


Zephyr 7B Beta: A Good Teacher Is All You Need
Knowledge distillation for Mistral 7B


Mistral 7B is one of the best pre-trained LLMs. By releasing Zephyr 7B Alpha, Hugging Face has demonstrated that Mistral 7B fine-tuned with DPO can outperform chat models that are 10 times bigger and even match the performance of GPT-4 for some tasks.

With the “Alpha” in the name of the model, Hugging Face was obviously planning to release better versions of Zephyr 7B. And they indeed released Zephyr 7B Beta only 2 weeks later. There is a technical report on arXiv describing the model and its evaluation.
Zephyr: Direct Distillation of LM Alignment (Tunstall et al., 2023)
In this article, we will see what makes Zephyr 7B Beta better than larger LLMs. More particularly, we will see how Hugging Face leveraged larger LLMs, such as GPT-4, to teach Mistral 7B to answer instructions and align the answers with human preferences.
Distillation: When Smaller LLMs Learn from Larger Ones
Since Hugging Face relied on knowledge distillation (KD) to train Zephyr, let’s have a brief reminder of what KD is in the context of LLMs.
Most LLMs are trained on texts written by humans. Human texts present a high diversity of sequences of tokens and vocabulary that is difficult to model. Because of this difficulty, we need a lot of data to train an LLM to properly model language.
There is a shortcut to reduce the training cost and difficulty: knowledge distillation (KD). There are many ways to do KD. In this section, I’ll only discuss the method used by Hugging Face.
Once trained on human texts, even though LLMs can be very good at generating language, they only approximate the true probability distribution of language. LLMs generate by default much less diverse sequences of tokens than humans. Note: That’s why random sampling is often introduced during inference, for instance via nucleus sampling, to improve the diversity in the generated text.
Since sequences of tokens generated by LLMs are less diverse than human text, learning to model these generated sequences is a much easier task.
In practice, this is achieved by using a state-of-the-art model, often called the teacher model, that generates a large amount of synthetic text that will be used to train a smaller model, often called the student model. The student distills the knowledge of its teacher.
The student model’s training converges much faster on the generated text and can achieve a performance close to the teacher.
This strategy works well for training LLMs. One of the best examples of success that we have is Microsoft’s phi-1.5: A 1.3 billion parameter model matching the performance of much larger models. Microsoft’s phi-1.5 has been exclusively trained on synthetic data generated by other models, i.e., Microsoft’s phi-1.5 is a student model. Note: Microsoft didn’t disclose what were the teacher models.

Zephyr 7B Beta is also a student model. All its training data have been generated by much larger models, hence a much better performance than other LLMs of similar size trained on human texts (e.g., Llama 2).
In the case of Zephyr 7B Beta, Hugging Face pushed knowledge distillation much further into the process of training and aligning an LLM with human preferences, as we will see in the next sections.
dDPO: Distilled Direct Preference Optimization with Mistral 7B
Making Zephyr 7B Beta from Mistral 7B is a three-step process:
Supervised fine-tuning (SFT) on instruction datasets generated by other larger models
Scoring/ranking LLMs’ outputs using a state-of-the-art LLM
Training DPO with the model obtained in Step 1 on the data obtained in Step 2
Distilled Supervised Fine-Tuning (dSFT)
SFT is the standard first step for training an instruct/chat model. It requires an instruction dataset: instructions/questions paired with answers given by humans.
The main issue here is that collecting such a dataset is extremely expensive since it involves human labor. A more and more common cheaper alternative is to use instruction datasets generated by other LLMs.
We can find many such instruction datasets on the Hugging Face Hub that we can use for SFT, for instance:
OpenAssistant Conversations Dataset (OASST1) (84.4k training examples)
OpenOrca (4.2M training examples)
openassistant-guanaco (9.8k training examples)
For Zephyr 7B Beta, Hugging Face fine-tuned Mistral 7B on a custom version of Ultrachat that they aggressively filtered:
we applied truecasing heuristics to fix the grammatical errors (approximately 5% of the dataset), as well as several filters to focus on helpfulness and remove the undesired model responses.
Hugging Face denotes this SFT “Distilled Supervised Fine-Tuning” since the fine-tuning is done on datasets generated by “teacher” models.
AI Feedback through Preferences (AIF)
For alignment with humans, we need a dataset of prompts paired with ranked answers. We can then use DPO, or RLHF, to train the model to generate preferred answers.
Ranking models’ answers is an expensive task requiring human labor. But again, we already have aligned LLMs that are good enough to make this ranking.
We can take an existing dataset of prompts paired with answers generated by different models and use a state-of-the-art LLM to rank these answers.
For this step, Hugging Face directly used the dataset UltraFeedback.
UltraFeedback contains 74k prompts paired with responses generated by the following models:
LLaMA-2-7B-chat, LLaMA-2-13B-chat, LLaMA-2-70B-chat
UltraLM-13B, UltraLM-65B
WizardLM-7B, WizardLM-13B, WizardLM-70B
Vicuna-33B
Alpaca-7B
Falcon-40B-instruct
MPT-30B-chat
StarChat-Beta
Pythia-12B
Each LLM’s output is rated by GPT-4 with a score from 1 to 5 (higher is better) for various criteria:
instruction following
helpfulness
honesty
truthfulness
For DPO, we need a “chosen” output, i.e., the output that we prefer, and a “rejected” output, an output that we don’t want the model to generate.
For the chosen output, the output with the highest mean score (using all criteria to compute this mean) is selected. For the rejected output, they randomly selected an output among the remaining ones.
They don't justify this randomness for the selection of the rejected output. Note: Actually, they do justify it. Here is what I missed in the technical report:
We opted for random selection instead of selecting the lowest-scored response to encourage diversity and make the DPO objective more challenging
The version of the dataset they have made and used for training DPO is here:
HuggingFaceH4/ultrafeedback_binarized (split: train_prefs)
Distilled Direct Preference Optimization (dDPO)
I explained DPO and how to use it for Mistral 7B in this article:
Note that Hugging Face calls it “Distilled Direct Preference Optimization” only because the SFT and preferences are generated by other LLMs. The DPO process itself remains standard.
The Evaluation of Zephyr 7B Beta
Hugging Face has evaluated Zephyr along the following axes on MT Bench: writing, roleplay, reasoning, math, coding, extraction, STEM, and humanities

It is clear that Zephyr outperforms Llama 2 70B while performing closely to other state-of-the-art commercial LLMs. GPT-4, Zephyr’s main teacher, remains much better at reasoning, math, coding, and extraction.
They have also performed an ablation study to demonstrate the importance of DPO.
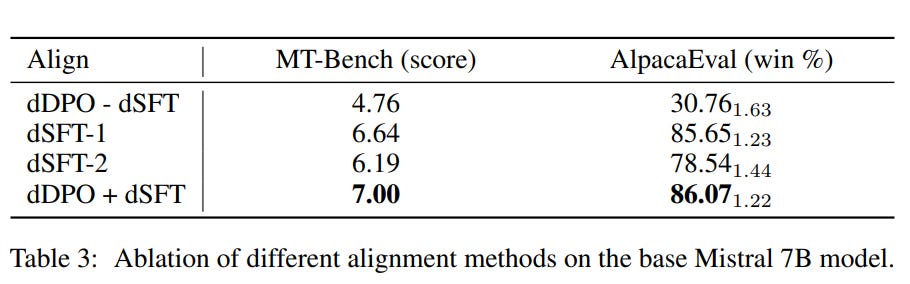
DPO alone (first row) poorly performs. However, the combination of DPO and SFT clearly outperforms SFT alone.
Conclusion
By relying on knowledge distillation, Hugging Face has demonstrated that it is possible to train and align a state-of-the-art LLM without using any human annotations.
Zephyr 7B Beta is a rather cheap model to make, especially compared to other larger models such as Llama 2 Chat 70B. However, given the size of the training batch (2) per GPU, and the fact that they fully fine-tuned Mistral 7B (they didn’t use LoRA), they had to use 16 A100 GPUs (for up to 4 hours according to the technical report). This is far from a cheap hardware configuration.
In the next article, we will see how to use the datasets released by Hugging Face to train our own cheap Zephyr 7B Beta, using parameter-efficient training methods, on consumer hardware. We will also discuss the training hyperparameters and how to adapt them for consumer hardware while preserving the model’s performance as much as possible.