
Encoder–Decoders and Byte LLMs: T5Gemma 2 and AI2’s New Models
The Weekly Kaitchup #123


Hi everyone,
Google shipped a lot this week:
FunctionGemma: A tiny, Gemma 3–based 270M-parameter model pre-trained specifically for text-only function calling, intended to be fine-tuned into specialized agents (like on-device games or mobile assistants) and deployed on resource-constrained hardware rather than used as a general chat model out of the box.
Gemma Scope 2: An open suite of per-layer and multi-layer sparse autoencoders and transcoders for Gemma 3 models from 270M to 27B parameters, designed to act as a “microscope” that decomposes internal activations into interpretable features and concepts.
T5Gemma 2: A small, Gemma 3-based family of multilingual, multimodal encoder–decoder models (up to 4B-4B) that extend Gemma with 128K context, text+image input, and parameter-efficient tweaks like tied embeddings and merged attention, making them practical research workhorses for long-context generation and vision-language tasks on modest hardware.
As I write this, Gemma 4 still isn’t out, though there is a possibility it’ll drop in the next few hours. I’ll cover it in a dedicated post when it lands.
AI2 also had a busy week, with Molmo 2, Olmo 3.1, and Bolmo.
In this edition of The Weekly Kaitchup, I’ll focus on what I think is the most interesting Google release, T5Gemma 2, along with the new models from AI2.
T5Gemma 2: Encoder-Decoder LLMs Getting Better Again
A few months ago, Google released T5Gemma, an attempt to bring back the original encoder–decoder Transformer with cross-attention, essentially revisiting the T5-style architecture in a world now dominated by decoder-only LLMs.
Conceptually, it was a neat throwback, but the first T5Gemma models weren’t especially strong, and the extra encoder made inference noticeably heavier, particularly on memory. What’s surprising is that Google didn’t drop the idea. Instead, they doubled down and iterated.
T5Gemma 2 takes the original T5Gemma recipe, adapting a decoder-only Gemma into an encoder–decoder, and pushes it into the “modern LLM” feature set: multimodal input, long context, and stronger multilingual support, all while staying in the small-to-mid parameter regime.
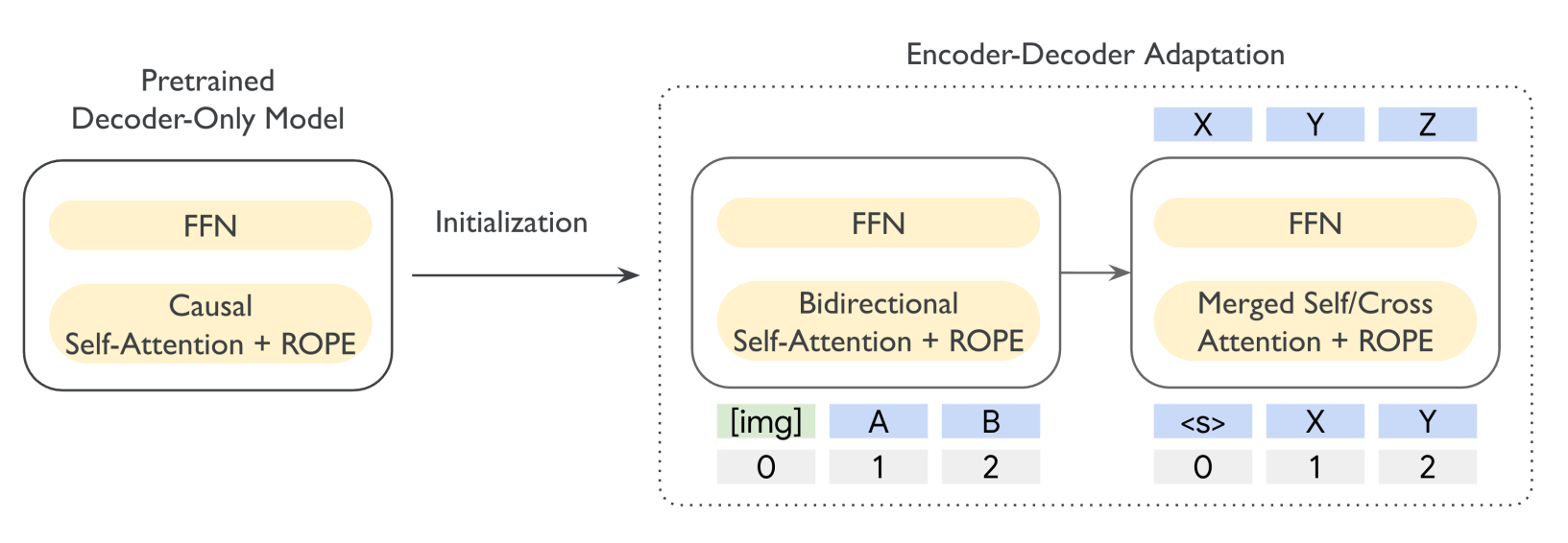
The key shift is that the base is now Gemma 3 instead of Gemma 2 for the first T5Gemma, so the encoder–decoder inherits grouped-query attention, RoPE, interleaved local/global layers and the long-context tricks from that family, then wraps them in an encoder–decoder shell. The result is a set of 270M–270M, 1B–1B and 4B–4B models that can read both text and images and generalize to 128k-token contexts, even though they were only pretrained up to 16k.
With this new version, they explicitly go after parameter waste: instead of separate encoder and decoder embeddings, all word embeddings (encoder input, decoder input, decoder output) are tied, cutting embedding parameters roughly in half (which is significant given the large vocabulary of Gemma 3) with essentially no quality loss.
They also collapse decoder self-attention and cross-attention into a single “merged attention” module that attends jointly over decoder and encoder tokens with one shared set of attention weights. That shrinks total model size by a non-trivial margin with only a very small hit in pretraining scores, and makes the decoder look much closer to the original decoder-only Gemma stack.
On top of that, T5Gemma 2 plugs in a frozen SigLIP vision encoder (mapped to 256 tokens fed to the encoder) and uses more aggressive RoPE settings plus positional interpolation to get to 128k context at inference.
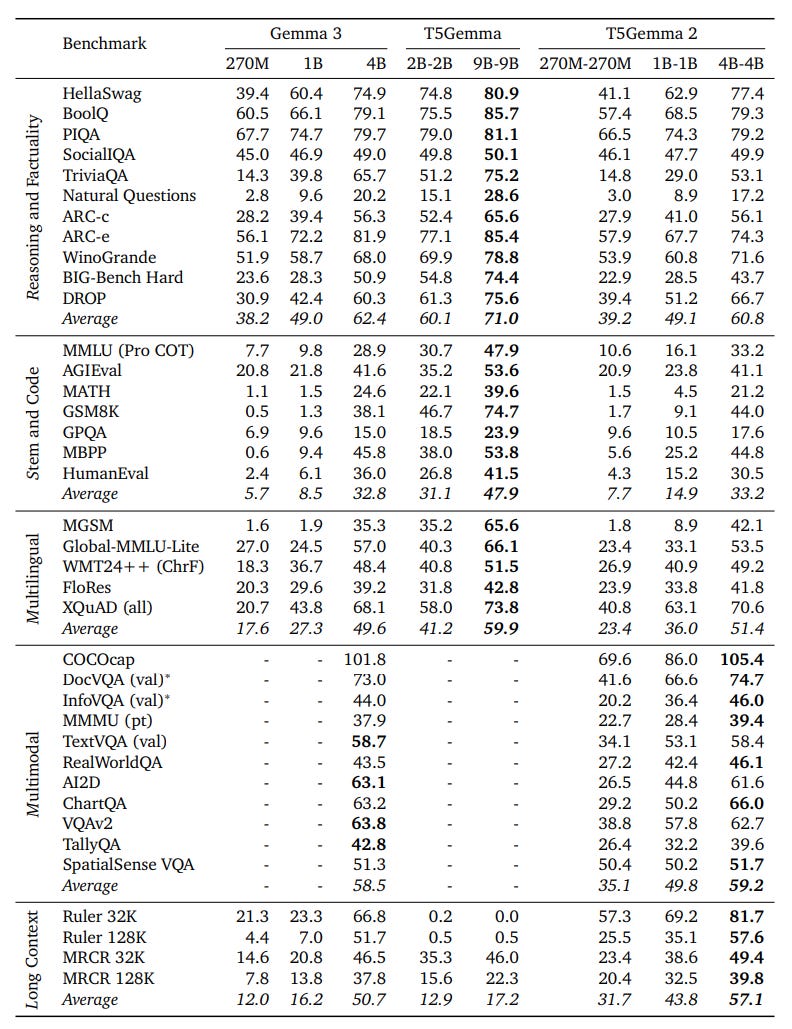
The models significantly outperform Gemma 3 but double the number of parameters:
The technical report is here:
T5Gemma 2: Seeing, Reading, and Understanding Longer
Olmo 3.1, Molmo 2, and Bolmo: Better, Multimodal, and Tokenizer-Free Models
OLMo 3.1
OLMo 3.1 is an update to OLMo 3.
Ai2 just pushed the post-training of Olmo 3 further, most notably by extending its best reinforcement-learning run for the 32B Think model.
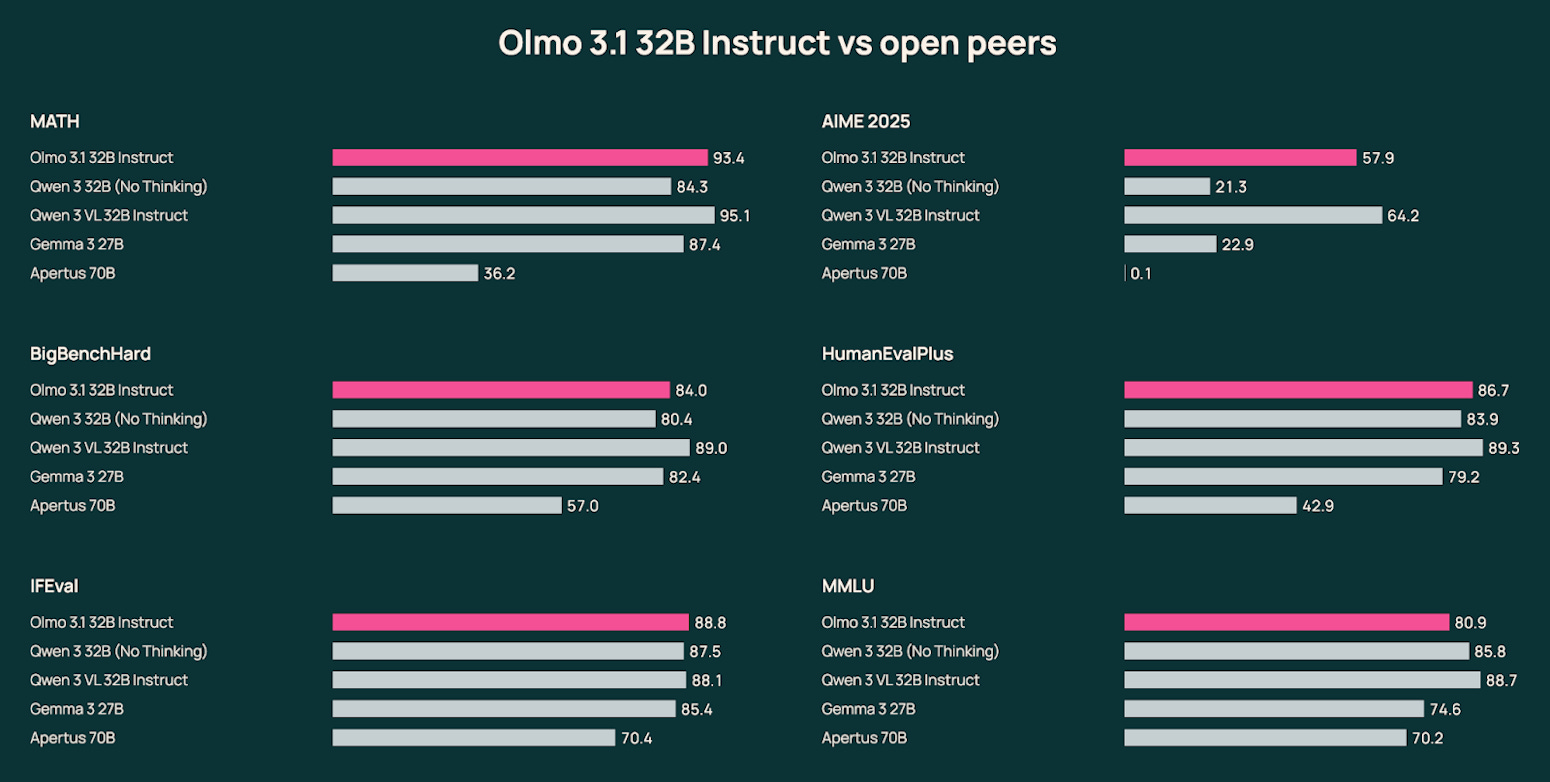
Concretely, Ai2 continued the OLMo 3 32B Think RL run for an additional 21 days on 224 GPUs with extra epochs over the Dolci-Think-RL dataset, producing OLMo 3.1 Think 32B and reporting sizeable benchmark jumps (e.g., +5 on AIME, +4 on ZebraLogic and IFEval, +20 on IFBench), alongside stronger coding and multi-step performance.
OLMo 3.1 also adds OLMo 3.1 Instruct 32B by scaling up the OLMo 3 Instruct 7B recipe to 32B for better chat/tool-use/multi-turn behavior.
I quantized all these models. Evaluation is ongoing for the 32B models, but for now, I don’t see any significant accuracy loss, even with the 4-bit versions. You can find the models here:
And more details on their performance here:

Molmo 2
Molmo is the multimodal series of models by Ai2. This time, Molmo 2 moves beyond the original Molmo’s static-image strengths and targets video grounding, pointing, and tracking as first-class capabilities. Ai2 reports that the 8B Molmo 2 variant (Qwen 3–based) can outperform the original Molmo 72B on key pointing/grounding benchmarks, and that on video tracking it leads their evaluations, beating multiple open baselines and (in their tests) outperforming Gemini 3 Pro, while using far less video data than Meta’s PerceptionLM (9.19M vs 72.5M videos).
Under the hood, Molmo 2 keeps the standard “VLM” shape, vision encoder + language backbone, but upgrades how vision is represented and stitched into time.
The vision encoder turns frames into visual tokens. A lightweight connector then interleaves those tokens with timestamps and image indices so the LLM can jointly reason over space, time, and text, and the model can answer with grounded evidence (points and timestamps) rather than only free-form text.
For video, Ai2 describes sampling up to 128 frames (≤2 fps), pooling patches into 3x3 windows to keep sequences tractable, and allowing visual tokens across frames/images to attend to each other (a boost for multi-image/video reasoning).

More details here: Molmo 2: State-of-the-art video understanding, pointing, and tracking
Bolmo
Bolmo is a bit more original. Ai2’s push toward practical byte-level language modeling without paying the usual “train-from-scratch” tax.
Instead of relying on a fixed subword vocabulary (BPE/WordPiece), Bolmo operates on raw UTF-8 bytes, but it avoids the inefficiency of treating every byte like a full token by using a latent-tokenizer architecture: bytes are embedded, processed by a lightweight local encoder (mLSTM), segmented into variable-length “patches” by a boundary predictor that uses a small amount of future context (non-causal), then passed as patches into the global transformer (reusing the OLMo 3 backbone), before being depooled back to bytes and refined by a local decoder for next-byte prediction.
Bolmo byteifies an existing strong subword model in two stages:
Freeze the OLMo 3 transformer and cheaply train only the new byte-level components to mimic the source model
Unfreeze and continue end-to-end training so it can exploit byte-level signals
The process is fairly simple and could be applied to any LLM.
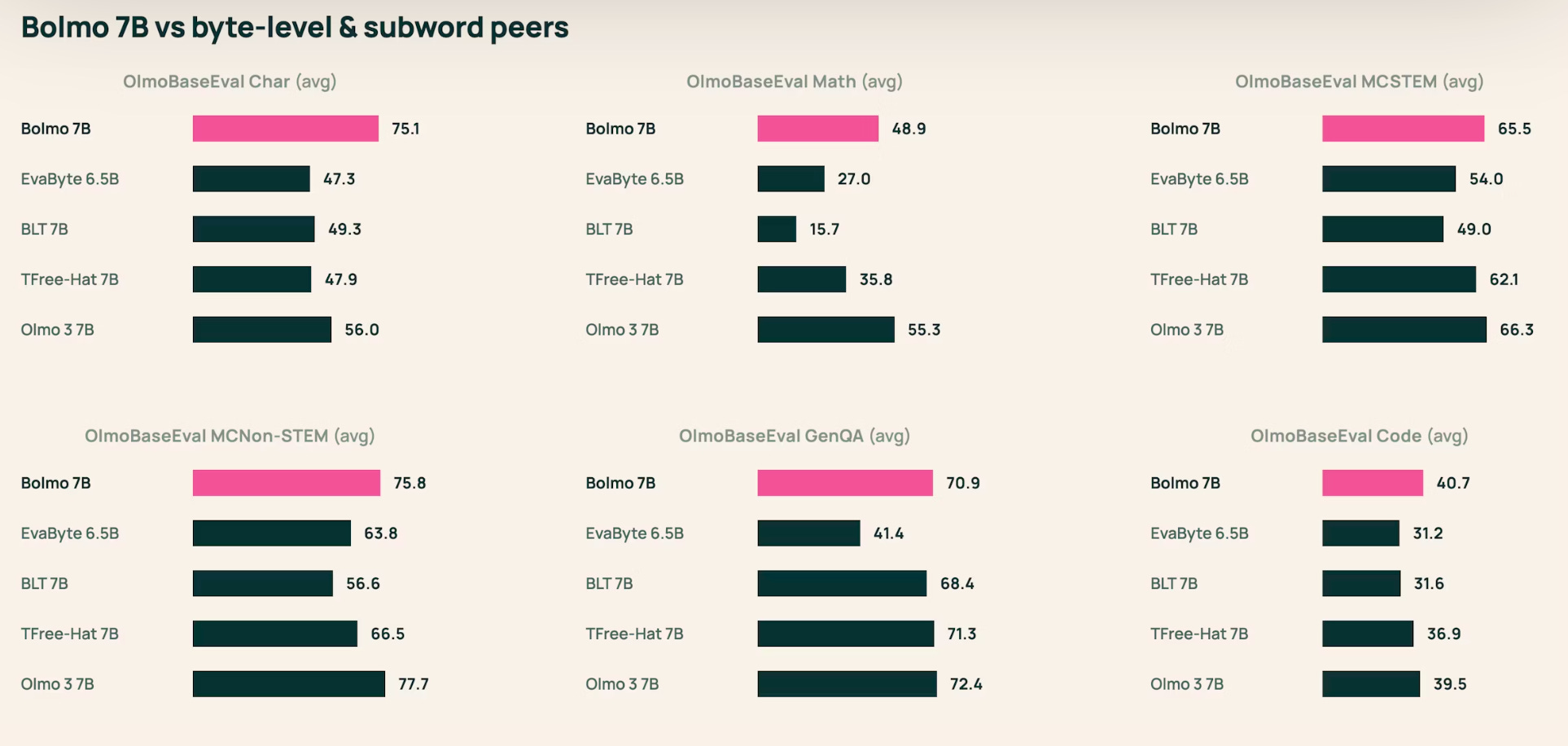
On performance, Ai2 reports Bolmo 7B stays close to subword OLMo 3 7B on broad capability suites while substantially improving character-focused understanding (e.g., large gains on CUTE/EXECUTE) and comparing favorably against other byte-level baselines. Very impressive results in my opinion.
They also emphasize it remains usable in practice, citing competitive decoding throughput (about 125 bytes/s vs ~150 bytes/s for the corresponding subword model at similar compression).
More details here: Introducing Bolmo: Byteifying the next generation of language models
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I wrote a full review of the Qwen3-VL technical report:

This week, we review:

⭐QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
State over Tokens: Characterizing the Role of Reasoning Tokens
Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models
VersatileFFN: Achieving Parameter Efficiency in LLMs via Adaptive Wide-and-Deep Reuse
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!
So does it mean there is still hope for encoder-decoders and that it's in the small model size range? But aren't they harder to fine tune (or at least less convenient)? Or should we treat it more like interesting research.