


The Weekly Kaitchup #79
DeepScaleR-1.5B-Preview - TULU 3.1 - OpenR1 Math


Hi Everyone,
In this edition of The Weekly Kaitchup:
DeepScaleR-1.5B-Preview: Reasoning with Small Models
TULU 3.1: GRPO Update!
OpenR1 Math
AI Toolboxes Update
I've added a new quantization notebook to the Qwen2.5 and Llama 3 toolboxes showing how to quantize with GPTQModel. This framework is not a good option for quantizing very large models (>70B parameters; consumes too much CPU RAM) but is very efficient and fast for quantizing smaller models to 3-bit and 4-bit.
A GRPO notebook is also coming soon! Each toolbox now includes nearly 20 notebooks covering fine-tuning, post-training, quantization, and serving LLMs.
DeepScaleR-1.5B-Preview: Reasoning with Small Models
This week, we explored with s1 how reasoning in LLMs can be unlocked simply by selecting the right dataset and applying budget-forcing during inference.

Efforts to enhance reasoning in different scenarios are ongoing, and DeepScaleR-1.5B-Preview is another interesting development in this space.
DeepScaleR-1.5B-Preview is a smaller-scale reasoning model that demonstrates strong performance without requiring extensive computational resources. It was trained on 40,000 high-quality math problems with a total compute cost of $4,500, significantly lower than typical large-scale models.
Instead of relying on large-scale GPU clusters, the training process used an incremental approach, gradually increasing the model’s context length from 8K to 24K to improve efficiency.
The dataset:
This stepwise process allowed the model to improve reasoning efficiency before tackling longer, more complex problems, ultimately outperforming OpenAI’s o1-preview. The training strategy was all about balance. Initially, the model trained with an 8K context, leading to faster improvements in reasoning ability. When accuracy gains started to plateau, they extended the context to 16K and later 24K, allowing the model to solve harder problems without wasting computational resources. This approach worked remarkably well, as DeepScaleR-1.5B-Preview surpassed larger models in multiple math benchmarks, proving that well-optimized RL can make smaller models punch above their weight.
The model:
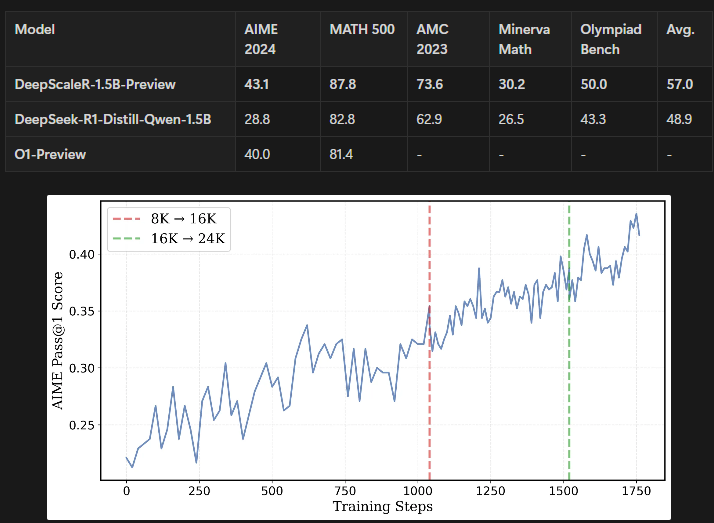
source: DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL
TULU 3: GRPO Update!
I’m a big fan AI2’s work on TULU 3. They over-deliver and continue to update the model and their findings.

To create TULU 3, AI2 post-trained Llama 3.1 using a multi-step process: supervised fine-tuning, followed by Direct Preference Optimization (DPO) and reinforcement learning with verifiable rewards (RLVR). For the last step, they initially used Proximal Policy Optimization (PPO), a well-known but computationally expensive and slow-learning algorithm.
The idea of reinforcement learning with verifiable rewards gained significant traction after the success of DeepSeek-R1, which used GRPO instead of PPO for this step.

Following this trend, AI2 conducted experiments and ultimately replaced PPO with GRPO in their training pipeline.
They have shared their model, learning curves, and training commands here:

TULU 3.1 outperforms TULU 3 on almost all the benchmarks they tried:

OpenR1 Math
Hugging Face released a huge dataset of DeepSeek R1 mathematical reasoning traces:
The dataset contains 516,000 math problems, each with an average of two solutions per problem. It also includes a correctness label (a Boolean), which could be particularly useful for reinforcement learning with verifiable rewards.
It will be interesting to see how well models trained on this dataset perform. Effectively leveraging such a large number of examples poses a challenge, especially as growing evidence suggests that reasoning in LLMs can be activated with as few as a few thousand training examples.
GPU Selection of the Week:
To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
NVIDIA RTX 50XX GPUs are officially released but already sold out, as expected. I won’t track their prices until I can find them at a “reasonable” price.
Even the 40xx series is unaffordable now.

RTX 4090 (24 GB): None at a reasonable price.
RTX 4080 SUPER (16 GB): None at a reasonable price.
RTX 4070 Ti SUPER (16 GB): None at a reasonable price.
RTX 4060 Ti (16 GB): INNO3D nVidia GeForce RTX 4060 Ti TWIN X2 OC 16GB

The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

⭐LIMO: Less is More for Reasoning
Demystifying Long Chain-of-Thought Reasoning in LLMs
UltraIF: Advancing Instruction Following from the Wild
Support The Kaitchup by becoming a Pro subscriber:
What You'll Get
Priority Support – Fast, dedicated assistance whenever you need it to fine-tune or optimize your LLM/VLM. I answer all your questions!
Lifetime Access to All the AI Toolboxes – Repositories containing Jupyter notebooks optimized for LLMs and providing implementation examples of AI applications.
Full Access to The Salt – Dive deeper into exclusive research content. Already a paid subscriber to The Salt? You’ll be refunded for the unused time!
Early Access to Research – Be the first to access groundbreaking studies and models by The Kaitchup.
30% Discount for Group Subscriptions – Perfect for teams and collaborators.
The Kaitchup’s Book – A comprehensive guide to LLM fine-tuning. Already bought it? You’ll be fully refunded!
All Benefits from Regular Kaitchup Subscriptions – Everything you already love, plus more. Already a paid subscriber? You’ll be refunded for the unused time!
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!