


GPT-OSS 120B Tops The Kaitchup Index
The Weekly Kaitchup #105


Hi Everyone,
In this edition of The Weekly Kaitchup:
GPT-OSS Tops the Kaitchup Index
Gemma 3 270M: The Best Tiny Model?
Update of Older Articles
GPT-OSS Tops the Kaitchup Index
GPT-OSS 120B takes first place in The Kaitchup Index, which is my own benchmark made of private data. On average, it outperforms every other model I tested that fits on an 80 GB GPU.
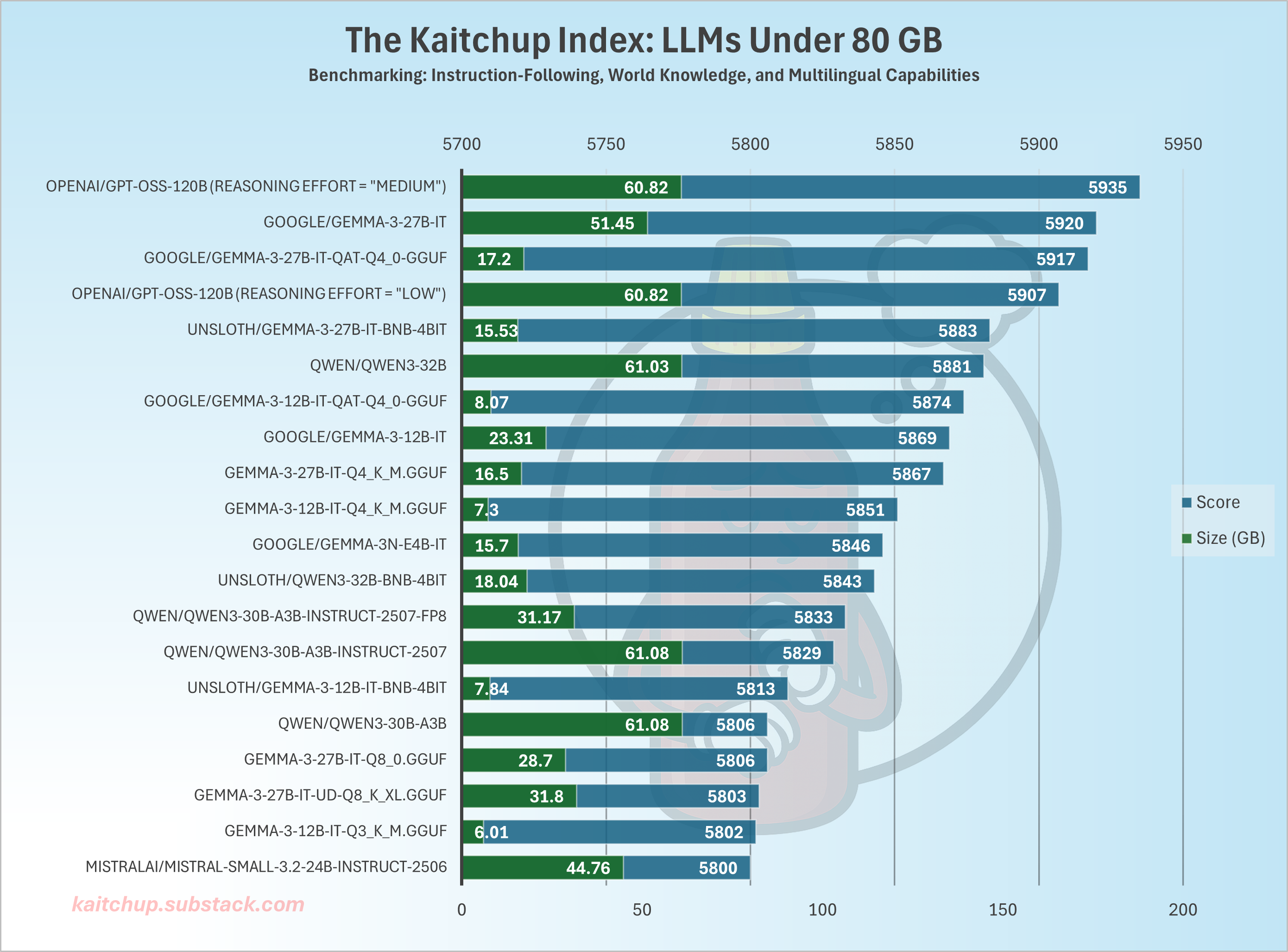
Reasoning depth: For tasks that don't require much reasoning, moving from low to medium reasoning slightly improves quality, but the inference cost spikes. For most use cases, stick with low. I didn’t test high. That run would have taken days rather than hours.
Languages:
Japanese: GPT-OSS is the best model I’ve tested.
French & Portuguese: Mistral Small remains stronger.
German: performance is roughly tied with Mistral Small
Mandarin: Qwen3 is still far ahead.
Indic languages: Gemma 3 remains better.
Not bad, considering that GPT-OSS has been "mostly" trained on English data.
Is comparing 20~30B models to ~120B fair?
Yes! Parameter count is not what matters. What matters is memory footprint and throughput. GPT-OSS ~120B is a quantized MoE, so in practice it’s slightly smaller in memory than Qwen3 32B while generating tokens faster (only 5B active parameters). On these operational metrics, it’s a very competitive choice for an 80 GB GPU.
These experiments also highlight a gap: we don’t currently have many similarly sized (by parameter count) models that can compete once quantized. Given how mature 4-bit quantization is, training a 100~120B model and running it at 4-bit is a natural fit for 80 GB GPUs. Likewise, it’s been a while since we’ve seen a strong new ~70B model that, once 4-bit quantized, could shine on 48 GB GPUs.
Check The Kaitchup Index for all the results per language, including for GPT-OSS 20B:

GPT-OSS Support for Older GPUs
Hugging Face has updated Transformers and now supports older GPUs for running GPT-OSS, such as the T4, A100, and L4. GPT-OSS models don’t need to be fully dequantized to be used with these GPUs. However, this is just a “compatibility” improvement leveraging some specialized Triton kernels, i.e., expect much slower throughput as the tensors are dequantized on the fly.
Gemma 3 270M: The Best Tiny Model?
We had Gemma 3 1B, 12B, 27B, and now, 270M!
Gemma 3 are multimodal models but, like the 1B model, the 270M is text-only.
Gemma 3 270M’s total parameters split into ~170M embedding params and ~100M transformer blocks. Its vocabulary remains extremely large for such a small model: 262,144 tokens. Thanks to this large vocabulary, it can, in theory, handle rare or domain-specific tokens well and make a strong base for hyper-specialized fine-tunes in specific languages or tasks. Don’t expect good performance for general tasks like coding or long-context and reasoning, even once fine-tuned.
The model performs well on benchmarks, even compared to larger models.

Google released both a pre-trained checkpoint and an instruction-tuned variant, so you can fine-tune for your needs or use it for basic instruction following out of the box. Production-ready quantization is available via QAT checkpoints, enabling INT4 inference with minimal degradation. In internal tests by Google, on a Pixel 9 Pro SoC, the INT4 model consumed about 0.75% battery for 25 conversations, making it the most power-efficient Gemma to date.
Choose Gemma 3 270M when you’ve got high-volume, well-defined, simple tasks such as sentiment analysis, entity extraction, query routing, and unstructured-to-structured transforms. You’ll cut latency and costs (milliseconds and micro-cents), iterate and fine-tune quickly thanks to the small footprint.
I’ll try some fine-tuning for very specific tasks. If I manage to get good results, I’ll write an article about it.
Update of Older Articles
The Kaitchup now has 200+ articles and nearly 180 notebooks. Keeping every single one current isn’t realistic, so I’m focusing on a core set of evergreen pieces—tutorials that still work today and should remain useful.
I’ve scheduled updates to several articles and their companion notebooks that showcase “AI on a budget” techniques likely to stay relevant: LoRA/QLoRA fine-tuning, synthetic data generation, quantization, and low-cost evaluation.
To kick things off, I’ve refreshed one of my earliest QLoRA posts, originally published just days after Tim Dettmers released his QLoRA paper. It still explains the fundamentals and trade-offs of QLoRA, but the examples now run on the latest TRL stack (the original notebook used vanilla Transformers, which is less suitable for modern PEFT workflows).

My goal is to keep this article and its notebook continuously maintained.
Other updates for older articles will follow.
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

⭐Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
Hidden Dynamics of Massive Activations in Transformer Training
MoBE: Mixture-of-Basis-Experts for Compressing MoE-based LLMs
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!