
Quantizing Olmo 3: Most Efficient and Accurate Formats
GPTQ, FP8, NVFP4, SmoothQuant, and AWQ on Olmo 3 7B

Olmo 3 is a standard 7B/32B decoder-only transformer. No MoE, no exotic attention, no flashy new architecture tricks. Most of the change is in the training pipeline: in the data (Dolma 3), the midtraining mix (Dolmino), the long-context stage (Longmino), and the “thinking” stack (Dolci, SFT, DPO, RL).
In this article, I briefly go through what actually changed compared to Olmo 2, and what didn’t work.
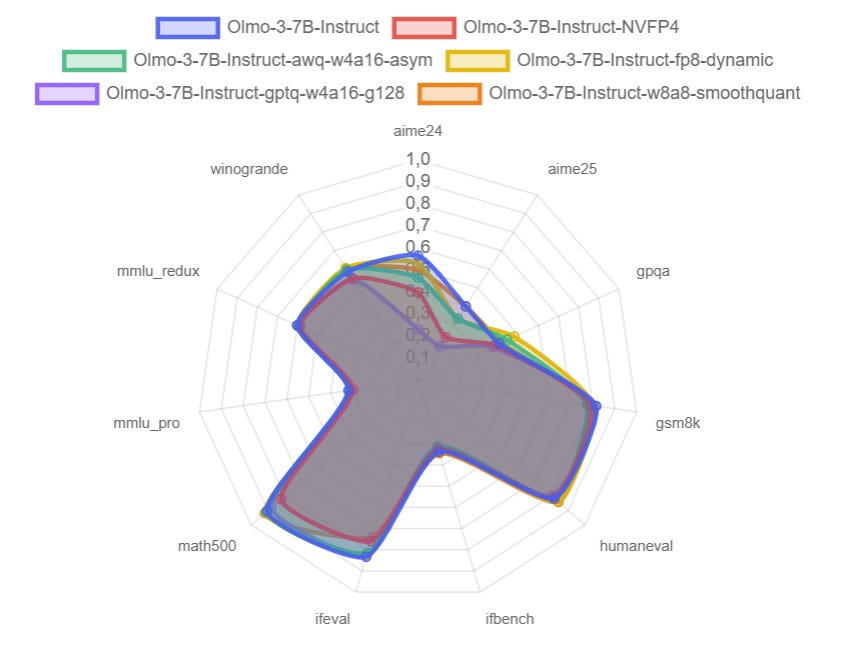
Then I move to quantization. I quantized Olmo 3 7B and 32B with several standard recipes that are practical to run on a single consumer GPU:
gptq-w4a16-g128
fp8-dynamic
nvfp4
awq with custom mappings for Olmo 3
W8A8 (INT8) with SmoothQuant
Finally, I look at how these variants behave on benchmarks: accuracy, PASS@k, and token efficiency, plus some notes on hardware choices (RTX 5090 vs RTX 6000) and what actually matters once you run long contexts with concurrent queries.
I used the same quantization script I released last week:
I released my quantized models here: