


The Weekly Kaitchup #73
2025 - Smolagents - Bamba


Hi Everyone,
And a Happy New Year!
In this edition of The Weekly Kaitchup:
The Kaitchup in 2025
Hugging Face’s SmolAgents
Bamba: Why I’m Losing Faith in Transformer Alternatives
The Kaitchup in 2025
Topics
For this new year, I don’t plan to change much about The Kaitchup since it has been performing well and receiving great feedback. However, I will publish more often about the following topics:
coding with LLMs
deploying LLMs in production
There seems to be a growing disinterest among LLM practitioners in fine-tuning, which I’ve extensively covered this year. This shift likely reflects the increasing number of LLMs that are effective out-of-the-box for many tasks. Still, I firmly believe fine-tuning remains essential for improving performance on specific target tasks. As such, I plan to continue covering new fine-tuning techniques and fine-tuning methods for the new LLMs that will be released this year, even if it feels like sailing against the wind.
If you know how to efficiently fine-tune LLMs and your competitors don’t, you’ll win!
Weekly Schedule
I will continue with two new articles and two new AI notebooks every week, plus The Weekly Kaitchup every Friday. There may be a slight schedule adjustment for the Thursday issues. I am considering experimenting with sending them on Wednesdays, as they consistently underperform compared to the Monday issues.
I’ll maintain the same schedule for The Salt, my other newsletter, with The Weekly Salt on Tuesdays and monthly deep dives.
LLMs on a Budget
In 2025, I will also publish my first book, which many of you have already purchased during the pre-sale (still ongoing). Thank you so much for your support! I’ve already released two chapters: Parameter-Efficient Fine-Tuning and Prepare Your Training Dataset. The next chapter, scheduled for release at the end of January, will cover LLM Quantization. It will explore the strengths and weaknesses of major quantization algorithms and provide guidance on when to use each one. The book is still available for pre-sale with a 35% discount.
The Kaitchup Pro and AI Toolboxes
The Kaitchup Pro has been a tremendous success, especially since I revised the offering in November. Thanks to Pro subscribers, I can invest much more in research to publish exclusive models and results.
For Pro subscribers, I have some exciting plans for the upcoming months. In February, I will release new AI toolboxes, including a notebook collection for building RAG (Retrieval-Augmented Generation) systems—both simple and advanced setups—and incorporating fine-tuning and quantization techniques to improve performance. I’ll also release a toolbox implementing Minivoc, my method for reducing the vocabulary size of LLMs. If you’re not a Pro subscriber, you’ll still have the opportunity to purchase these toolboxes individually.
Pro subscribers will also receive early access to new research articles. The first article of this kind introduced Minivoc, which significantly reduces fine-tuning costs by shrinking input/output embeddings. The next research article, scheduled for March, will demonstrate how to create a state-of-the-art 2-bit model that performs as well as a 16-bit model while being six times smaller. I’ll do this with Qwen2.5 72B, and maybe newer LLMs that will be released while I’m working on this.
More toolboxes and research articles will follow throughout the year.
We’re all anticipating the release of Llama 4 and Qwen3 in the coming months. If you’ve already purchased the Llama 3 and Qwen2.5 toolboxes, they will include support for these new state-of-the-art LLMs at no additional cost. However, I plan to raise the prices of these toolboxes by approximately 20% once support for Llama 4 and Qwen3 is added. If you’re interested in these toolboxes, now is a great time to purchase them before the price increases.
Here’s to an exciting year of growth, learning, and innovation in AI. Thank you for your continued support—I can’t wait to share what’s coming in 2025!
Smolagents: Easy Agentic AI
Agents let LLMs do more than just generate text: they give LLMs the ability to take action, make decisions, and interact with the world in meaningful ways.
This could mean calling APIs, running specific tools, or even managing multi-step workflows. Essentially, an agent is a program where the LLM isn't just passively providing text. It's actively determining and controlling what happens next. This is useful when tasks don’t have a predictable, step-by-step solution. For example, planning a trip that involves weather, scheduling, and travel logistics needs this kind of flexibility.
Smolagents by Hugging Face is a new lightweight framework that makes creating these agentic workflows simple and practical. The idea is to strip away unnecessary complexity. Let’s say you want to build an agent that can calculate travel times between locations.
With Smolagents it’s so simple that I can quickly show you how it works. You’d start by defining a tool as a simple Python function:
from smolagents import CodeAgent, HfApiModel, tool
@tool
def get_travel_time(start: str, destination: str) -> str:
"""Calculate travel time between two locations."""
if start == "Eiffel Tower" and destination == "Louvre":
return "15 minutes by car"
return "Unknown travel time"Once you’ve defined your tool, you create an agent by connecting it to an LLM. The LLM acts as the decision engine, deciding when and how to use the tool based on user queries:
agent = CodeAgent(
tools=[get_travel_time],
model=HfApiModel() # Uses a Hugging Face-hosted LLM
)
response = agent.run("How long does it take to go from the Eiffel Tower to the Louvre?")
print(response)Here, the agent dynamically decides to call the get_travel_time tool based on the query. This is much more straightforward than fine-tuning an LLM for function-calling, as we did in this article:

The value of agents like this becomes clear in scenarios where predefined workflows fall short. If your task is straightforward, say, sorting requests into a few categories, you’re better off just coding it directly without agents. But for more open-ended tasks, like handling dynamic customer requests or orchestrating multiple APIs to solve a problem, agents shine. Smolagents makes it easy to build these systems without adding unnecessary complexity.
I’ll cover smolagents more extensively this month, in a dedicated article. Stay tuned!
Bamba: Why I’m Losing Faith in Transformer Alternatives
In mid-December, IBM and collaborators released a new base model built on the Mamba 2 architecture, pre-trained on open data:
Hugging Face collection: Bamba
Bamba is an advanced hybrid architecture that aims to handle very long sequences more efficiently by relying less on the attention mechanism thanks to state space models (SSMs). This is part of a broader trend where models claim breakthroughs by either ditching attention altogether or blending it with SSMs. RWKV is another example of such an approach.
With Bamba, we now have a new pre-trained hybrid model, but when it comes to performance, it’s hard to find much to get excited about:
It significantly underperforms state-of-the-art models like Qwen2.5 7B, despite being larger at 9B parameters.
SSM-based models, like Bamba, remain difficult to integrate into workflows due to poor support in most deep learning frameworks. Quantization and LoRA fine-tuning remain difficult.


These low performances are often justified by the fact that the models are trained on fewer tokens. This is true but, on the other hand, we don’t seem to know how to efficiently train SSMs. They will likely always be trained on fewer tokens than standard Transformers and thus underperform.
Nonetheless, Bamba is a great work with many cool features, like other SSM-based models. Check it out.
Meanwhile, work on optimizing Transformers for long contexts continues to accelerate. Recent advances, such as those from Unsloth and TGI, have made Transformer inference for long sequences much more efficient—not just through neural architecture improvements but also via optimization at the framework level. These efforts are closing the gap in areas where SSM architectures were supposed to excel.
As it stands, the benefits of inference-efficient architectures like Mamba are becoming harder to justify. At the same time, the top-performing models continue to be purely Transformer-based, and the dominance of Transformers as the go-to architecture remains unchallenged.
Looking ahead to 2025: I predict that the efficiency gap between Transformers and SSMs will shrink even further, and Transformers will remain the foundation of state-of-the-art language models.
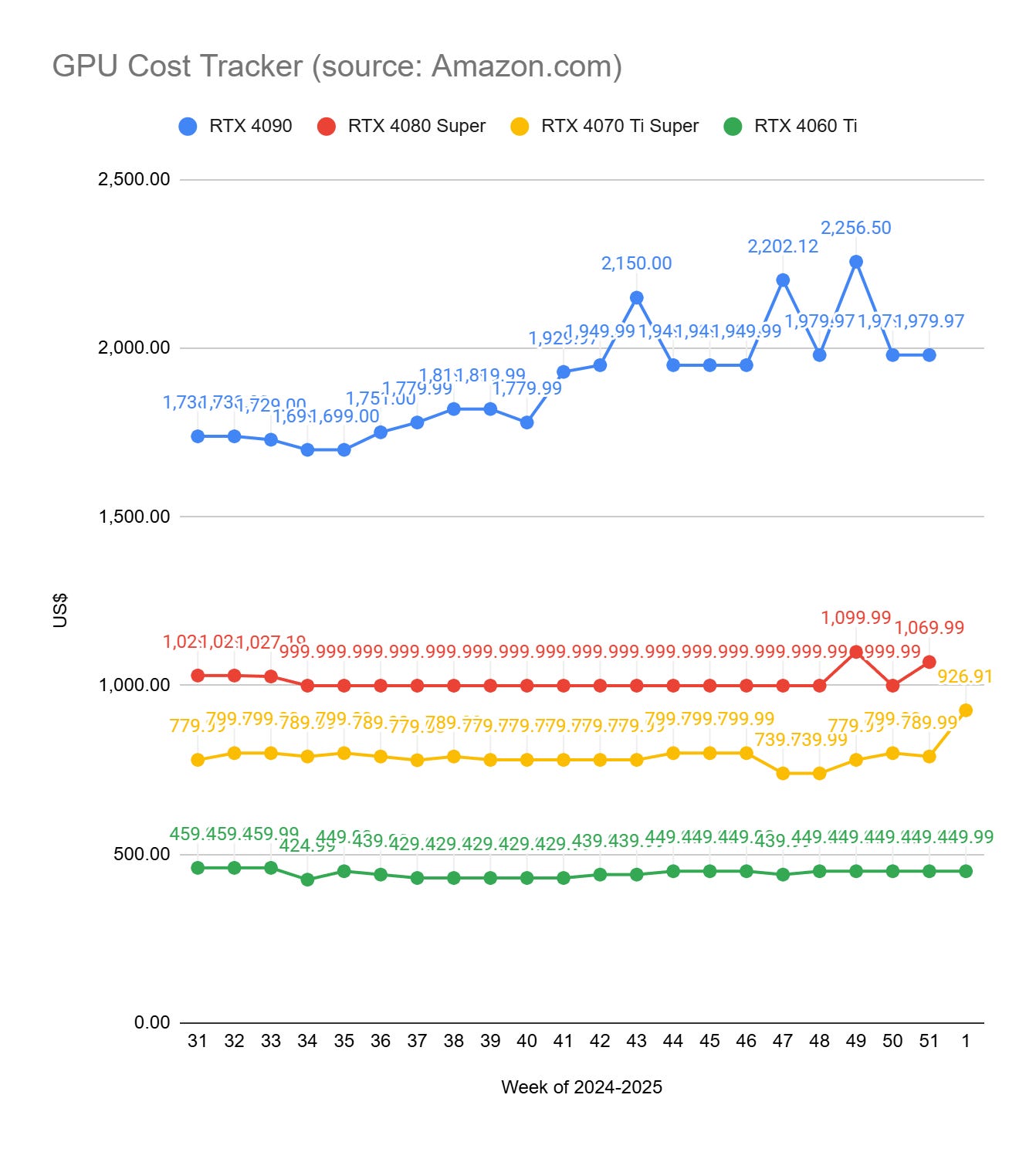
GPU Selection of the Week:
To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
We are moving towards a shortage of RTX 4080/4090 it seems. I couldn’t find RTX 4080 and 4090 reasonably priced on Amazon this week. I don’t follow much what’s happening with the RTX 5090 but it’s possible that sellers want to create demand for high-end GPUs… The RTX 5090 is expected this month.
RTX 4090 (24 GB): None
RTX 4080 SUPER (16 GB): None
RTX 4070 Ti SUPER (16 GB): MSI Gaming RTX 4070 Ti Super 16G Ventus 2X OC Graphics Card (NVIDIA RTX 4070 Ti Super
RTX 4060 Ti (16 GB): Asus Dual GeForce RTX™ 4060 Ti EVO OC Edition 16GB

The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

⭐Token-Budget-Aware LLM Reasoning
ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
Safeguard Fine-Tuned LLMs Through Pre- and Post-Tuning Model Merging
Support The Kaitchup by becoming a Pro subscriber:
What You'll Get
Priority Support – Fast, dedicated assistance whenever you need it to fine-tune or optimize your LLM/VLM. I answer all your questions!
Lifetime Access to All the AI Toolboxes – Repositories containing Jupyter notebooks optimized for LLMs and providing implementation examples of AI applications.
Full Access to The Salt – Dive deeper into exclusive research content. Already a paid subscriber to The Salt? You’ll be refunded for the unused time!
Early Access to Research – Be the first to access groundbreaking studies and models by The Kaitchup.
30% Discount for Group Subscriptions – Perfect for teams and collaborators.
The Kaitchup’s Book – A comprehensive guide to LLM fine-tuning. Already bought it? You’ll be fully refunded!
All Benefits from Regular Kaitchup Subscriptions – Everything you already love, plus more. Already a paid subscriber? You’ll be refunded for the unused time!
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!
Thanks for your plan of still covering finetuning !!