
Why the Evaluation of OpenAI Whisper Is Not Entirely Credible
The conclusions from half of the evaluation tasks are questionable. The main culprit? The text normalizer.

In September, OpenAI released Whisper, a new multi-purpose model for speech recognition. It is trained on larger datasets than previous work and is especially good at zero-shot tasks, i.e., tasks for which it has not been trained for.
The research paper released (but not peer-reviewed) along the model describes, evaluates, and analyzes the performance of Whisper in various tasks.
In my opinion, the paper is very well-written, and the motivation behind this work is very intuitive, e.g., targeting human performance for any tasks rather than trying to outperform humans on very specific tasks and datasets that won’t generalize well.
Whisper isn’t achieving a new state-of-the-art on some well-known speech recognition (ASR) benchmarks, but instead achieves top performances on many benchmarks.
Now that I have acknowledged how great the model itself is, let’s have a look at what motivated me to write this article.
Are the claims and evaluation of Whisper scientifically credible?
Whisper is evaluated on 6 tasks (section 3 of the research paper). In the remainder of this article, I will demonstrate that the conclusions drawn from 3 of these evaluation tasks are flawed ❌ or misleading ❌. As we will see, even the authors noted in the paper that uncomparable numbers are compared.
✔️English Speech Recognition
❌Multi-lingual Speech Recognition
❌Translation
✔️Language Identification
✔️Robustness to Additive Noise
❌Long-form Transcription
A Text Normalization for a Better Evaluation

Before looking at each evaluation task, I have to present an important component of Whisper’s evaluation: the text normalizer.
OpenAI created a new text normalizer applied to the output of Whisper. This is very well presented and motivated as follows:
systems that output transcripts that would be judged as correct by humans can still have a large WER due to minor formatting differences […] We opt to address this problem with extensive standardization of text before the WER calculation to minimize penalization of non-semantic differences. Our text normalizer was developed through iterative manual inspection to identify common patterns where naive WER penalized Whisper models for an innocuous difference. Appendix C includes full details.
WER, for word error rate, is the common evaluation metric for speech recognition. Lower WER scores are better. It means that the transcription of the speech contains more words of a given human reference transcription and in a more similar order. It is derived from the Levenshtein distance.
Appendix C of the paper sums up the many normalization operations performed by Whisper’s text normalizer. The effect is well illustrated by one of the notebooks published by OpenAI in Whisper’s Github. In the following screenshot of this notebook, you can see texts before and after the normalization. Whisper’s hypothesis and the reference are both “cleaned” by the text normalizer, significantly modifying them.

Basically, this normalization aims at avoiding unfair penalization in WER by removing characters not important for the target task. This is very intuitive but with very significant consequences for the evaluation. They add:
For several datasets, we observe WER drops of up to 50 percent usually due to a quirk such as a dataset’s reference transcripts seperating contractions from words with whitespace.
In other words, WER scores computed on normalized texts will be lower and better. Remember for the remainder of this article that this text normalizer is new, i.e., work previously published didn’t use it. The scores published in previous work are not comparable with the ones computed by OpenAI for Whisper since they are computed on human references differently normalized (or not normalized at all).
Now, we can have a look at how it affects the credibility of the evaluation.
✔️Task 1: English Speech Recognition
For this task, I couldn’t find any obvious flaws in the evaluation. They compared their WER scores against WAV2VEC 2.0. All the scores have been computed by OpenAI. They apply the same text normalizer on both WAV2VEC and Whisper outputs to obtain comparable scores.
The results show that Whisper generalizes better to many benchmarks.
❌Task 2: Multi-lingual Speech Recognition
OpenAI wants to show that Whisper also works very well for other languages than English.
But, in contrast to what they did for Task 1, they didn’t compute by themselves the WER scores of previous work.
The results compared are presented in Table 3.

The WER scores are copied from previously published research papers. They don’t explicitly provide the source of these scores. The scores for zero-shot Whisper are computed by OpenAI.
As we saw, they applied a new text normalizer that simplifies both the output of Whisper and the human reference. Hence, Whisper scores are mechanically lower. WER scores of previous work are computed using a different human reference. About this, OpenAI honestly recognizes:
We caution that we do use a simple text standardizer for this result which prevents direct comparison or claims of SOTA performance.
Yet, they also write:
Our system performs well on Multilingual LibriSpeech, outperforming both XLS-R and mSLAM in a zero-shot setting.
So what can we conclude? Is Whisper outperforming both XLS-R and mSLAM or does the text normalization prevent direct comparison?
Obviously, we cannot conclude anything from this evaluation. These WER scores are not comparable. These results are misleading. The text normalization has an unpredictable effect on the amplitude of the differences between these scores. It is very likely that, without normalization, Whisper WER scores would be much higher, as discussed by the authors themselves when they presented the text normalizer.
❌Task 3: Translation
If you read my previous articles, you may already guess what I will demonstrate now…
Whisper is evaluated on a translation task using the metric BLEU. BLEU is a common metric for machine translation evaluation. You can see it has an evolution of WER. Basically, you can’t compare BLEU scores computed on two different reference translations.
The results for this task are presented in Table 4.
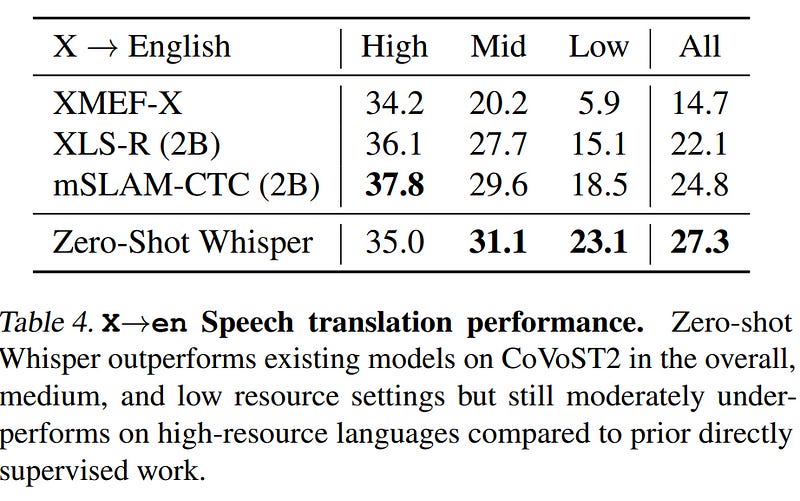
Similarly to Task 2, the scores are copied from previous work. The scores for zero-shot Whisper are computed by OpenAI.
Here, it is unclear whether they applied the text normalizer to Whisper’s outputs. If they did, the BLEU scores are de facto not comparable. Note that previous work also didn’t mention how they computed the BLEU scores in their papers. There are so many parameters to take into account when calculating BLEU scores that it is commonly recognized that BLEU scores extracted from different papers can’t be compared. This is very well demonstrated by Post (2018).
Yet, OpenAI makes the comparisons and even claims a new state of the art.
new state of the art of 27.3 BLEU zero-shot without using any of the CoVoST2 training data
This is the only claim of a new state-of-the-art in the entire paper. The precision of “zero-shot” makes it more credible, but this is only 2.5 BLEU points of improvement over previous work. It can easily vanish depending on processing/normalization steps applied to the reference translation and/or not be statistically significant.
The scores aren’t comparable. We can’t conclude anything from this evaluation.
Update (v1): Shortly after the publication of this article, OpenAI contacted me to add some details not given in the paper for this evaluation task:
- They confirm that they didn’t perform text normalization here
- They used SacreBLEU to compute their BLEU scores
That doesn’t make the results comparable with previous work since we don’t know how the BLEU scores were computed in previous work. Nonetheless, I would like to thank OpenAI for reaching out.
✔️Task 4: Language Identification
Here, I have nothing to say about scientific credibility except some minor comments. I wonder about the impact of the text normalization/filtering performed during training.
Also, it isn’t written whether they applied their text normalization before the classification. If they did, it partly explains the lower accuracy since the model won’t see many of the language-specific characters removed by the text normalization.
✔️Task 5: Robustness to Additive Noise
It looks correct to me and credible. Whisper is robust.
❌Task 6: Long-form Transcription
In this last task, Whisper is evaluated against commercial systems. Unfortunately, an evaluation of commercial black-box systems on a publicly available benchmark can’t be scientifically credible.
We don’t know the training data used by the commercial systems. For the sake of scientific credibility, we have to assume that the systems have been trained on the evaluation data. In other words, we have to assume that the systems are exposed to data leakage.
Again, for transparency, OpenAI clearly writes it:
we note the possibility that some of the commercial ASR systems have been trained on some of these publicly available datasets
Nonetheless, comparisons are made and conclusions are drawn. The difference observed between Whisper and commercial systems may only be due to their training on the evaluation datasets. Note: In my opinion, it makes a lot of sense for a company to train its systems on all the publicly available benchmarks to guarantee better performance in research papers published by other organizations.
Conclusion
For half of the evaluation tasks, the evaluation conducted by OpenAI isn’t scientifically credible. This is mainly due to the comparison of numbers that can’t be compared and to plausible data leakage. Reproducing their evaluation isn’t possible either. The evaluation pipeline isn’t disclosed and too many details are missing in the research paper.
Also, the evaluation could have been significantly more credible with a more diverse set of evaluation metrics and by testing the statistical significance of the results.
I wrote a much more extensive study about these evaluation pitfalls in my previous article.
Comparing the Uncomparable to Claim the State of the Art: A Concerning Trend
In AI research, authors of scientific papers often choose to directly compare their own results with results published in previous work, assuming that these results are all comparable. In other words, researchers perform a simple copy of previous work’s numbers for a comparison with their own numbers, instead of reproducing days or even weeks of experim…
Note that Whisper is nonetheless an outstanding model that you should definitely consider for your speech recognition tasks. The model is publicly available and open-source.