
Intel AutoRound: Accurate Low-bit Quantization for LLMs
Between quantization-aware training and post-training quantization

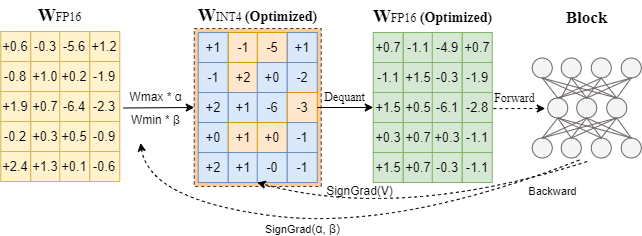
There are many quantization methods to reduce the size of large language models (LLM). Most of them are only good enough for 4-bit quantization. Quantization to 3-bit and 2-bit usually results in a significant accuracy drop, making LLMs unusable for most language generation tasks.
Recently, better low-bit quantization methods have been proposed. For instance, I reviewed and experimented with AQLM which achieves 2-bit quantization while preserving most of the model's accuracy.

The main drawback of AQLM is that the quantization of large models takes many days. HQQ is another good alternative for low-bit quantization but requires further fine-tuning to preserve accuracy.

Intel is also very active in the research of better quantization algorithms. They propose AutoRound, a new quantization method adopting sign gradient descent (SignSD). AutoRound is especially accurate for low-bit quantization and quantizes faster than most other methods.
In this article, I review AutoRound. We will see how it works and how to quantize LLMs, such as Llama 3, with minimal accuracy drop. I found AutoRound to be a very good alternative to GPTQ and HQQ. It yields more accurate models.
I implemented the following notebook showing how to quantize LLMs with AutoRound, and evaluate/benchmark the resulting models: