


The Weekly Kaitchup #3
AutoGPTQ in HF transformers - More long-context LLMs - Survey on compression techniques

Hi Everyone,
This week has been quieter than usual with only a few new models, announcements, and research papers that I’ve noticed.
But I’m very excited by the integration of AutoGPTQ into Hugging Face’s transformers that was released this week. Now, you can directly load GPTQ quantized models from the HF Hub with transformers. I think this is a game-changer for affordable AI as it greatly improves the accessibility of quantized models.
I’m writing a tutorial on how to use GPTQ models directly with HF transformers for inference and fine-tuning (with PEFT). I’m also benchmarking it on affordable GPUs. Expect it next week in your mailbox!
From next week, I will start publishing a series of articles showing how to train an RLHF model on your computer with DeepSpeed-Chat. It’s complicated but I’ll try to make it simple. The first article of this series will be free, while the following ones will be accessible only to paid subscribers. If you are a free subscriber, consider upgrading to paid. There is a 7-day free trial:
The Kaitchup has now 347 subscribers!
Thank you for your support!
In The Weekly Kaitchup, I briefly comment on recent scientific papers, new frameworks, tips, open models/datasets, etc. for affordable and computationally efficient AI.
AutoGPTQ with Hugging Face’s transformers
As I wrote in the introduction, I think this is a game-changer considering the huge number of models already quantized and freely available on the Hugging Face Hub.
I’ll publish a detailed tutorial on how to use it. Meanwhile, here is the piece of code that will load a GPTQ quantized model on your computer:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("kaitchup/llama-2-7b-4bit-autogptq", device_map="auto")That’s extremely simple! Quantized models are loaded as simply as standard models.
This integration of GPTQ into transformers was announced 1 day after I finished writing my article comparing GPTQ and bitsandbytes. I updated the article yesterday (just to add a note about it).

Giraffe — Long context open-source LLMs
Abacus.ai released new models greatly extending the context length of Llama 2 to 32k tokens. That’s 30k tokens longer than the original model. Their approach is explained in this paper: “Giraffe: Adventures in Expanding Context Lengths in LLMs”.
If you want to read a shorter and more accessible version of their work, I recommend reading their blog post. I like how they simply explain the scalability problem of the Transformer with a long context:
Why can’t we just train the model on longer contexts though? The primary reason for this is that a key component of modern LLM architecture – called self-attention – scales quadratically in both memory and compute as context length increases, so there will quickly be a point where you don’t have sufficient GPUs, time or money to train for longer contexts. Hence having a method that can zero-shot extrapolate to context lengths never seen before is key.
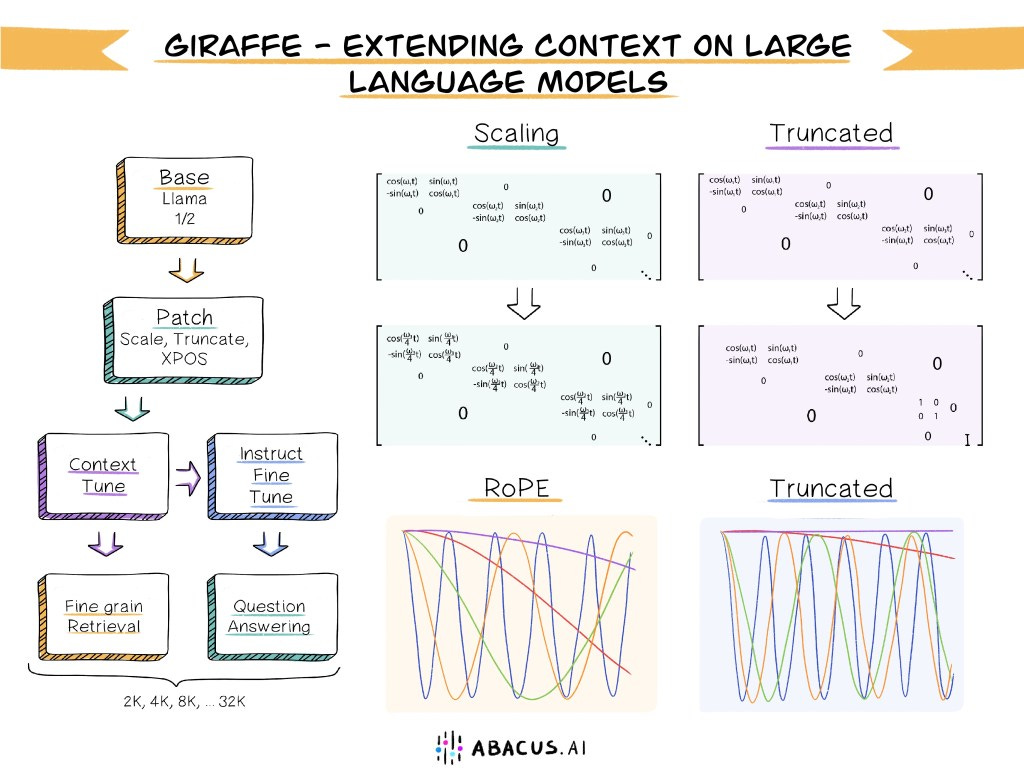
You can see this work as a survey comparing existing techniques and highlighting their advantages/disadvantages. They also propose a new “truncation“ method that seems promising.
The Giraffe models are available on the Hugging Face Hub. The 32k Giraffe, based on Llama 2 13b, is here.
In the previous edition of The Weekly Kaitchup, I wrote about Unlimiformer, a wrapper giving unlimited context length to LLM. I wonder how this compares to the approaches studied by Abacus.ai.

Survey on Compression Techniques
I wrote several articles in The Kaitchup about LLM quantization but quantization methods are not the only ones that can reduce model size. We have:
Quantization
Pruning
Low-rank factorization
Knowledge distillation
Zhu et al. wrote a survey explaining these methods.

If you haven’t read my articles applying quantization to LLMs for fine-tuning and inference, I recommend the following ones:


Further Reading: Flash Attention
This week I finally found the time to learn about FlashAttention. I recommend this article by Aleksa Gordić (DeepMind):
It’s a very accessible explanation showing why Flash Attention is much more computationally efficient than the original Transformer Attention. Aleksa introduces the article this way:
[…] explain flash attention in such a way that hopefully anyone who already understands attention will ask themselves:
“Why didn’t I think of this before?” followed by “It’s so easy”.
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!