
LQ-LoRA: Jointly Fine-tune and Quantize Large Language Models
Better quantization and better fine-tuned adapters
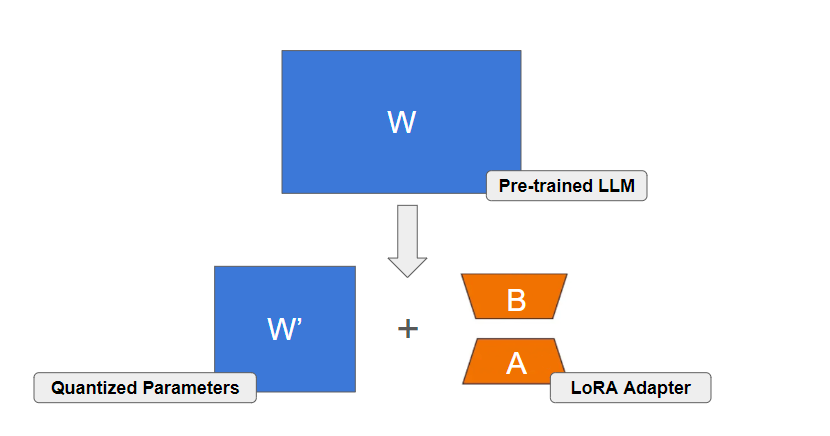
QLoRA is one of the most popular methods to fine-tune adapters on top of quantized LLMs. While QLoRA is very effective, it has also several drawbacks that we have discussed in previous articles:

There are alternatives to QLoRA. For instance, we have tried QA-LoRA which fine-tuned quantization-aware LoRA adapters. QA-LoRA is a good alternative to QLoRA but its official implementation wasn’t supporting recent LLMs and has since been removed from GitHub by its authors.

We need another alternative.
In this article, I present LQ-LoRA: A method decomposing a pre-trained LLM into fixed quantized parameters and a trainable LoRA adapter. We will see how it works and why it performs better than QLoRA.