
Nonetheless, the quantization of LoRA’s parameters is not the only reason why we may observe a significant performance drop.
LoRA’s parameters are not “quantization-aware”.
Indeed, during QLoRA fine-tuning, the base model is dequantized to the same data type as LoRA’s parameters. This is explained like this in the QLoRA paper:
We dequantize the storage data type to the computation data type to perform the forward and backward pass
The storage data type is NF4 (NormalFloat4, a 4-bit data type), while the compute data type is 16-bit (bf16 or fp16). LoRA’s modules only see the base model parameters with 16-bit precision.
Once LoRA’s parameters are merged into the 4-bit model, they are among 4-bit parameters that they have never seen before. They weren’t fine-tuned for this configuration. Consequently, the model resulting from the merge won’t be as good. The decrease in performance is unpredictable, i.e., we might not notice it or it might be significant.
Let’s check this with some simple experiments.