


The Weekly Kaitchup #69
OLMo 2 and Tulu 3 Quantized - QwQ - SmolVLM - Evaluation


Hi Everyone,
In this edition of The Weekly Kaitchup:
OLMo 2 and Tulu 3 Quantized
QwQ: What Is This?
SmolVLM: A Very Efficient VLM
Run Your Own Evaluation, Always
For Black Friday, I’m offering a 30% discount on the yearly subscription to The Kaitchup and The Kaitchup Pro ($250 instead of $300):
These discounts are available until Sunday, December 1st.
The Kaitchup’s Book: LLMs on Budget
The second chapter, “Prepare Your Training Dataset”, of The Kaitchup’s book will be published this weekend. You will receive it by email. If you haven’t purchased the book yet, the 30% discount is still available:
OLMo 2 and Tulu 3 Quantized
Monday, I published a cheap quantization recipe that can accurately quantize large models:

In this article, I applied it to Qwen2.5 72B. This week, I also wanted to check whether it can be applied to other models of the same size and smaller models.
For these experiments, I used the Tulu 3 and OLMo 2 models freshly released by AI2.
My results:


Conclusion: At least according to MMLU, the quantization can be very accurate even for smaller models. Moreover, while some recent work claimed that models trained on many trillions of tokens are harder to quantize, I (and Intel) don’t have this observation when using AutoRound. Tulu 3 70B, which is based on Llama 3.1 70B that has been trained on 16T tokens, can be accurately quantized.
All these new quantized models are available here (Apache 2.0 license):
Hugging Face Collection: Tulu 3 and OLMo 2 Quantized
The accuracy of the quantized model can significantly vary depending on the task and language. I recommend evaluating the models before using them in your products.
Note: I had more difficulties quantizing Tulu 3 8B. As shown in the results, there is a noticeable drop in accuracy compared to the original model. Moreover, my first quantization failed. I used float16 which is recommended by Intel for AutoRound since the quantization kernels use this data type. I got better results when keeping the original data type (bfloat16). However, it means that the model may not correctly behave in some tasks.
Tulu 3 and OLMo 2 are very interesting models using a new approach for post-training. I’ll review them in a new article for The Salt that I’ll publish soon!

QwQ: What Is This?
We don’t know.
The Qwen team has released this new model without disclosing much about it, except a very philosophical blog post:
QwQ: Reflect Deeply on the Boundaries of the Unknown
This preview model tells us that the Qwen team (Alibaba) is actively working on an open alternative to OpenAI’s o1, which exploits inference time to self-instruct and better answer the user prompt. It means that the model will try to reason before answering.
The benchmark results they published for this “preview” are impressive:
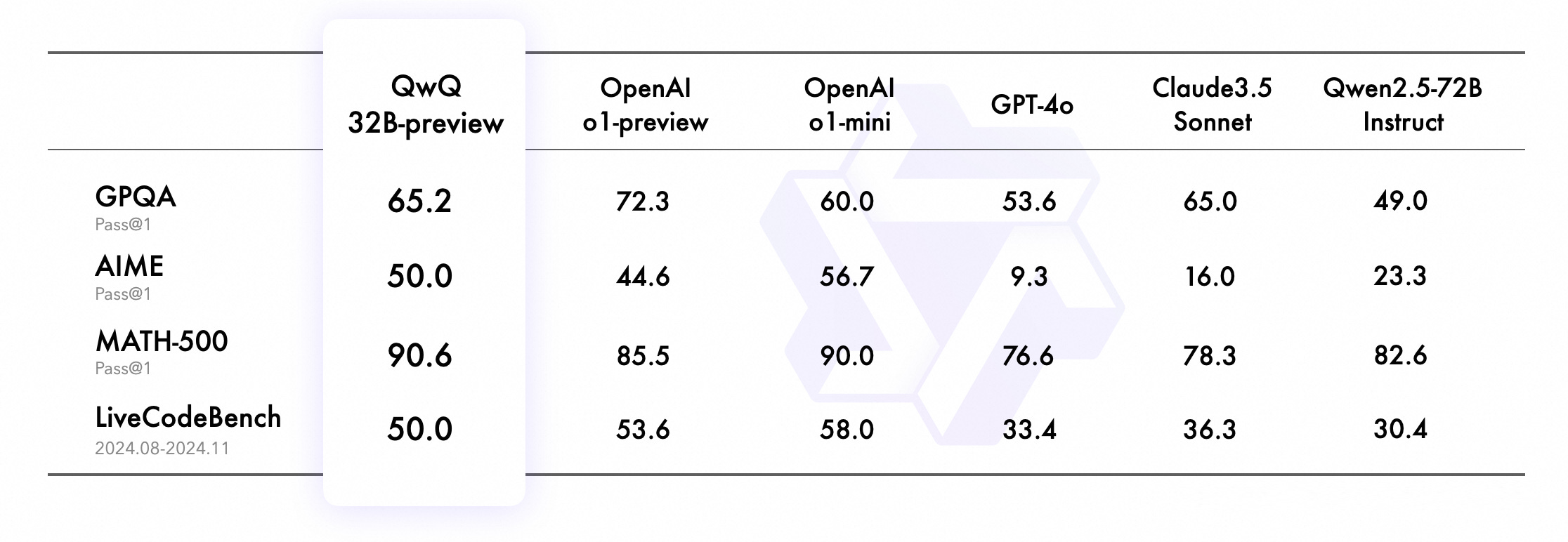
However, as the Qwen team acknowledged, the model can significantly underperform in certain tasks where standard models typically succeed.
The model uses the same architecture as Qwen2. You can also try it here:
It looks promising and since they have published this, they are probably already validating internally a much better version.
SmolVLM: A Very Efficient VLM
SmolVLM is a family of compact vision-language models (VLM) by Hugging Face designed for local deployment and commercial use. It includes three variants: SmolVLM-Base for fine-tuning, SmolVLM-Synthetic fine-tuned on synthetic data, and SmolVLM-Instruct, which is ready for interactive applications. These models are open-source and compatible with Hugging Face’s transformers library.
Hugging Face Collection: SmolVLM (Apache 2.0 license)
The development builds on previous work, such as Idefics3 from which it borrows the architecture:

SmolVLM is built for efficiency, with a lightweight architecture that uses less GPU memory and achieves faster throughput than other models like Qwen2-VL and Pixtral.
It uses a pixel shuffle strategy that compresses visual data significantly, allowing the model to handle images and text prompts with fewer tokens. It makes the models much easier to run locally.

source: SmolVLM - small yet mighty Vision Language Model
If you want to fine-tune VLMs, have a look at this tutorial that I published this week:

Run Your Own Evaluation, Always
Let’s take these numbers published by NVIDIA:

Focus on the results of SmolLM2 for HellaSwag (0-shot). It has a score of 53.55.
Now, let’s have a look at the results published by Hugging Face:

SmolLM2 for HellaSwag (also 0-shot) has a score of 68.7. This is 15.2 points more than the result published by NVIDIA, for the same model and the same (?) benchmark. Note: This was originally reported by zealandic1 on X.
How can the results be so different? I don’t know. There can be many explanations for this: different batch sizes (yes, the batch size changes the results), reporting "acc" score instead of "acc_norm", different evaluation datasets (maybe HF or NVIDIA removed some samples…), … Both numbers could be correct. Both numbers are definitely not comparable.
Why do I bring this up?
To emphasize the importance of conducting your own evaluations. In the research papers I review for conferences (NeurIPS, ICLR, ACL, etc.), I often see authors simply copying numbers from various sources and directly comparing them without questioning whether those numbers are truly comparable. In many cases, they are not.
For example, in the tables above, Hymba appears to outperform SmolLM2 based on NVIDIA's evaluation. However, if we were to naively compare Hymba’s numbers from NVIDIA's table with those published by Hugging Face for SmolLM2, we might mistakenly conclude that SmolLM2 performs better. This highlights the need for careful, context-aware evaluation rather than comparing copied numbers from different studies.
Note: I have no idea how Hugging Face obtained these results. I computed the score for HellaSwag for confirmation and I got the same numbers published by NVIDIA.
I wrote about this kind of evaluation issue in The Salt. I’m also writing a tutorial on how to spot questionable evaluations. I’ll probably publish it next month.
GPU Selection of the Week:
To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
RTX 4090 (24 GB): ASUS TUF Gaming GeForce RTX™ 4090 OG OC
RTX 4080 SUPER (16 GB): GIGABYTE GeForce RTX 4080 Super WINDFORCE V2
RTX 4070 Ti SUPER (16 GB): MSI GeForce RTX 4070 Ti Super 16G Ventus 3X Black OC
RTX 4060 Ti (16 GB): PNY GeForce RTX™ 4060 Ti 16GB Verto™
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week, I reviewed:

⭐Hymba: A Hybrid-head Architecture for Small Language Models
When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training
LLaVA-o1: Let Vision Language Models Reason Step-by-Step
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!