


The Weekly Kaitchup #95
Qwen3 Embeddings/Reranker - Packing Improved - Unsloth's Notebooks - SGLang vs. vLLM


Hi Everyone,
In this edition of The Weekly Kaitchup:
Qwen3 Embeddings and Reranker
Packing without Cross-Contamination
Unsloth’s Fine-Tuning Notebooks
SGLang vs. vLLM? They Perform the Same
Qwen3 Embeddings and Reranker
The Qwen team released two new series of models based on Qwen3:
Qwen3 embeddings are production-ready for a wide range of retrieval and semantic matching tasks. You can use them for dense passage retrieval, semantic search, cross-lingual search, duplicate detection, clustering, and even code search across programming languages. When paired with the reranker models, which use a cross-encoder to assess relevance between text pairs, you get a powerful two-stage retrieval pipeline that excels in both recall and precision. This makes the series ideal for deployment in search engines, recommendation systems, or as part of RAG stacks for LLM-based chat applications.
Architecturally, the models are built on Qwen3, using dual-encoder embedding and cross-encoder reranking configurations. Embeddings are extracted from the final [EOS] token’s hidden state (a standard), and rerankers directly score text pairs. Embedding models support custom vector dimensions and are instruction-aware, making them flexible.
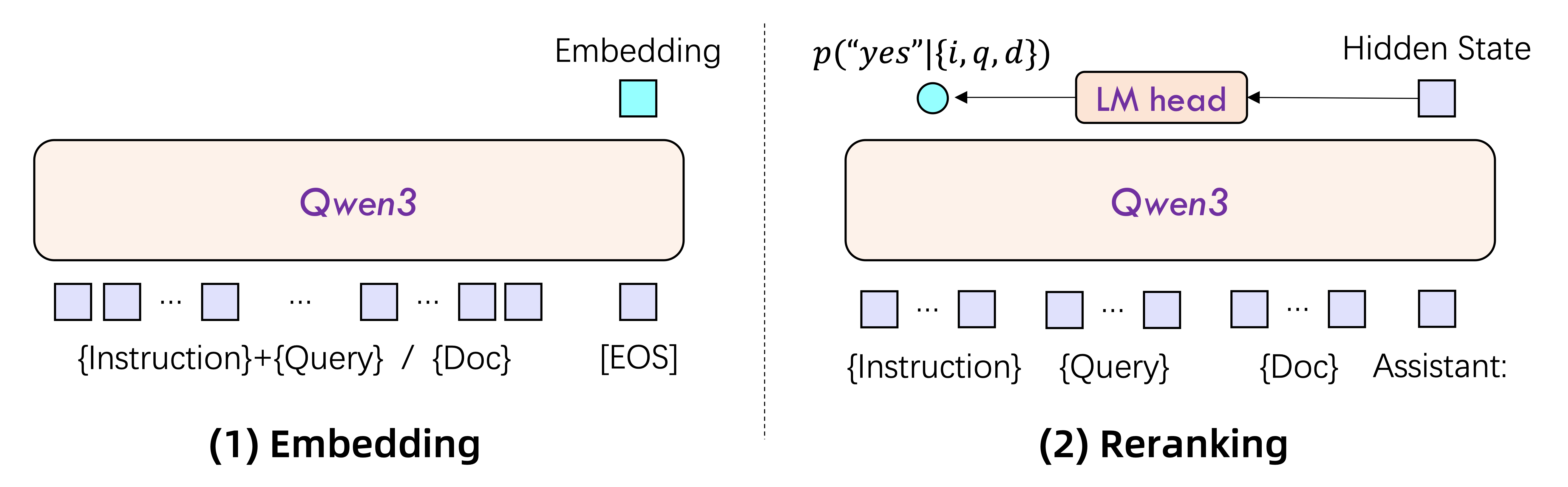
Training-wise, the embedding models follow a three-stage recipe: massive weakly supervised contrastive learning, supervised fine-tuning on curated labels, and model merging for ensemble-style robustness.
They used Qwen3’s own generation capabilities to create weak supervision data dynamically via multi-task prompt generation, avoiding noisy community-mined datasets. Rerankers skip the weak stage entirely and are directly trained on high-quality labeled pairs for better efficiency. All models support 32K tokens and scale up to 8B parameters.
I’m planning to write an article covering their usage, maybe for next week.
source: Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Packing without Cross-Contamination
A few days ago, I published an article comparing three batching strategies for supervised fine-tuning: standard padding, padding-free, and sequence packing.

Packing stood out as an efficient alternative but came with a major caveat: cross-contamination. Since multiple training examples are concatenated into a single token sequence, unrelated examples can end up leaking into each other’s context, which defeats the purpose of clean supervision. In contrast, the padding-free method turned out to be both the fastest and cleanest, avoiding contamination entirely.
However, this week brought an interesting update: TRL introduced a smarter packing implementation that uses FlashAttention.
It can efficiently detect training example boundaries within packed sequences and apply attention masks to prevent the model from seeing tokens outside of the current example. In other words, it solves the contamination issue by enforcing per-example isolation at the attention level, even when multiple examples share the same input sequence.
Early results suggest that training with packing enabled (and now masked correctly) works better.

The documentation shows how to enable it in SFTConfig:
packing (
bool, optional, defaults toFalse) — Whether to group multiple sequences into fixed-length blocks to improve computational efficiency and reduce padding. Usesmax_lengthto define sequence length.packing_strategy (
str, optional, defaults to"ffd") — Strategy for packing sequences. Can be either"ffd"(first-fit decreasing, default), or"wrapped".padding_free (
bool, optional, defaults toFalse) — Whether to perform forward passes without padding by flattening all sequences in the batch into a single continuous sequence. This reduces memory usage by eliminating padding overhead. Currently, this is only supported with theflash_attention_2attention implementation, which can efficiently handle the flattened batch structure. When packing is enabled with strategy"ffd", padding-free is enabled, regardless of the value of this parameter.
It’s a step forward, but I still lean toward padding-free over this new FlashAttention-based “FFD” packing strategy, mainly to avoid the downside of truncating a large number of examples. Padding-free keeps the data intact and avoids introducing variance from overly aggressive sequence limits. Plus, it doesn't force you to re-tune fine-tuning hyperparameters like learning rate or batch size, which can shift subtly with packing. That said, if you're working with a high max sequence length (e.g., 8K or 32K), packing with FFD becomes more attractive, since the risk of truncation drops and you can fully exploit the model's capacity while maintaining clean supervision.
Unsloth’s Fine-Tuning Notebooks
If you want to master supervised fine-tuning and preference optimization (with and without RL), I recommend experimenting with Unsloth’s numerous notebooks.
GitHub: unslothai/notebooks/
I think they’re one of the best learning tools, especially since Unsloth is designed to run efficiently on consumer-grade hardware.
They cover:
Tool-calling, Classification, Synthetic data
Architecture: BERT, TTS, Vision LLMs
Methods: GRPO, DPO, SFT, CPT
Data preparation, evaluation, and inference
LLMs: Llama, Qwen, Gemma, Phi, DeepSeek
That said, don’t expect every notebook to work flawlessly; some are old and broken. Speaking from experience, maintaining over 100 notebooks and ensuring they all stay functional is a serious challenge (honestly, it could be a full-time job on its own). The good news is that most issues are easy to fix, and the Unsloth team is quick to respond. If you open an issue on their GitHub repo, they’re usually fast at pushing a fix.
SGLang vs. vLLM? They Perform the Same
I just read this, so I’ll only write a few words:
LLM Engines: An Executive Summary
Performance-wise, vLLM and SGLang are strikingly similar across a wide range of models (from a few billion to nearly a trillion parameters) and sequence lengths (1K–10K tokens). Benchmark plots show near-identical throughput during batch inference, making it clear that raw performance alone shouldn’t be the deciding factor.
vLLM still has more features, but SGLang is quickly catching up.
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I also reviewed in The Weekly Salt:

⭐Taming LLMs by Scaling Learning Rates with Gradient Grouping
Are Reasoning Models More Prone to Hallucination?
On-Policy RL with Optimal Reward Baseline
Support The Kaitchup by becoming a Pro subscriber:
What You'll Get
Priority Support – Fast, dedicated assistance whenever you need it to fine-tune or optimize your LLM/VLM. I answer all your questions!
Lifetime Access to All the AI Toolboxes – Repositories containing Jupyter notebooks optimized for LLMs and providing implementation examples of AI applications.
Full Access to The Salt – Dive deeper into exclusive research content. Already a paid subscriber to The Salt? You’ll be refunded for the unused time!
Early Access to Research – Be the first to access groundbreaking studies and models by The Kaitchup.
30% Discount for Group Subscriptions – Perfect for teams and collaborators.
The Kaitchup’s Book – A comprehensive guide to LLM fine-tuning. Already bought it? You’ll be fully refunded!
All Benefits from Regular Kaitchup Subscriptions – Everything you already love, plus more. Already a paid subscriber? You’ll be refunded for the unused time!
How to Subscribe?
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!