


Llama 2 MT: Turn Llama 2 into a Translation System with QLoRA
How to Fine-tune a Cheap Translation Model


Llama 2 is a pre-trained large language model (LLM) that can be fine-tuned for various tasks. It was mainly pre-trained on English text and Meta has classified uses in other languages as “out-of-scope”.
Among tasks involving other languages, we have language translation. The pre-trained and chat versions of Llama 2 may generate somewhat understandable translations but with a quality far from the state of the art. The chat version may also refuse to translate text that it judges too political, harmful, etc. For instance, in some preliminary experiments that I ran, Llama 2 7B Chat refused to translate several sentences from the WMT translation benchmarks that are widely used to evaluate machine translation systems.
In this article, I show how you can quickly turn Llama 2 into an accurate machine translation system using consumer hardware. I use QLoRA, with Hugging Face’s TRL, to fine-tune LoRA on top of a quantized Llama 2.
The code to reproduce my experiments is given in the following sections. I have also implemented a notebook for fine-tuning and inference that you can find here (only available for paid subscribers):
I fine-tuned Llama 2 for the translation of 11 languages into English and released the adapters on the Hugging Face Hub (MIT license):
Note: This article only tackles how to train a cheap translation model with Llama 2. If you don’t have a limited budget and are interested in fine-tuning Llama 2 for better translation quality, I recommend reading this paper:
A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models (Xu et al., 2023)
Languages and Translation Directions
Llama 2 is pre-trained in English. Its vocabulary contains 32k tokens which are mostly tokens and symbols that we can only find in languages using the Latin script.
If we fine-tune Llama 2 on text in languages using a different writing system, e.g., Hindi, Arabic, Japanese, or Chinese, most of the tokens will be UNK tokens (unknown tokens). In other words, fine-tuning Llama 2 for translating, e.g., Hindi to English, would be (almost) equivalent to fine-tuning Llama 2 for translating sequences of unknown tokens into English.
We can’t fine-tune Llama 2 on languages using other writing systems without extending its vocabulary which poses several challenges that we won’t tackle here.
For this article, I only consider languages using the Latin script: Czech, Danish, Dutch, English, Finnish, French, German, Indonesian, Italian, Norwegian, Swedish, and Vietnamese.
Moreover, since Llama 2 is pre-trained to generate English, I only considered fine-tuning Llama 2 to translate into English. In preliminary experiments, I tried some reverse directions, for instance, English to French, but I judged that the translation quality I obtained wasn’t good enough.
Pre-processing the Training Data
We need a translation dataset to fine-tune Llama 2 for translation. There are plenty of public datasets that you can use in different domains and languages. You can find most of them on OPUS.
However, since I will use Hugging Face libraries, it’s more convenient to use a dataset directly hosted on the Hugging Face Hub.
I don’t target any specific domain in this article so I chose the dataset opus100.
OPUS-100 is English-centric, meaning that all training pairs include English on either the source or target side. The corpus covers 100 languages (including English).
It contains up to 1 million sentence-level translations per language pair sampled from parallel data available in OPUS. There are also 3 data splits per language pair: train, validation, and test. Each split is structured as in the example below where the sentences are translations.
Example for Danish-English:
{ "da": "Hvordan kan du være så sikker?", "en": "How can you be so sure?" }Llama 2 is a causal language model, i.e., it predicts the next tokens given the tokens in the context. The examples used for fine-tuning should be sequences of tokens.
To simplify fine-tuning, I formatted opus100 for the selected language pairs as follows:
{source} ###>{target}
For instance, the example I provided above becomes:
{"text": "Hvordan kan du være så sikker? ###>How can you be so sure?"}This is a simple single-column format that only adds a few extra tokens (‘ ###>’).
For a tiny fraction of the dataset, this format yields very long sequences. Long sequences require more memory and take more time to process. It can significantly increase fine-tuning costs just because of a few examples.
For instance, let’s say that 99.9% of our training examples are less than 100 tokens while in the remaining examples, some of them have more than 1,000 tokens. If we want to include this 0.1% of examples in the fine-tuning, we will have at least one batch of examples that will be ten times bigger in memory than the others. We don’t want these batches.
To reduce the memory consumption of the batches, I discarded all the extremely long examples.
I didn’t do any pre-processing other than that for the train split. The validation split remains the same.
The formatted and filtered datasets that I used for fine-tuning are here:
QLoRA Fine-tuning for Translation with TRL
QLoRA is a technique for fine-tuning LoRA adapters on top of a quantized model. It enables fine-tuning of LLMs with billions of parameters on consumer hardware. LoRA only fine-tunes a few parameters while the base model, Llama 2, remains frozen.
Hardware Requirements
QLoRA quantizes the model at loading time with 4-bit precision (using NormalFloat4 data type). If we fine-tune Llama 2 7B, we only need around 4 GB of VRAM to load the 4-bit model on the GPU.
I recommend using the safetensors version of Llama 2 to avoid consuming a large amount of CPU RAM when loading the model. Note: By default, Hugging Face Transformers loads the safetensors version of a model if it is available (which is the case for Llama 2).

Then, during training, adjust the training batch size and gradient accumulation steps to efficiently use the remaining VRAM.
Setting Up the Dependencies
First, we need to install all the following libraries:
pip install transformers trl datasets accelerate peft bitsandbytesThen, import the following:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
from datasets import load_dataset
from trl import SFTTrainer
import torchLoading Llama 2 7B and the Training Data
You must have a Hugging Face access token to load Llama 2. Run the following command and enter your access token (you can find it in your Hugging Face account’s settings):
huggingface-cli loginIt will save your token in your environment so that you won’t have to do it again.
For QLoRA, we must define a quantization configuration. Here I use the standard configuration: nf4 with double quantization and the float16 compute dtype (use bfloat16 instead if your GPU supports it).
model_name = "meta-llama/Llama-2-7b-hf"
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=bnb_config, device_map={"": 0})
model = prepare_model_for_kbit_training(model)And then the tokenizer:
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True, add_eos_token=True)
tokenizer.pad_token = tokenizer.unk_token
tokenizer.padding_side = "left"Llama 2 doesn’t have a padding token so I set the UNK token for padding. I also pad left since I think it makes more sense when we do language generation (but you can pad right, it doesn’t matter much).
For the training data, I uploaded preprocessed datasets on the HF hub for all translation directions that I have investigated.
For instance, for French-to-English, load the dataset as follows:
dataset = load_dataset("kaitchup/opus-French-to-English")LoRA Configuration
Finding the best hyperparameters for LoRA is difficult. There are three main hyperparameters: LoRA’s alpha, rank, and the target modules.
Using a higher rank adds more trainable parameters and thus increases the size of the adapter. I tried a lot of combinations of alpha and rank but I found that their values don’t have much impact, at least not for the first few thousand training steps. So I set alpha=rank=16.
As for the target modules, targeting all the modules of Llama 2 should provide the best results. However, it would also increase the number of trainable parameters, and consequently the required amount of VRAM. I wanted to keep the size of the adapter below 100 MB. I found that targeting 3 modules was enough to stay below this threshold so I chose: up_proj, down_proj, and gate_proj. These are also target modules that worked well in previous work such as Platypus.
Here is the LoraConfig:
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules= ["down_proj","up_proj","gate_proj"]
)It adds 23.2M trainable parameters.
If you favor performance over training efficiency, I recommend this configuration:
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules= ["q_proj","up_proj","o_proj","k_proj","down_proj","gate_proj","v_proj"]
)
It produces much bigger adapters (slightly over 600 MB) but yields better translation accuracy.
Training Hyperparameters
In my preliminary experiments, I observed that Llama 2 acquires quite good translation capabilities after only a few hundred training steps. Then, the translation quality continues to improve but very slowly.
Nonetheless, if you are chasing for the state-of-the-art you should fine-tune at least until the validation stops decreasing.
training_arguments = TrainingArguments(
output_dir="./results/",
evaluation_strategy="steps",
optim="paged_adamw_8bit",
save_steps=500,
log_level="debug",
logging_steps=500,
learning_rate=1e-4,
eval_steps=500,
fp16=True,
do_eval=True,
per_device_train_batch_size=96,
per_device_eval_batch_size=96,
#gradient_accumulation_steps=1,
warmup_steps=100,
max_steps=3000,
lr_scheduler_type="linear"
)This configuration runs on a GPU with 40 GB of VRAM, e.g., the A100 of Google Colab Pro. If you want to train on a high-end consumer GPU with 24 GB of VRAM, such as an RTX 3090/4090, change the batch sizes:
per_device_train_batch_size=48
per_device_eval_batch_size=48
gradient_accumulation_steps=2
This is equivalent to the configuration I used with the A100. The total training batch size remains 96.
Reduce the batch sizes, and proportionally increase gradient_accumulation_steps, if you have a GPU with less memory.
I stopped the training after 3,000 steps (max_steps=3000) because the translation quality was good enough for all the translation directions I tried.
Training with TRL
Set the SFTTrainer as follows, then start the training.
trainer = SFTTrainer(
model=model,
train_dataset=dataset['train'],
eval_dataset=dataset['validation'],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=120,
tokenizer=tokenizer,
args=training_arguments
)
trainer.train()To keep training efficient, I set max_seq_length=120 for all translation directions. For some of the languages, such as Finnish and Swedish, it will truncate many training examples. Increase it if you want better translations for these languages.
With the A100, training takes around 4 hours (total cost: around $5 on Google Colab). You can also use the free instance of Google Colab but it would take much more time. You would also have to restart the runtime several times since Google stops it after 12 hours (or before, if you overuse it…).
The training log should look like this:
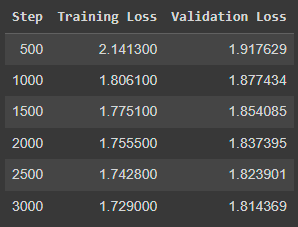
Translate with Llama 2
TRL saves a LoRA adapter. To use it, we must first load the base model, Llama 2 7B, and then load the LoRA adapter fine-tuned for translation.
For inference, you only need these libraries installed:
pip install transformers accelerate peft bitsandbytesThen, import the following:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
from peft import PeftModelLoad the base model and its tokenizer:
base_model = "meta-llama/Llama-2-7b-hf"
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
base_model, device_map={"": 0}, quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained(base_model, use_fast=True)Note: Don’t forget that you need an access token to get Llama 2 from HF’s hub.
Then, load the adapter. In this example, I load the adapter for translating French to English:
model = PeftModel.from_pretrained(model, "kaitchup/Llama-2-7b-mt-French-to-English")Everything is now ready for translation.
my_text = "Tu es le seul client du magasin."
prompt = my_text+" ###>"
tokenized_input = tokenizer(prompt, return_tensors="pt")
input_ids = tokenized_input["input_ids"].cuda()
generation_output = model.generate(
input_ids=input_ids,
num_beams=6,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=130
)
for seq in generation_output.sequences:
output = tokenizer.decode(seq, skip_special_tokens=True)
print(output.split("###>")[1].strip()) I don’t recommend any sampling during decoding. The standard beam search usually yields better results.
The variable “my_text” contains the text that we want to translate. In my example, Llama 2 translates the following French sentence:
Tu es le seul client du magasin.
into the correct English sentence:
You're the only customer in the store.
Evaluation?
I didn’t perform a rigorous scientific evaluation of the models I’ve released.
Most of the public benchmarks available for the translation directions I worked on are also part of the dataset OPUS100 that I used for fine-tuning. My models may overperform on these benchmarks simply due to data contamination. Note: I confirmed that for some translation directions, my models suspiciously reach a near-state-of-the-art performance, for instance on the FLORES datasets, despite being largely undertrained.
Even if the benchmarks weren’t in OPUS100, I cannot guarantee that they weren’t part of the unknown pre-training data used by Meta for Llama 2. Data contamination in the pre-training stage is largely understudied. I assume that for translation it would only have little impact on the evaluation results but this is only an assumption. And it might be true only for some translation directions.
These models are not intended for research or scientific purposes due to this plausible data contamination. You may evaluate them of course but I recommend using benchmarks published in 2023 (such as the WMT2023 test set for German-to-English) or doing a manual evaluation. If you use automatic metrics, don’t use legacy metrics such as BLEU which is largely inaccurate. Use COMET or BLEURT instead.

Hello thank you for all urs tutos, however i don't know if u could help me i m getting this erreor RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat2 in method wrapper_CUDA_mm) when running ur notebook !
yes sir using google colab, However i don't know how but now it's working