
TinyLlama: Pre-training a Small Llama 2 from Scratch
A truly "open-source" LLM that you can fine-tune, run and quantize on consumer hardware


TinyLlama is a project pre-training from scratch a 1.1B parameter Llama 2 on 3 trillion tokens.
Everything in the pre-training process of TinyLlama is documented: training hyperparameters, datasets, hardware configuration, learning curves, and more. As most companies making LLMs don’t document their pre-training process, TinyLlama is a very valuable resource to better understand pre-training.
In this article, I review how TinyLlama was pre-trained and the main lessons learned from this project. Then, we will benchmark TinyLlama’s memory efficiency, inference speed, and accuracy in downstream tasks. I compare the results with Llama 2 7B. We will also fine-tune TinyLlama and discuss whether quantization is useful for such a small model.
A notebook implementing fine-tuning, quantization, inference, and benchmarking of TinyLlama is available here:
Why a TinyLlama?
It all started from an observation made by Meta’s technical paper describing the training of Llama 2. The authors showed that Llama 2’s training loss was still decreasing when they decided to release the Llama 2 models, i.e., the models didn’t reach a saturation point in learning. This is illustrated by the following figure from the paper:

The models would likely be even better if trained longer or, in other words, on more tokens. Llama 2 has been trained on 2 trillion tokens. Note: To the best of my knowledge, we don’t know how many tokens were in the pre-training corpus. These “2 trillion tokens” refer to the total number of tokens seen by Llama 2 during pre-training over, potentially, several epochs. For instance, if Llama 2 models were trained for 2 epochs, it means that the pre-training corpus contained 1 trillion tokens, seen twice, hence 2 trillion tokens.
This observation supports the rationale behind TinyLlama for pretraining a 1.1 billion parameter model on 3 trillion tokens. The initiative aims not just to push the model's performance further but also to explore and understand the saturation phenomenon in deep learning models, offering valuable insights even if the loss does not decrease further.
Since Meta didn’t disclose the pre-training data of Llama 2, TinyLlama had to use a different dataset made of:
Slimpajama: A curated dataset made of text documents and containing a total of 627B tokens.
Starcoderdata: 250B tokens of code in 86 programming languages.
From these datasets, they excluded the GitHub subset of Slimpajama and sampled code from Starcoderdata. The final pre-training data contains 950B tokens with approximately two-thirds being from Slimpajama and one-third from Starcoderdata. If we aim at training TinyLlama on 3 trillion tokens, it means that we have to train for roughly 3 epochs (3*950B).
As for the architecture of TinyLlama, since this is a tiny Llama 2, they used the same architecture as the other Llama 2 models albeit with much fewer parameters.
Layers: 22
Attention heads: 32
Query groups: 4 (they used GQA for faster attention computation)
Embedding size: 2048
Intermediate size (Swiglu): 5632
The pre-training main hyperparameters are:
Sequence length: 2048
Learning rate: 4e-4
Batch size: 1024
The common practice in pre-training is to entirely fill the training batches, i.e., no padding. It means that the training batches of TinyLlama contain 1024 (batch size) * 2048 (sequence length) = 2 million tokens.
Since the batches are huge, they require many GPUs. The project pre-trained TinyLlama on 16 A100-40G GPUs.
Pre-training TinyLlama Over 3T Tokens
The training loss clearly shows that even after training on 3T tokens, the model didn’t reach saturation:
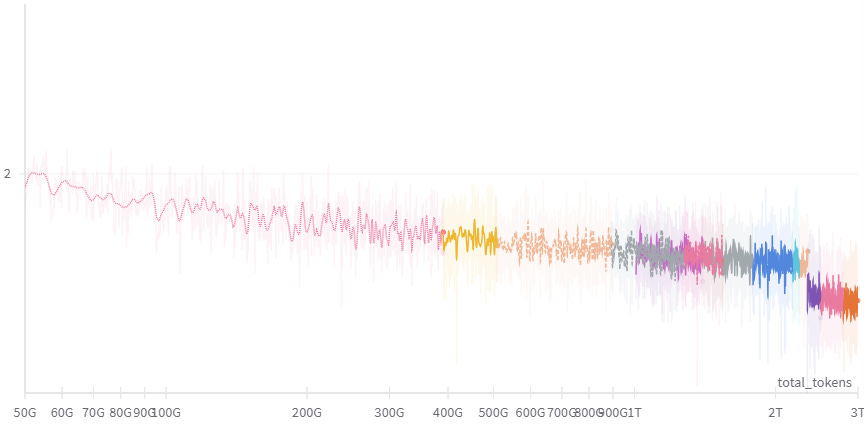
It could be trained longer and the loss would still decrease. Note: Around 2.2T tokens, we can see a significant decrease in the loss. This is simply due to a correction of a bug in the loss computation.
It took more than 3 months for the TinyLlama project to release the 3T checkpoint:
This project highlights very well the cost of pre-training LLMs. TinyLlama is only a 1.1B parameter model. Yet, the project had to use 16 A100-40G GPUs over almost 3 months. Even on a very cheap cloud, e.g. $1 per A100-40G per hour, it would cost around $35,000.
Moreover, note that this project already used many optimizations to speed up the pre-trainmulti-GPUi-gpu and multi-node distributed training with FSDP.
flash attention 2.
fused layernorm.
fused swiglu.
fcross-entropytropy loss .
fused rotary positional embedding.

Without these optimizations, the training cost would have been doubled.
Benchmarking Inference: TinyLlama vs. Llama 2 7B
TinyLlama is almost 7 times smaller than the smallest Llama 2. Smaller models have the advantages of being faster and to have a lower memory footprint.
I used optimum-benchmark to measure TinyLlama’s decoding throughput and peak memory usage and compared it with Llama 2 7b.

Here are the results I obtained:

Note: The optimum-benchmark configurations that I used to generate these results are in the notebook.
TinyLlama is significantly faster. It generates 32 tokens more per second than Llama 2 7B. It also consumes only 4 GB of memory which is roughly what Llama 2 7B would consume once quantized to 4-bit.

However, smaller models are also, usually, not performing as well in downstream tasks. I used the Evaluation Harness to check TinyLlama's accuracy in the following tasks (with 5-shot prompting).

Winogrande: Benchmark evaluating commonsense reasoning.
Arc Challenge: A set of grade-school science questions.
HellaSwag: Benchmark evaluating commonsense inference.

TinyLlama largely underperforms Llama 2 7B in all tasks. If you have a GPU with at least 6 GB of VRAM, it is better to use Llama 2 7B quantized to 4-bit than using TinyLlama. You can find more details about Llama 2 7B's performance, once quantized, in this article:

If you have less memory available, then using TinyLlama might be better as we will see in the following sections.