
This Week: Arcee Trinity and Quantization-Aware Distillation
The Weekly Kaitchup #128


Hi everyone,
In this edition of The Weekly Kaitchup, we discuss:
Quantization-Aware Distillation: Better than Quantization-Aware Training?
Arcee Trinity Large: A Promising Large Model
Quantized GLM 4.7 Flash
Quantization-Aware Distillation: Better than Quantization-Aware Training?
NVIDIA’s Blackwell GPUs are built to run FP4 fast. Unsurprisingly, NVIDIA has been pushing FP4 not only for inference, but also for training, with a particular emphasis on its in-house format: NVFP4.

The catch is that NVFP4 quantization can noticeably hurt model accuracy, and in practice, that drop often feels more pronounced on smaller models and when generating long sequences.
A common way to reduce this loss is quantization-aware training (QAT), where quantization effects are simulated during training so the model can adapt to them.
This week, NVIDIA introduced an alternative aimed at the same goal: quantization-aware distillation, which recovers accuracy by training the quantized model to match the outputs of its full-precision counterpart.
Quantization-Aware Distillation for NVFP4 Inference Accuracy Recovery
The key insight behind QAD is that instead of training the quantized model using task-specific losses like in traditional QAT, it’s more effective to distill the behavior of the original full-precision model directly. This is done by minimizing the KL divergence between the soft output distributions of the full-precision “teacher” model and the quantized “student” model.
Nothing fancy here, but this method proves especially useful in realistic, post-training scenarios where models have already gone through multiple stages of fine-tuning or reinforcement learning, and where retraining from scratch (as often required in QAT) is not feasible.
What Makes QAD Different from QAT?
QAT tries to train a quantized model using the original task loss (e.g., cross-entropy), directly optimizing performance on the original dataset.
However, this often leads to shifts in output behavior, even when the validation loss is recovered. This shift can be problematic for applications that depend on the specific outputs of the pretrained model. QAT, when not done early during training, can only be useful if you do it with data and training objectives that match your specific target tasks.

In contrast, QAD aligns the quantized model’s outputs with those of the full-precision model itself. By training the quantized model to match the distribution of predictions from the original model, rather than the ground-truth labels, QAD leads to closer behavioral fidelity, especially in high-sensitivity domains like language generation.
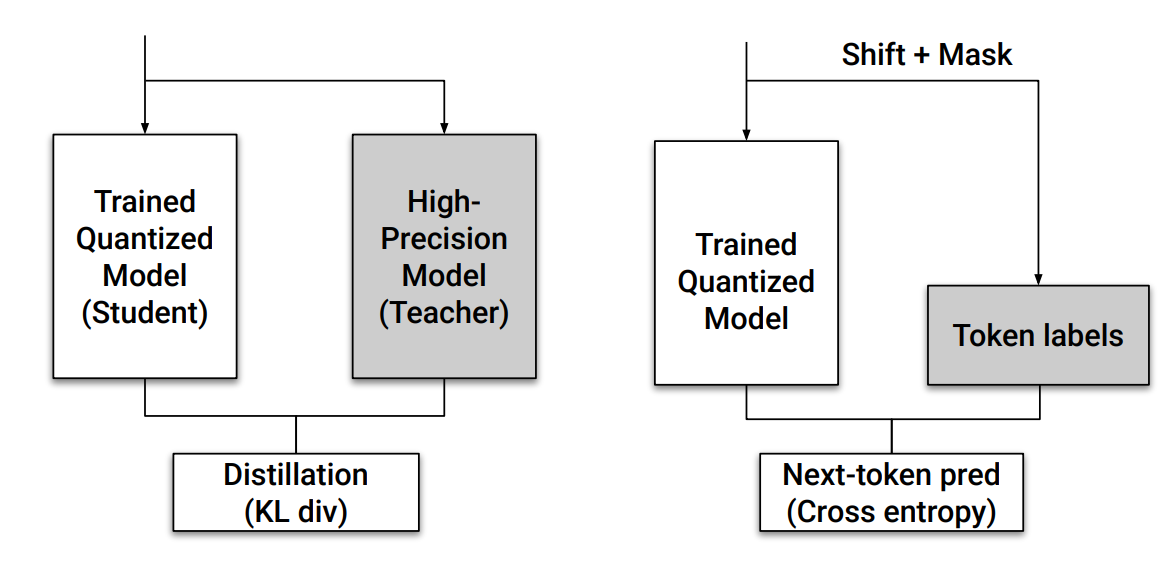
Another major advantage is simplicity. QAD does not require replicating the original training pipeline (which can involve multi-stage tuning with various losses and data). It only needs access to the full-precision model and some unlabeled data for distillation. This makes QAD a practical drop-in method for post-quantization recovery.
And it works:
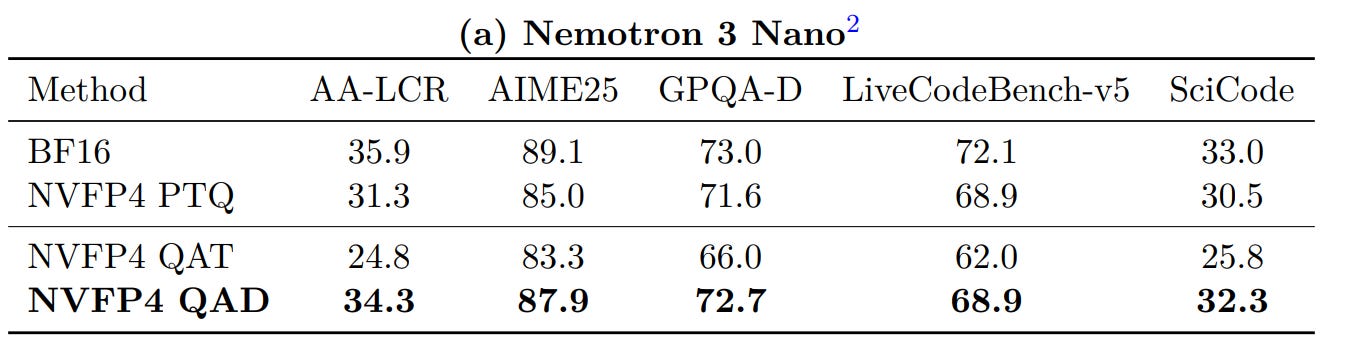
From their results, a few things stood out to me.
First, I was surprised by how poorly PTQ performs in their setup. That’s not what I’ve seen on ~30B models, where NVFP4 PTQ can be fairly well-behaved. One plausible explanation is that this model’s hybrid architecture is simply more sensitive to quantization, with more activation outliers and trickier calibration dynamics.
Second, the QAT results look genuinely bad: accuracy drops after “QAT,” meaning you pay the extra training cost and end up worse than PTQ. But to be fair, what they run isn’t really “full QAT” in the way people usually mean it for modern LLMs. For multi-stage pipelines (SFT → RL → merges), true QAT would imply re-running that entire pipeline with quantization in the loop, something they explicitly argue is hard and unstable. What they’re doing is closer to a best-effort, QAT-like fine-tuning pass applied after heavy post-training. In that regime, it’s not that surprising that it fails, this is exactly the motivation for proposing QAD.
Their QAD approach does recover a meaningful part of the accuracy gap, but performance is still noticeably below BF16.
Still, even with that gap, this model looks like the best efficiency/accuracy trade-off in its class right now. NVFP4 cuts the model footprint from ~63.2 GB to ~19.4 GB, and you also get the structural advantages of the architecture: it’s a sparse MoE with only ~3B parameters active at inference, plus a hybrid design where the KV cache for 262k tokens is only ~1.5 GB of GPU memory. That’s essentially negligible. And importantly: don’t even think about quantizing the KV cache here, as doing so would mostly add overhead and slow the engine down, as we saw earlier this week:

For comparison, at the same context length, Qwen3 4B needs around 38 GB just for the KV cache. The model itself may be ~7x smaller than Nemotron 3 Nano, but each token costs ~25x more memory.
They released their QAD checkpoint for Nemotron 3 Nano here:
Arcee Trinity Large: A Promising Large Model
Arcee Trinity is a family of sparse Mixture-of-Experts (MoE) language models: Trinity Nano (6B total / ~1B active per token), Trinity Mini (26B / ~3B active), and Trinity Large (400B / ~13B active). The common goal is to keep inference efficient by activating only a small slice of the parameters per token.
For now, they have only released the Large variants, including a “preview” version without much post-training:
Architecture: Sparser MoEs
On the architecture side, the core choices are aimed at long-context performance without blowing up compute.
Attention uses a repeating 3:1 pattern of local to global layers: local layers run sliding-window attention with RoPE, while every fourth layer is global attention without positional embeddings (NoPE).
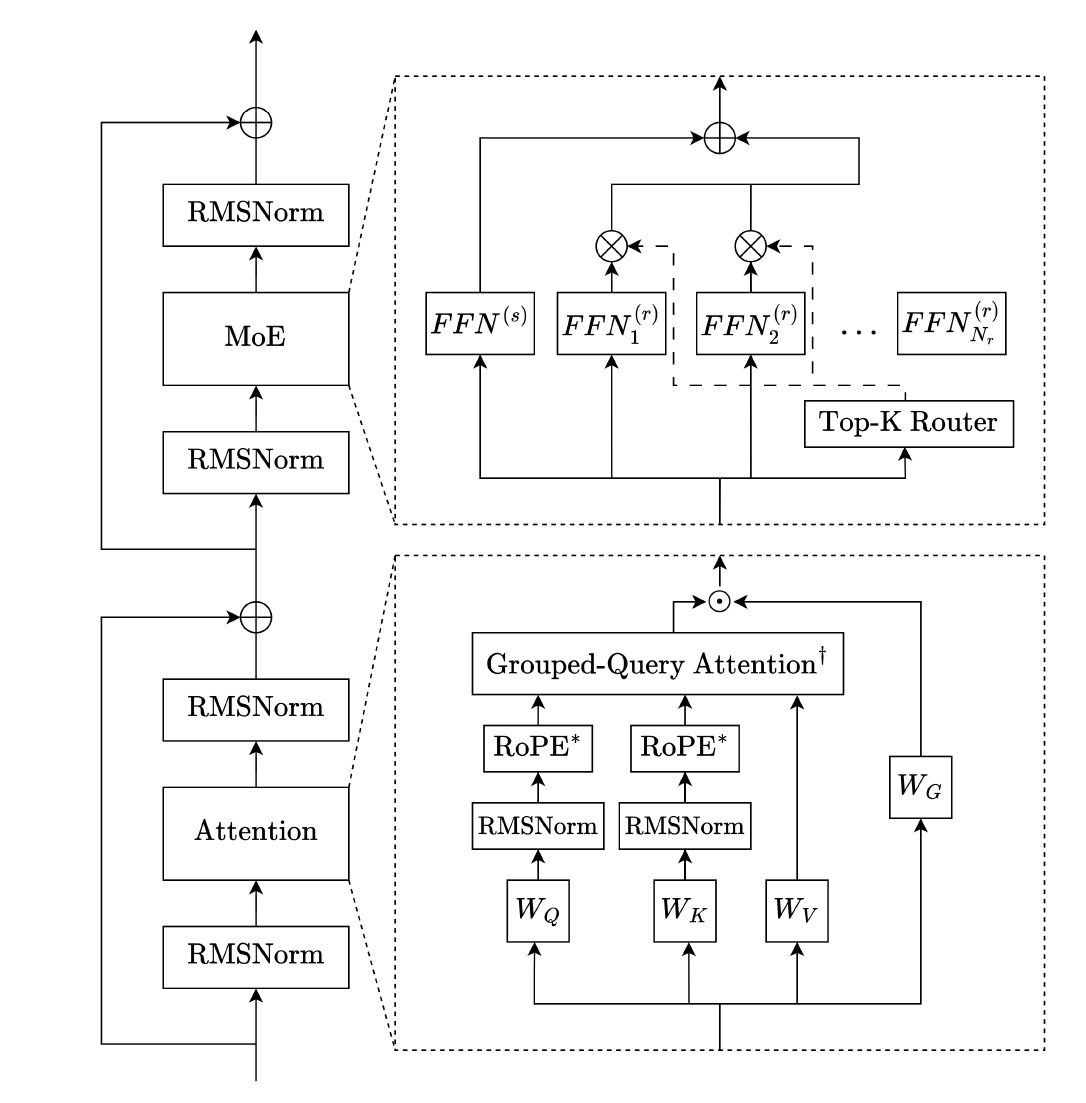
They also use grouped-query attention (GQA) to reduce KV cache size, QK-normalization for stability, and gated attention (a learned sigmoid gate applied to the attention output) to damp large activations and reduce training issues.
The MoE blocks follow a DeepSeekMoE-style setup with routed experts plus an always-on shared expert, SwiGLU in the FFNs, and sigmoid-based routing with normalized gate scores.
For Trinity Large, they use fewer but larger experts (coarser granularity) to improve throughput, and they replace the first several MoE layers with dense layers to stabilize early training. Normalization is a depth-scaled “sandwich” RMSNorm variant (normalize before and after sublayers, with depth-scaled gain), plus a final RMSNorm before the LM head.
Trinity Large has 398B parameters among which only 13B are active during inference. That’s only 4 experts among 256 (1.56% sparsity).
Training
Nano and Mini were pretrained on 10T tokens, while Large used 17T tokens sampled from a 20T mix. The data mix shifts in three phases toward higher-quality material and more math/code/STEM.
A big chunk of that corpus is synthetic: DatologyAI generated multi-trillion-token synthetic web, multilingual, and code data, produced at scale with Ray + vLLM on Kubernetes.
Training uses on-the-fly tokenization and sequence packing. For Trinity Large, they found that very long documents could dominate consecutive batches and increase step-to-step variance, so they introduced RSDB (Random Sequential Document Buffer) at the start of phase 3 to mix tokens from many documents more randomly.
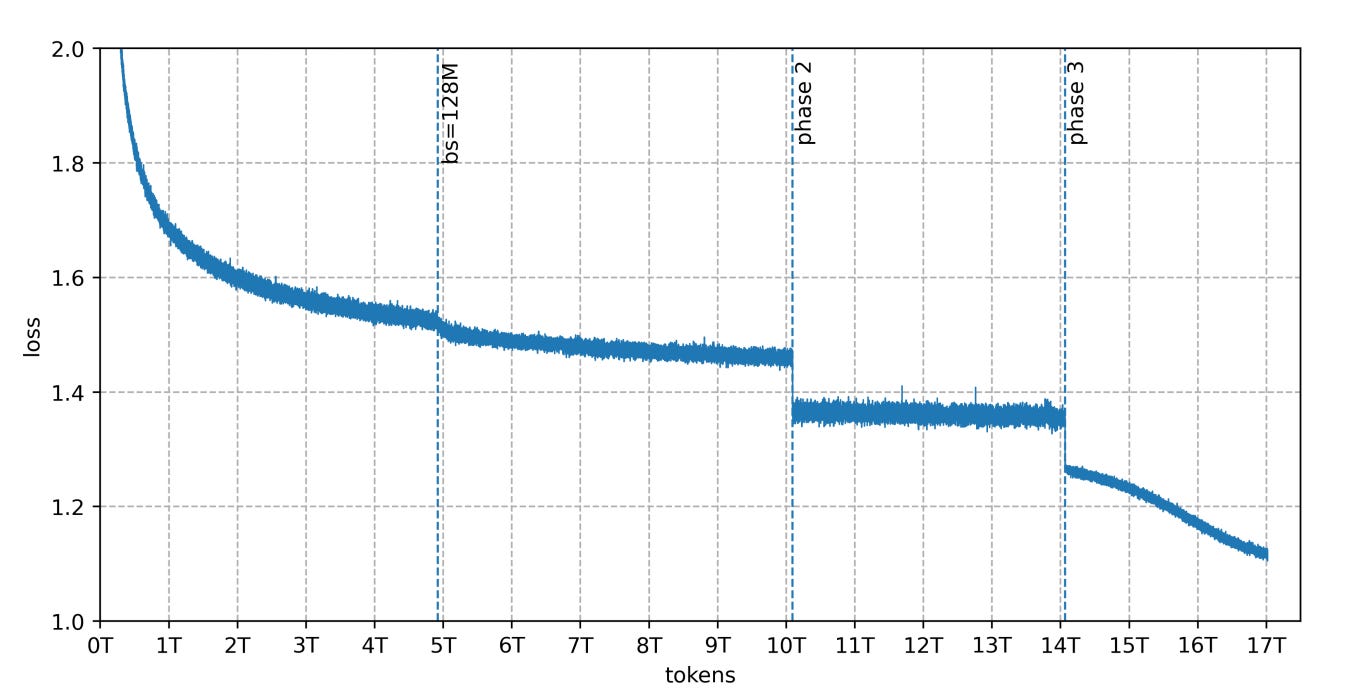
Early Large runs also saw MoE routing drift that led to uneven expert load and collapsed experts. To stabilize, they switched to SMEBU load balancing (tanh-clamped, momentum-smoothed expert bias updates) and combined it with a handful of other changes (precision adjustments, small z-loss, a sequence-wise balancing loss, more initial dense layers, and intra-document masking). After that, they report stable routing and a smooth loss curve without spikes.
Yes, that’s very complex! It shows how much pre-training a model is not just pressing a button and forgetting about it. It’s a constant monitoring with many adjustments made on-the-fly, and often with a lot of mistakes/bad calls requiring even more interventions.
Evaluation
The main point is that Trinity Large Base is competitive with similarly positioned open-weight models while keeping active parameters low via sparsity. They compare, for instance, against GLM 4.5.
For next steps, they call out two priorities: improving routing/load balancing to support even higher sparsity, and pushing large-batch training further (higher critical batch sizes without losing stability or sample efficiency).
I have the feeling that this will be one of the best open models we will get this year, but I’m even more eager to get the Nano and Mini versions to run them locally.
reference: technical report
Quantized GLM 4.7 Flash
I released 4-bit versions made with AutoRound here:
They work quite well and now consume only ~17 GB, so a 24 GB GPU (RTX 3090 or 4090) can run them.
I tried to go lower with AutoRound’s mixed-precision algorithm, but the quality quickly drops.
If you are searching for an NVFP4 version for fast inference with Blackwell GPU, my collection above also includes a community-made NVFP4 version that I’ve found works well with vLLM 0.15.
Next week, I’ll publish a full review of these models’ accuracy and efficiency. It may land a bit later than my usual Monday slot, since the evaluation is still ongoing and not yet close to finished.
I’m also working on a similar analysis for the LFM2.5 models, but I’ve postponed it because the NVFP4 variants show quality issues. I’ll try with NVIDIA ModelOpt but if issues persist, I’ll likely exclude NVFP4 from the final evaluation.
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week, we review:

⭐Fast KVzip: Efficient and Accurate LLM Inference with Gated KV Eviction
Post-LayerNorm Is Back: Stable, ExpressivE, and Deep
Lost in the Prompt Order: Revealing the Limitations of Causal Attention in Language Models
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!
Has anyone applied QAD to GLM-4.7-Flash yet?
Can you please do a deep dive into REAP, the newer REAM and competitors if they exist? https://bknyaz.github.io/blog/2026/moe/ I have tried REAP versions of MiniMax 2.1 and it seems to work well generally. Does REAM have the potential for larger gains? Why are both not more popular?