


The Weekly Kaitchup #28
SPIN - MoE with LoRAs - AQLM


Hi Everyone,
In this edition of The Weekly Kaitchup:
SPIN: The Framework
Make a Cheap MoE with LoRA Experts
AQLM: 2-bit and 3-bit LLMs Getting More Accurate
The Kaitchup has now 2,036 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
SPIN: The Framework
In The Weekly Kaitchup #22, I presented SPIN: A framework for fine-tuning an LLM using self-generated data. Since then, there have been similar ideas on arXiv, such as the self-rewarding language model by Meta.
However, until now we only had papers and no concrete examples of self-trained LLMs or frameworks. This is not the case anymore as the authors of SPIN released their framework with several checkpoints of SPIN applied to zephyr.
GitHub: uclaml/SPIN (Apache 2.0 license)
The improvements after several SPIN iterations are significant:

I’ll test the framework to find whether we can use it with QLoRA. Note: The examples in the GitHub repository seem to fully fine-tune Zephyr which wouldn’t be possible on consumer hardware. Nonetheless, it seems that they based their code on Hugging Face’s TRL so using QLoRA should be straightforward.

Make a Cheap MoE with LoRA Experts
This paper introduces Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE), a new approach to enable zero-shot generalization by exploiting a set of specialized PEFT modules such as LoRA adapters:
Learning to Route Among Specialized Experts for Zero-Shot Generalization
The method freezes the entire model, including PEFT modules, and trains a gate for each module akin to the route network used in mixture of expert (MoE) models. You can see this method as a cheap way to create an MoE model in which each expert is a LoRA adapter.

This gate training is computationally light and improves the model's ability to handle tasks it wasn't explicitly trained on by using a top-k routing strategy for token distribution during inference.
The effectiveness of PHATGOOSE was tested on T5-family models, showing superior performance in zero-shot generalization on standard benchmarks compared to previous methods that merged experts or relied on a single PEFT module. It also sometimes outperformed explicit multitask training.
The code is available:
GitHub: r-three/phatgoose (it seems to work only with the T5 architecture)
AQLM: 2-bit and 3-bit LLMs Getting More Accurate
New quantization algorithms are published every week. The improvements are regular, and now 4-bit quantization is almost lossless for the largest LLMs.

However, using lower precision such as 2-bit and 3-bit tends to significantly degrade the performance of the model. AQLM is a new method that achieves significant progress for 2-bit and 3-bit quantization.
Extreme Compression of Large Language Models via Additive Quantization
[It] generalizes the classic Additive Quantization (AQ) approach for information retrieval to advance the state-of-the-art in LLM compression, via two innovations: 1) learned additive quantization of weight matrices in input-adaptive fashion, and 2) joint optimization of codebook parameters across entire layer blocks. Broadly, AQLM is the first scheme that is Pareto optimal in terms of accuracy-vs-model-size when compressing to less than 3 bits per parameter, and significantly improves upon all known schemes in the extreme compression (2bit) regime.
It is a very different approach from previous work such as GPTQ, AWQ, or SqueezeLLM.

This is what they mean by “Pareto optimal”:
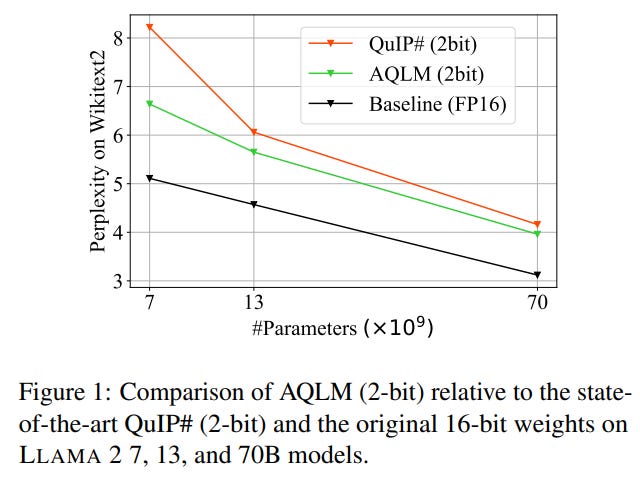
Llama 2 70B quantized to 2-bit with AQLM is better than the original Llama 2 13B. It is also smaller: Llama 2 70B 2-bit would roughly occupy 20 GB in memory while Llama 2 13B occupies 26 GB.
They have released their code here:
GitHub: Vahe1994/AQLM
The Salt
In case you missed them, I published two new articles in The Salt this week:

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!