


The Weekly Kaitchup #37
Llama 3 - Mixtral-8x22B - Megalodon - WizardLM-2


Hi Everyone,
We got a lot of new LLMs this week!
In this edition of The Weekly Kaitchup:
Llama 3
Mixtral-8x22B and Mixtral-8x22B-instruct
Megalodon: Yet Another Method for Transformers with Unlimited Context
WizardLM-2: 70B and 7B Open LLMs
The Kaitchup has now 3,040 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (60+) and more than 100 articles.
Llama 3
Meta released two Llama 3 models and their instruct variants:
The main difference with Llama 2:
4x larger vocabulary (128k against 32k)
Trained on 15T tokens, i.e., 7.5 times more than Llama 2
Twice larger context size (8k against 4k; I think this is still quite small but Meta mentioned that they will release versions with extended context later)
Group-query attention (GQA) for both models (Llama 2 only applied GQA for the 70B model)
Much better performance overall
According to the evaluation conducted by Meta, Llama 3 8B is the new best open LLM of this size by a large margin.

The 70B model seems better than Claude and Gemini-1.5 Pro:

They don’t show any comparison with GPT-4.
They are also training a much larger model with more than 400B parameters. I guess they will train it until it becomes better than GPT-4.
Similar to Llama 2, Llama 3 is not fully open. We are not allowed to use Llama 3 to develop LLMs that are not based on Llama 3:
You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
You can find more information about Llama 3 here:
Introducing Meta Llama 3: The most capable openly available LLM to date
I’ll propose tutorials based on Llama 3 from next week!
Mixtral-8x22B and Mixtral-8x22B-instruct
Last week, Mistral AI released Mixtral-8x22B, a new mixture-of-experts (MoE) model very similar to Mixtral-8x7B but with 141B parameters.

As usual, they released it with a magnet link and the model had to be converted by the community to be compatible with most deep learning frameworks.
Mixtral-8x22B is now officially released in Mistral AI’s Hugging Face space and fully compatible with most frameworks that were already supporting Mixtral-8x7B. They also released an instruct version and published some details on the models’ performance.

With Command R+, DBRX, and Mixtral-8x22B, we got very good but huge models with over 100B parameters. Can you run or fine-tune them on your machine? Next week, I’ll show you how to estimate the memory consumption of such models without downloading them.
Megalodon: Yet Another Method for Transformers with Unlimited Context
There are so many methods to extend the context length of transformers that it became almost impossible to keep track of all of them. In The Salt, I reviewed LongRoPE which claims to support contexts of 2 million tokens. Microsoft planned to release the code but the GitHub is still 404 (as of the 16th of April).

Megalodon is yet another new method proposed by Meta and the University of Southern California that promises to break the context limit of transformers.
MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length
I found this method quite complex. It relies on complex exponential moving average and timestep normalization layers which were both unknown to me.

The method seems to perform very well against vanilla Llama 2 and learns more efficiently but we lack comparisons with other methods extending context length.

They also compared Megalodon with attention-free architectures such as RWKV and Mamba:

Megalodon is better but trained on many more tokens than Mamba and RWKV. I would be curious to know how well it performs against the most recent checkpoints of RWKV.
Similar to LongRoPE, they published the paper before the code. The repository also yields a 404 error.
WizardLM-2: 70B and 7B Open LLMs
Microsoft AI released WizardLM-2 models. A new family of LLMs comprising 7B, 70B, and a mixture of experts 8x22B models.
These models have the particularity that they have been only trained on synthetic data generated by other models. The training itself was also supervised by AI models:
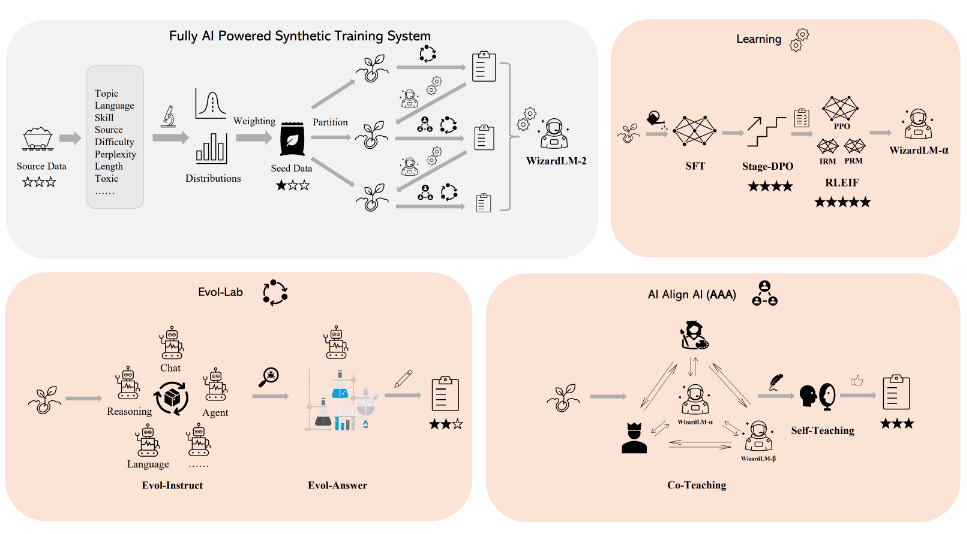
This is a very complex pipeline. The “learning” involves a supervised fine-tuning (SFT) phase and stage-DPO (never heard of this before), followed by RLHF’s PPO with the particularity that no humans have been involved to train the reward models.
It yields models among the best in their category (well, it was before the release of Llama 3…):
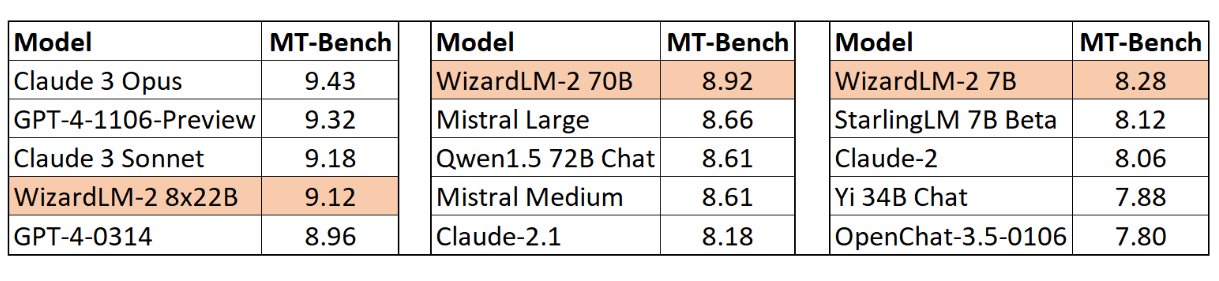
The models are fully open (Apache 2.0 license). They are (were…) available on the Hugging Face hub:
Note: The 70B version will be released later.
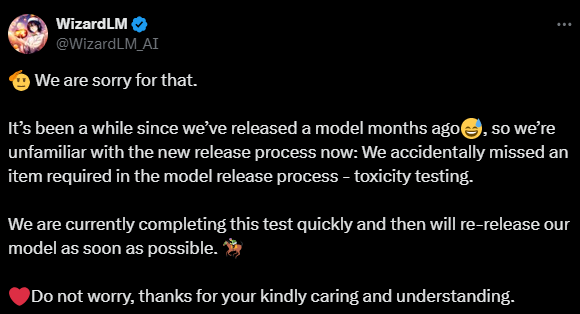
Update: The WizardLM-2 LLMs have been removed by Microsoft. The authors forgot to run some toxicity benchmarks which seem to be an internal requirement by Microsoft before releasing LLMs. They should be back online soon (unless they discover that the models are toxic I guess…)
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) I have checked and updated, with a brief description of what I have done.
This week, I have checked and updated the following notebook:
#14 Merge LoRA Adapters with LLMs the right way
The notebook shows how to merge QLoRA adapters into the base model while preserving most of its performance.
The dequantization, a critical step before merging, wasn’t working anymore. I fixed all the bugs. It can also be used for all models supported by Hugging Face’s AutoModelForCausalLM, i.e., the large majority of the LLMs. For consistency, the notebook now uses the same torch_dtype for all the evaluations.
I have updated the related article to reflect these changes:

The Salt
The Salt is my other newsletter that takes a more scientific approach. In it, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week in the Salt, I briefly reviewed:
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Dataset Reset Policy Optimization for RLHF
⭐Rho-1: Not All Tokens Are What You Need
⭐LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!
Thanks for the update. What do you think the right pad/unk token we should use for llama3?
Nice weekly summary. Just some comments/Qs on your notebook 14:
1. Do you have a reference for the dequanting code? Or, did you have to develop it from scratch?
2. I notice this line in the dequanting function:
```
def dequantize_model(model, to='./dequantized_model', dtype=torch.float16, device="cuda"):
"""
'model': the peftmodel you loaded with qlora.
```
When you say 'model', do you in fact mean the base model OR the peftmodel? It seems to me the dequanting function expects a base model (but maybe it works with a peft model too?)
3. The dequantization and merging cell doesn't specify an adapter as an input (so I assume the adapter has been specified earlier in the code). I wonder if it would be better to explicitly set (or reset) the adapter in that cell, to make things more clear?