
vLLM: PagedAttention for 24x Faster LLM Inference
A more efficient way to compute Transformer’s attention during inference

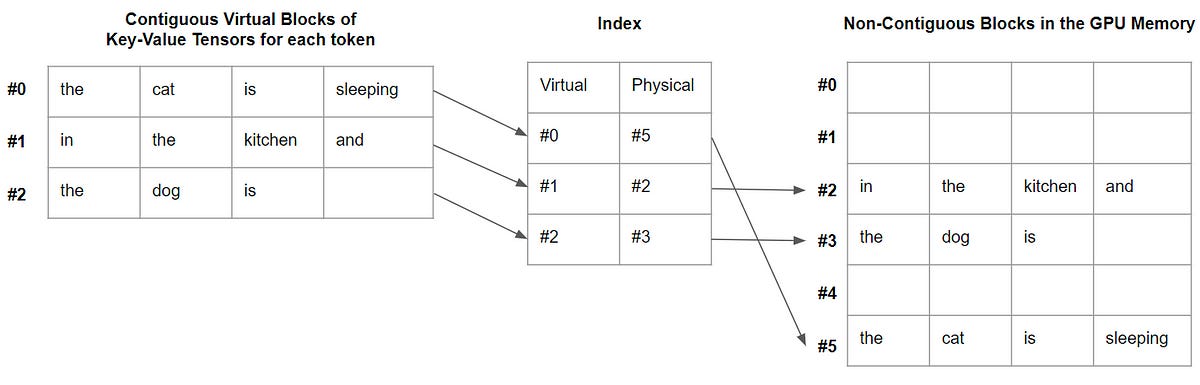
Almost all the large language models (LLM) rely on the Transformer neural architecture. While this architectu…
Almost all the large language models (LLM) rely on the Transformer neural architecture. While this architectu…