


The Weekly Kaitchup #45
RecurrentGemma 9B - Spectrum - Samba


Hi Everyone,
In this edition of The Weekly Kaitchup:
RecurrentGemma 9B: Larger and Faster than Gemma 7B
Spectrum: Fine-tune Only the Most Important Parameters
Samba: Better than Transformer and with Unlimited Context?
The Kaitchup has 3,965 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (70+) and more than 100 articles.
AI Notebooks and Articles Published this Week by The Kaitchup


Notebook: #78 Qwen2 QLoRA Fine-tuning and Quantization
RecurrentGemma 9B: Larger and Faster than Gemma 7B
Almost two months ago, Google released RecurrentGemma 2B, a version of Gemma using the Griffin architecture:
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Griffin is significantly faster than a standard transformer thanks to a local computation of the attention. Like other alternatives to Transformer, such as RWKV and Jamba, the goal is to accelerate inference while keeping the same efficiency as the transformer for training.


RecurrentGemma 9B is significantly faster than Gemma 7B for inference:

While Gemma 7B, a standard transformer model, rapidly becomes inefficient as the sequence grows, RecurrentGemma-9B inference throughput remains the same from 128 to 4,096 tokens.
As for the accuracy of RecurrentGemma-9B in downstream tasks, it is very similar to Gemma 7B. However, Gemma 7B, which is an 8.5B parameter model (and not 7B…), has 1.1B parameters less than RecurrentGemma-9B. Gemma 7B consumes less memory for short sequences but with much larger sequences, due to a growing KV cache, Gemma 7B will consume more memory than RecurrentGemma 9B.
The base and instruct versions are available on the HF Hub:
Spectrum: Fine-tune Only the Most Important Parameters
Spectrum is a new parameter-efficient fine-tuning (PEFT) method that only updates the layers with the highest signal-to-noise ratio (SNR). In other words, it concentrates fine-tuning on the most informative parts of the model.
Spectrum: Targeted Training on Signal to Noise Ratio
This is different from the popular LoRA and QLoRA since these PEFT methods freeze the entire model and fine-tune an adapter on top of it.

Spectrum can actually be used in combination with LoRA, i.e., fine-tuning an adapter on top of a partially frozen LLM.
Experimenting with Llama 3 8B, the authors found that their method performs closely to full fine-tuning:

Using a single GPU, Spectrum is faster and more memory-efficient than full fine-tuning:
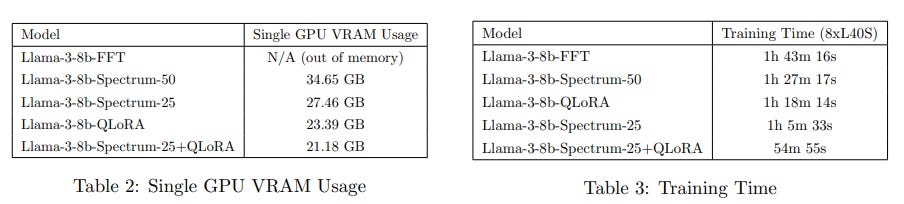
However, when combined with QLoRA, Spectrum tends to underperform standard QLoRA alone:

I assume that when QLoRA is activated with Spectrum, the model has much less capacity to learn with less trainable parameters, hence the degradation of the results.
They released their code:
GitHub: cognitivecomputations/spectrum
Samba: Better than Transformer and with Unlimited Context?
After Jamba and Zamba, we now have Samba!
Proposed by Microsoft, this is yet another LLM with a hybrid architecture state-space/transformer.
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
Samba layers combine MLPs, Mamba (state-space layers), and a sliding window attention.

Thanks to the use of Mamba modules, Samba is much faster for inference (3.6x faster than Llama 3 for a sequence of 64k tokens) and also much better at remembering long context. Even more remarkable, while fine-tuned on 4k sequences, Samba achieves a perfect score on the Passkey Retrieval benchmark for sequences of 256k tokens. It seems that Samba context length can be easily extended without any performance degradation.

Samba also seems to largely outperform Phi-3 mini while being of the same size:

They mentioned that they used the same training recipe internally provided by the Phi team (a distinct Microsoft team it seems). They don’t mention what is a “recipe”. I hope it includes the training data because if it does, it would mean that Samba outperforms Phi-3 while using the same training data. Otherwise, the improvement observed for Samba could just be due to the use of potentially better training data than the data used to train Phi3.
Microsoft shared the training code (a rarity in the world of LLMs):
GitHub: microsoft/Samba
The models are not yet released but they are planning to release them. However, similar to Jamba and Zamba, there is a risk that this model won’t be largely adopted, despite its obvious advantages, due to poor support by the main frameworks used for LLMs (vLLM, Transformers, PEFT, bitsandbytes, AutoGPTQ, … none of them fully support state-pace models, e.g., quantization won’t work, or LoRA, or gradient checkpointing, etc.).
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) and articles I have checked and updated, with a brief description of what I have done.
AutoAWQ now supports Phi-3. This is good news since AWQ is one of the most accurate 4-bit quantization methods. I added the code for the AWQ quantization of Phi-3 Medium in this notebook:
#75 Fine-tune Phi-3 Medium on Your Computer -- With Code to Merge Adapters
I also released the quantized models on the Hugging Face Hub. Currently, Phi-3 Medium quantized with AWQ is only proposed by The Kaitchup:
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed the technical report detailing the creation of FineWeb and FineWeb-Edu by Hugging Face. They also released a lot of useful resources to extract high-quality datasets.

This week in the Salt, I briefly reviewed:
Self-Improving Robust Preference Optimization
⭐Mixture-of-Agents Enhances Large Language Model Capabilities
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!