


The Weekly Kaitchup #9
QA-LoRA - Streaming LLMs

Hi Everyone,
In this edition of The Weekly Kaitchup:
QA-LoRA: A very promising alternative to QLoRA which is faster for fine-tuning and that produces adapters easier to merge with the base model.
Streaming LLM: Deploy LLMs for infinite-length inputs without sacrificing efficiency and performance.
The Kaitchup has now 701 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
If you are a monthly paid subscriber, switch to a yearly subscription to get a 17% discount (2 months free)!
QA-LoRA: QLoRA but Without Dequantization
QLoRA is a very popular way to fine-tune large language models on consumer hardware. I used it many times in my previous articles:


It quantizes the base LLM, freezes its parameters, and then fine-tunes LoRA adapters on top of it. Only the base model is quantized, i.e., LoRA’s parameters are still fp16. This is not ideal since:
It slows down fine-tuning.
It makes the fine-tuned adapters challenging to merge with the base model since the base model is quantized (with nf4) but not the adapter’s parameters.
I studied and summarized some techniques to merge LoRA adapters fine-tuned with QLoRA in the following article:

Nonetheless, the techniques I showed don’t prevent the performance drop observed if we quantize again the merged model.
QA-LoRA proposes to remove this issue by fine-tuning the LoRA adapters while preserving the same quantization (int4, int3, or int2) during inference. You could almost see it as QA-LoRA quantizing the LoRA adapters during fine-tuning (but in practice it’s a bit more complicated than that) while QLoRA doesn’t.
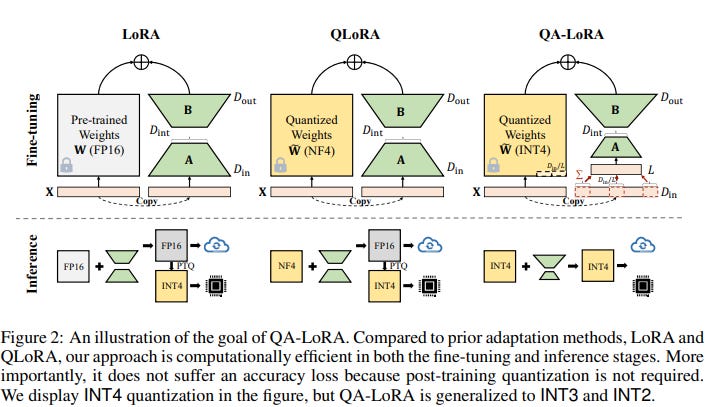
QA-LoRA fine-tuning is faster and without performance loss once the adapter is merged.
It seems that this is a significant advance for affordable AI. I’m now writing a more detailed review of QA-LoRA and a tutorial on using it. Expect it next week in your mailbox.
Meanwhile, you will find more details about the approach and its performance in the arXiv paper:
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models (Xu et al., 2023)
Efficient Streaming Language Models with Attention Sinks
It looks like there is every week a new approach promising very long or almost infinite context length for LLMs.
This week, a new work involving Meta proposed to extend the context size of LLMs to 4 million tokens and more.
Efficient Streaming Language Models with Attention Sinks (Xiao et al., 2023)
In contrast with previous work, this new study particularly focuses on dialogue and exploits a new technique using so-called “attention sinks”.

Causal LLMs give a lot of attention to tokens at the beginning of a dialogue but, as the number of dialogue turns increases, these tokens that received a lot of attention become too far from the current dialogue turn. It significantly impacts the performance of LLMs in long dialogues.
To alleviate this issue, this work proposes to add tokens acting as attention sinks, and then repeat these tokens at each dialogue turn to make sure they remain in the dialogue context.
It doesn’t mean that the entire context of the dialogue is repeated but only the information carried by the attention sinks. Most tokens are actually “evicted” from the context. The authors found that this technique works well for dialogue but not for other tasks such as summarization since most tokens are not included in the context.
While this technique preserves important information for the dialogue context, it is also simple as it doesn’t require recomputing KV states for the entire context for each new dialogue turn. It uses a rolling cache as follows:

Compared to a baseline using a sliding window for the attention computation, this approach is 22x faster according to the authors.
They released their implementation of StreamingLLM on GitHub.
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!