


The Weekly Kaitchup #75
MiniMax-01 - Qwen2.5 PRM - Kokoro and OuteTTS


Hi Everyone,
In this edition of The Weekly Kaitchup:
MiniMax-01: Better than DeepSeek-V3?
The Qwen2.5 Math Process Reward Models (PRM)
The Revenge of Open TTS: Kokoro and OuteTTS 0.3
MiniMax-01: Better than DeepSeek-V3?
MiniMax released a huge open LLM this week:
According to the results they published, it achieves better performances than DeepSeek-V3 on most benchmarks.

It even outperforms commercial models like Claude and Gemini on some benchmarks:
As usual, take these results with a pinch of salt as we don’t really know how they were computed.
They published a 68-page report with a lot of details on the model architecture and training phases:
MiniMax-01: Scaling Foundation Models with Lightning Attention
MiniMax-01, like DeepSeek-V3, uses a mixture-of-experts approach. However, its architecture differs significantly. While MiniMax-01 features 'only' 456 billion parameters compared to DeepSeek-V3’s 685 billion, it activates more parameters during inference—45.9 billion versus 37 billion. Furthermore, MiniMax-01’s experts are fewer in number but substantially larger.
The main innovation of MiniMax-01 is its lightning attention:
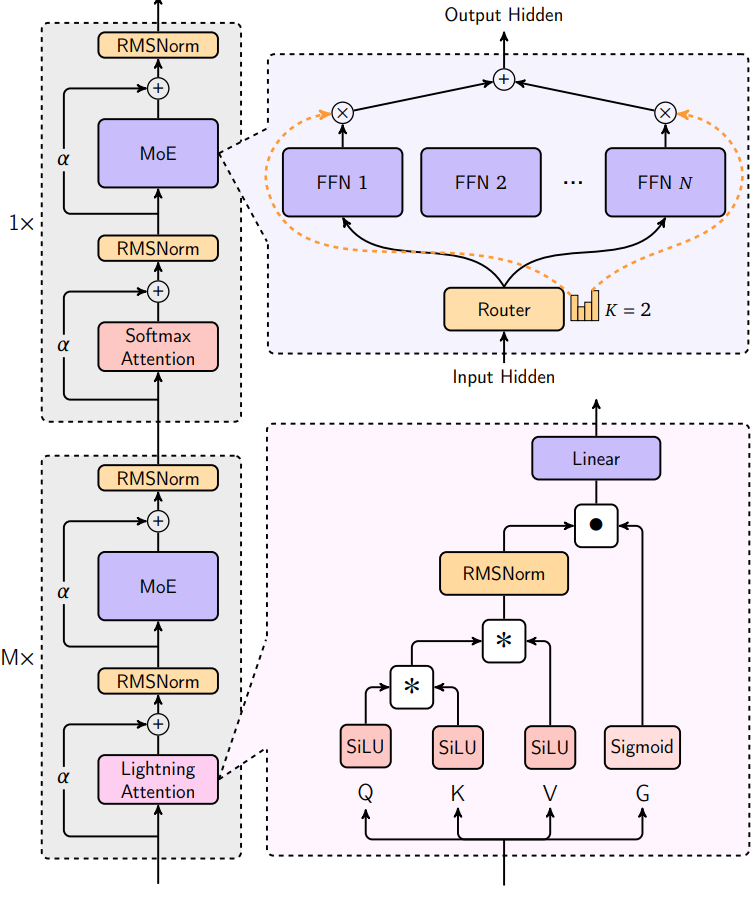
Lightning attention is a very hardware-optimized implementation of linear attention, a variant of the Transformer’s attention mechanism that nearly achieves linear computational complexity, compared to the quadratic complexity of standard attention. This significantly speeds up inference time.
MiniMax is a very impressive work. And they also released a VLM version that I didn’t have time to check:
The Qwen2.5 Math Process Reward Models (PRM)
LLM are getting better at mathematical reasoning but they are still prone to errors, including miscalculations and logical mistakes, which can lead to incorrect conclusions. Even when producing correct final answers, these models often generate flawed reasoning steps. To address this, Process Reward Models (PRMs) have been developed by OpenAI as a method to detect and mitigate reasoning errors.
Developing PRMs faces significant challenges, including the costly and time-intensive annotation of data for evaluating reasoning correctness. While human annotation yields high-quality results, automated methods like Monte Carlo (MC) estimation are widely used but suffer from noise and inaccuracies due to reliance on generated completion quality. Evaluating PRMs is further complicated by Best-of-N (BoN) evaluation, which prioritizes correct final answers over intermediate reasoning accuracy, shifting focus from process to outcome evaluation.
To address these issues, the Qwen team proposes a consensus filtering mechanism combining MC estimation with LLM-as-a-judge to retain data only when both methods agree on reasoning errors, enhancing data utility and PRM performance.

They also recommend integrating BoN evaluation with step-wise benchmarks like PROCESSBENCH to improve error detection in reasoning processes.
They explain their process to train PRM models here:
The Lessons of Developing Process Reward Models in Mathematical Reasoning
And they released very good open Math PRM models, with 7B and 72B parameters, here:
These models could be used for instance in better supervising the training of models with good reasoning capabilities. This is probably what Qwen did to train QwQ and QvQ.

The Revenge of Open TTS: Kokoro and OuteTTS 0.3
Text-to-speech (TTS) remains, in my view, one of the areas where open models still lag significantly behind commercial solutions. With OuteTTS 0.3 and Kokoro, we have new open TTS models to try!
OuteTTS 0.3: LLM to TTS
OuteTTS is a unique model that leverages an LLM, specifically OLMo and Qwen2.5, to generate speech with minimal architectural changes. Version 0.3 of OuteTTS introduces several improvements over version 0.2, including more natural voice quality (particularly in tonal accuracy) and support for additional languages. It now supports English (en), Japanese (jp), Korean (ko), Chinese (zh), French (fr), and German (de).
OuteTTS is available in two sizes: a 500M version, based on Qwen2.5 0.5B, and a 1B version, based on OLMo 1B. However, the 1B version uses a training dataset with a limited license, making OuteTTS 0.3 1B available under the CC-BY-NC-SA license. Meanwhile, OuteTTS 0.3 500M is released under the more permissive CC-BY-SA license.
You can download the models here:
Hugging Face Collection: OuteTTS 0.3
Kokoro: The Top of the TTS Arena
Kokoro was originally released last December, but it received a significant update this week, further enhancing its performance.
Despite having only 82 million parameters and being trained on less than 100 hours of audio, Kokoro achieved the top rank in the TTS Spaces Arena. Kokoro also surpassed other models in Elo rankings, outperforming them with fewer parameters and less training data.
Additionally, Kokoro comes with a permissive Apache 2.0 license, making it accessible for a wide range of applications.
Hugging Face: hexgrad/Kokoro-82M
I’m excited to try both OuteTTS and Kokoro in my toolbox implementing NotebookLM to generate consistent voices for a podcast. So far, all the open TTS models I’ve tested have fallen short of delivering satisfying results, but I’m hopeful these new models will perform better.
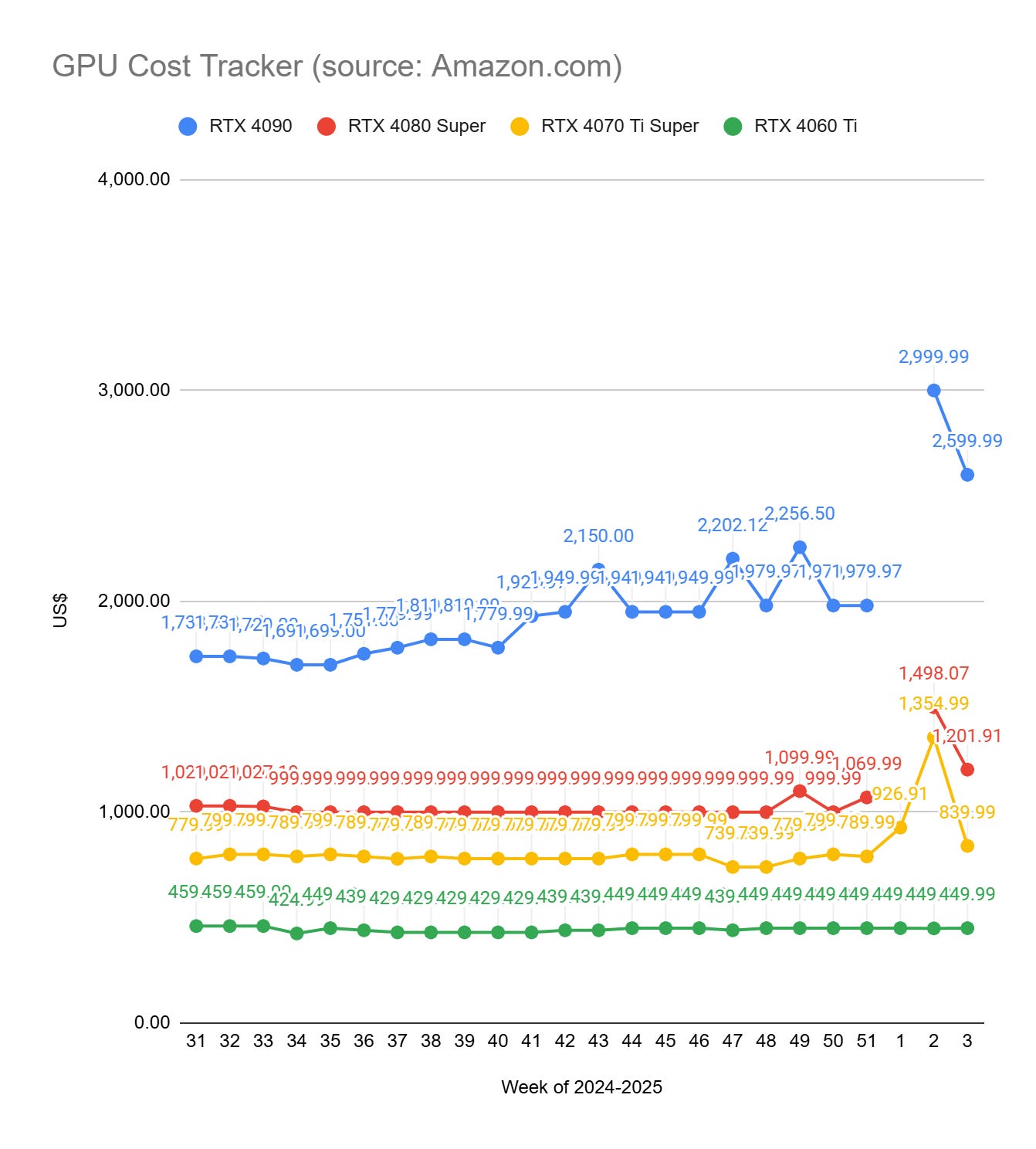
GPU Selection of the Week:
To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
With NVIDIA's announcement of the RTX 50 series, all the RTX 4090/4080/4070 became unaffordable. Since an RTX 5060 wasn’t announced, the RTX 4060 remains at the same price.

RTX 4090 (24 GB): ASUS TUF GeForce RTX 4090 24GB OG Edition Gaming Graphics Card
RTX 4080 SUPER (16 GB): Inno3D GeForce RTX 4080 Super iChill Black
RTX 4070 Ti SUPER (16 GB): ASUS The SFF-Ready Prime GeForce RTX™ 4070 Ti Super OC Edition
RTX 4060 Ti (16 GB): PNY GeForce RTX™ 4060 Ti 16GB Verto™ Dual Fan
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
GeAR: Generation Augmented Retrieval
⭐Segmenting Text and Learning Their Rewards for Improved RLHF in Language Model
Scaling Laws for Floating Point Quantization Training
Support The Kaitchup by becoming a Pro subscriber:
What You'll Get
Priority Support – Fast, dedicated assistance whenever you need it to fine-tune or optimize your LLM/VLM. I answer all your questions!
Lifetime Access to All the AI Toolboxes – Repositories containing Jupyter notebooks optimized for LLMs and providing implementation examples of AI applications.
Full Access to The Salt – Dive deeper into exclusive research content. Already a paid subscriber to The Salt? You’ll be refunded for the unused time!
Early Access to Research – Be the first to access groundbreaking studies and models by The Kaitchup.
30% Discount for Group Subscriptions – Perfect for teams and collaborators.
The Kaitchup’s Book – A comprehensive guide to LLM fine-tuning. Already bought it? You’ll be fully refunded!
All Benefits from Regular Kaitchup Subscriptions – Everything you already love, plus more. Already a paid subscriber? You’ll be refunded for the unused time!
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!