
Safe, Fast, and Memory Efficient Loading of LLMs with Safetensors
How to convert and run your models with safetensors


By default, PyTorch saves and loads models using Python’s pickle module. As pointed out by Python’s official documentation, pickle is not secure:
Warning The
picklemodule is not secure. Only unpickle data you trust.It is possible to construct malicious pickle data which will execute arbitrary code during unpickling. Never unpickle data that could have come from an untrusted source, or that could have been tampered with.
Not only is pickle unsafe, but manipulating large PyTorch models with it is inefficient. When you want to load models, PyTorch performs all these steps:
An empty model is created
Load in memory the model weights
Load the weights loaded at step 2 in the empty model created at step 1
Move the model obtained at step 3 on the device for inference, e.g., a GPU
By performing a copy of the model at Step 2, instead of directly loading the model in place, PyTorch needs an available memory of twice the size of the model.
There are various solutions to secure the models and efficiently load them.
In this article, I present safetensors. It’s a model format designed for secure loading whose development has been initiated by Hugging Face. In the following sections, I show you how to save, load, and convert models with safetensors. I also benchmark safetensors against PyTorch pickle using Llama 2 7B as an example.
Note: safetensors is distributed with the Apache 2.0 license.
My notebook implementing safetensors demonstrations and benchmarking with Llama 2 7B is available here:
safetensors: How does it work?

safetensors is a very simple format. As shown by the illustration above, a file serialized with safetensors has 3 segments:
a tiny segment that only indicates the size of the header (integer)
a less tiny segment that contains the header itself (JSON format)
the main segment containing the model (binary)
Why safetensors is safe?
When using pickle, Python’s “eval” is applied on the loaded file (i.e., the model). “eval” runs whatever is loaded, which could be malicious code.
safetensors doesn’t use Python’s “eval”. It’s implemented in RUST. By design, RUST is robust to many different kinds of exploits. RUST doesn’t make safetensors 100% safe since we are still exposed to potential vulnerabilities of RUST. Nonetheless, it’s much more safe than running Python’s eval on unknown binaries.
Why safetensors is fast and memory efficient?
safetensors is not only safe, but it’s also fast and memory-efficient.
As we saw in the introduction of this article, PyTorch first creates an empty tensor, then loads the model weights, and finally copies the model weights into the empty tensor.
In contrast, safetensors directly loads the model on the specified device without doing any copy. It means that if your model requires 100 GB of memory, loading the model will approximately require 100 GB (a little bit more in practice). With a pickled model, you would need 200 GB to load 100 GB.
safetensors also supports lazy loading, i.e., you can read parts of the model without loading the entire model.
Load and save your models with safetensors
If you load models from the Hugging Face hub, transformers will load the safetensors version by default, if it exists. For instance, if you run:
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", device_map={"": 0})The safetensors version of Llama 2 7B will be loaded because this format is available in the meta-llama/Llama-2-7b-chat-hf repository:
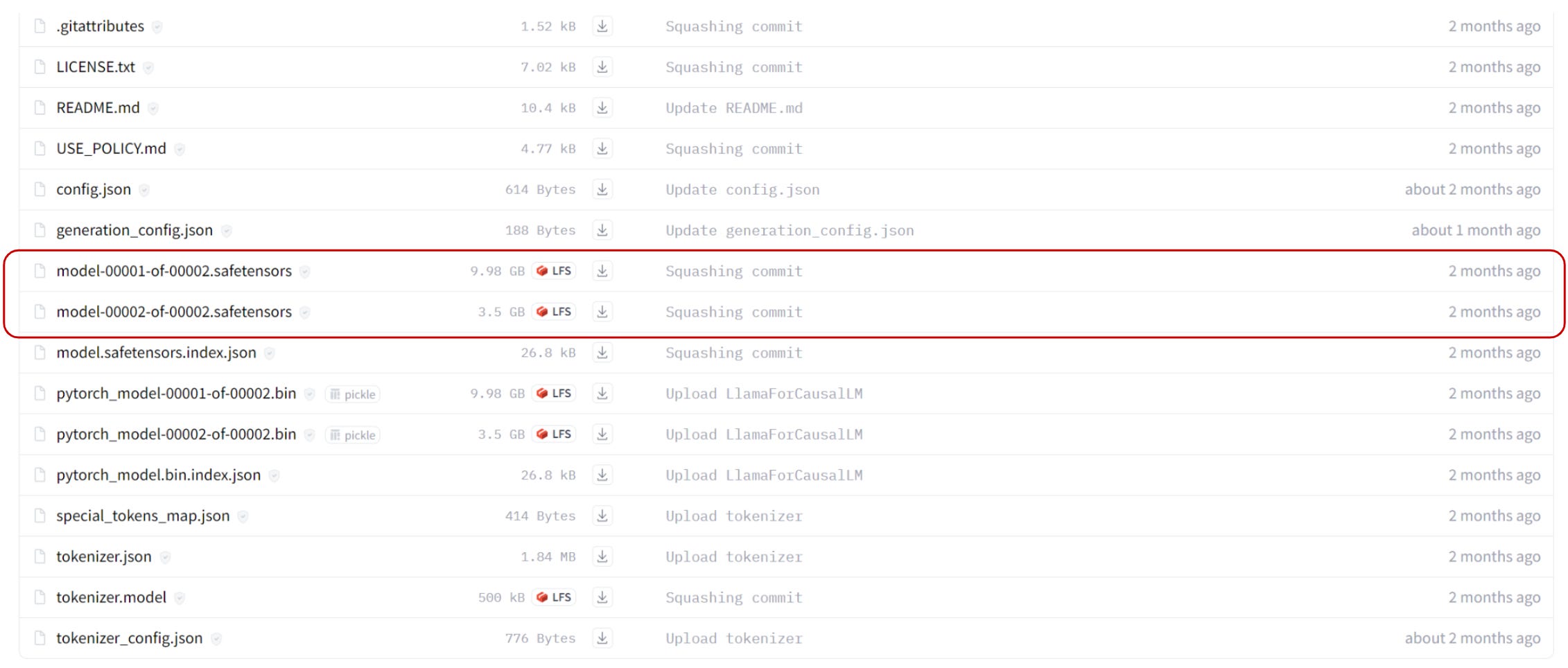
Note: Llama 2 7B requires at least 27 GB of VRAM to be fully loaded on the GPU. It would work if your computer could fit two RTX 3090 24GB*, or two RTX 4090* (more expensive but faster). If you don’t have enough VRAM, you may consider quantization or setting device_map=“auto” as described in these articles:


(* affiliated links)
If you wish to get the pickled version (the files with a “.bin” extension), you must set “use_safetensors=False”:
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", device_map={"": 0}, use_safetensors=False)By default, the transformers library saves models with pickle. For instance, for saving a model in a directory named “llama2_PyTorch_pickle”, we would call save_pretrained:
model.save_pretrained("llama2_PyTorch_pickle")For saving with the safetensors format, we must set “safe_serialization=True”:
model.save_pretrained("llama2_safetensors", safe_serialization=True)This creates a local directory containing “.safetensors” files.
Convert an existing model to safetensors
If you push pickled models to Hugging Face Hub, a bot will automatically convert your model to the safetensors format. The converted model will appear in a new branch of your model repository that you will have to merge by yourself. Note: The bot might take a while to come to your repository. If your model is rarely downloaded, it might never come. If you are looking for the safetensors version of a model on the hub, check whether there isn’t a branch of the repository that has been opened by the bot.
Instead of waiting for a bot, you can do the conversion by yourself. We have two main solutions:
Load the pickled version and save it with safetensors as we saw in the previous section.
Use Hugging Face web UI (it works only for models stored on the Hugging Face hub)
I don’t recommend running the first solution on your computer unless you are sure that the model can be trusted. I would do it in a sandbox such as Google Colab.
The second solution is safe but much slower. It can only convert models named “pytorch_model.bin”.