


The Weekly Kaitchup #78
s1 - SmolLM2 Trainig Recipe - TULU 3 405B


Hi Everyone,
In this edition of The Weekly Kaitchup:
Test-Time Scaling with Budget Forcing and Short SFT
The Training Recipe of SmolLM2
TULU 3 405B
Test-Time Scaling with Budget Forcing and Short SFT
In this paper, the authors demonstrate that unlocking reasoning abilities in LLMs can be straightforward:
A model fine-tuned on just 1,000 carefully curated reasoning samples (s1K) demonstrates strong reasoning capabilities. This suggests that scaling reasoning abilities in LLMs does not necessarily require massive datasets or extensive training.
They also show how to improve inference-time reasoning through budget forcing, which delays the generation of the EOS token. This allows for greater flexibility in reasoning and improves accuracy by encouraging the model to take more computational steps before finalizing its response. Moreover, injecting ‘wait’ tokens during inference further refines the model’s reasoning process.

The resulting s1-32B model (Qwen2.5 32B fine-tuned on 1K samples) demonstrates effective test-time scaling with minimal computational cost. It requires 26 minutes of training on 16 H100 GPUs. Note: I’ll have a closer look at this. It seems excessively long and costly. They may have done full fine-tuning with 32-bit optimizer states and without gradient checkpointing.
No reinforcement learning is involved; the approach relies purely on supervised fine-tuning (SFT) with modified decoding steps.
Beyond dataset curation, the method is straightforward to implement in any inference framework and is broadly applicable to various models, making it an accessible and adaptable strategy for enhancing LLM reasoning.
We will experiment with it next week!
The Training Recipe of SmolLM2
SmolLM2 are small language models developed by Hugging Face. They published their technical report:
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Most of this recipe's success appears to stem from the careful selection of training samples and their strategic step-by-step utilization during fine-tuning.

Stage 1 (0-6T tokens):
The model’s first phase of pretraining focuses on English web and code data, using a 60/40 FineWeb-Edu to DCLM ratio to balance educational content and real-world Q&A-style text. Code data (StarCoderData) makes up 10% of the mixture. No math data is included yet due to the relatively small size of the math datasets. After 6T tokens of training, the model meets expectations on knowledge and reasoning benchmarks but shows underwhelming coding and math performance.Stage 2 (6T-8T tokens):
To address the coding gap, code data was increased to 20%, and OWM (a math dataset) was introduced at 5% to gradually introduce mathematical reasoning.Stage 3 (8T-10T tokens):
This phase doubled math data to 10% while adjusting the English web data ratio (40% FineWeb-Edu, 60% DCLM) for better multiple-choice reasoning. Code data was refined by replacing StarCoderData with Stack-Edu, and Jupyter Notebooks were introduced for better programming context.Stage 4 (10T-11T tokens, Decay Phase):
In the final stage, the learning rate was gradually decayed to zero, and higher-quality math datasets (InfiWebMath-3+, FineMath 4+) were introduced, increasing math data to 14% of the mixture. Stack-Edu was expanded for broader programming coverage, coding data rose to 24%, and Cosmopedia v2 (high-quality synthetic texts) was added.
TULU 3 405B
The TULU 3 models are developed by AI2. They are based on Llama 3.1 and post-trained in 3 steps:
Supervised fine-tuning
Preference optimization with DPO
Reinforcement learning with verifiable rewards (RLVR)

To the best of my knowledge, they were the first to demonstrate that RL with verifiable rewards can significantly enhance model performance on tasks where answer accuracy can be precisely verified. RLVR also contributed to the success of DeepSeek R1, though DeepSeek AI opted for GRPO while TULU 3 used PPO.
The TULU 3 models were initially released for Llama 3.1 in 8B and 70B variants. Last week, AI2 expanded the lineup by releasing a 405B version. Their evaluation results further validate the effectiveness of their post-training approach, demonstrating significant performance gains:

The model is here:
To post-train Llama 3.1 405B with RLVR, AI2 used vLLM for inference, running on 16 GPUs (two nodes), which I assume were H100s. For training, they deployed 14 GPU nodes, leveraging substantial computational resources to post-train the model effectively.
The TULU 3 recipe does not incorporate any quantization or PEFT methods like LoRA; it relies entirely on full-model fine-tuning. One of my projects this month (if I can find the time) is to replicate this recipe while introducing quantization and LoRA adapters instead of training the entire model. This modification could significantly reduce computational costs while maintaining strong performance.
For Llama 3.1 8B, I estimate the cost to be under $100, while the 70B model should remain below $1,000—orders of magnitude cheaper than the original TULU 3 training process.
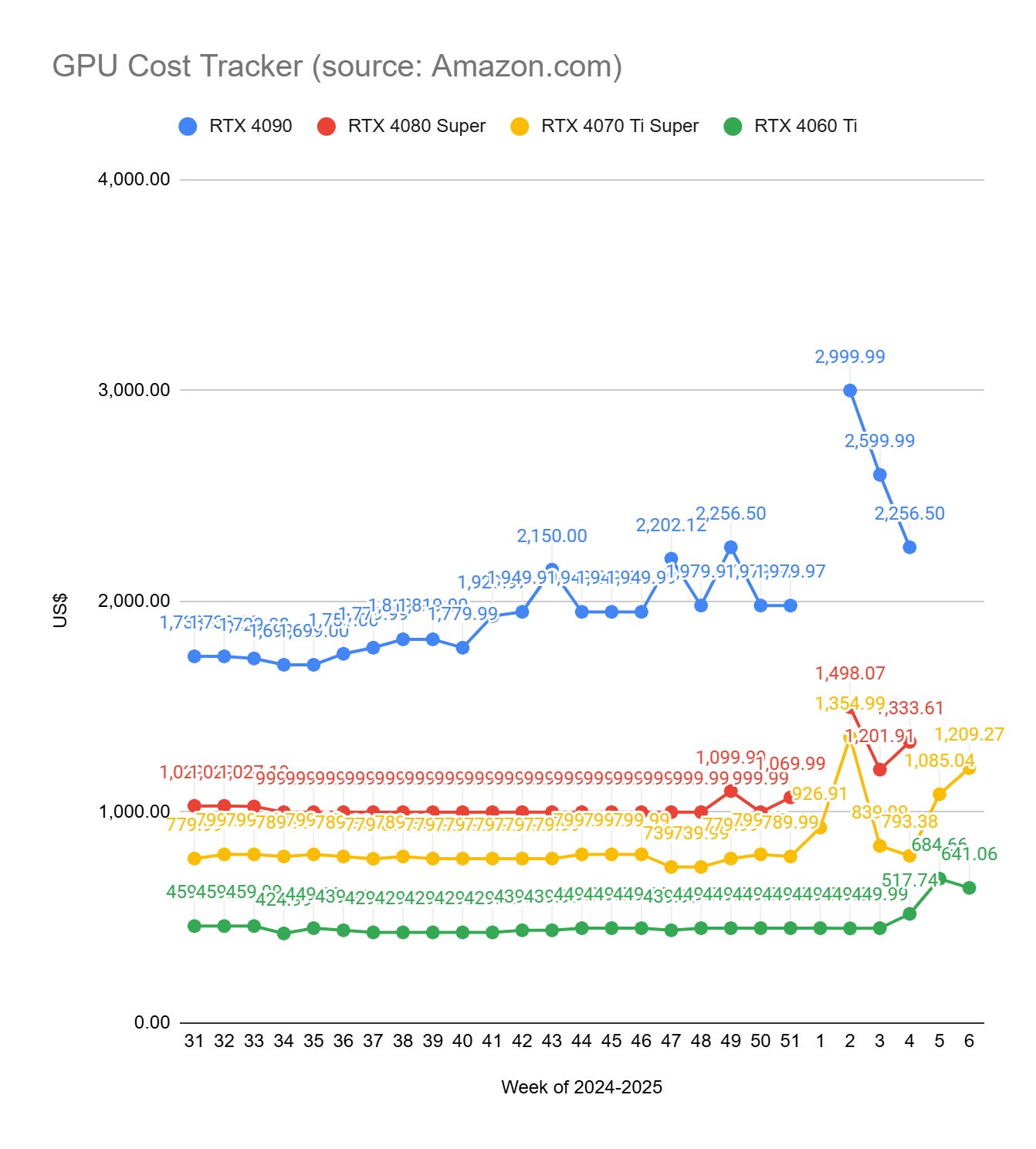
GPU Selection of the Week:
To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
NVIDIA RTX 50XX GPUs are officially released but already sold out, as expected. I won’t track their prices until I can find them at a “reasonable” price.
Even the 40xx series is unaffordable now.

RTX 4090 (24 GB): None at a reasonable price.
RTX 4080 SUPER (16 GB): None at a reasonable price.
RTX 4070 Ti SUPER (16 GB): INNO3D nVidia GeForce RTX 4070 Ti Super Twin X2 16GB GDDR6X
RTX 4060 Ti (16 GB): ASUS Dual GeForce RTX 4060 Ti EVO OC Edition 16GB GDDR6
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

⭐Optimizing Large Language Model Training Using FP4 Quantization
Low-Rank Adapters Meet Neural Architecture Search for LLM Compression
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
Support The Kaitchup by becoming a Pro subscriber:
What You'll Get
Priority Support – Fast, dedicated assistance whenever you need it to fine-tune or optimize your LLM/VLM. I answer all your questions!
Lifetime Access to All the AI Toolboxes – Repositories containing Jupyter notebooks optimized for LLMs and providing implementation examples of AI applications.
Full Access to The Salt – Dive deeper into exclusive research content. Already a paid subscriber to The Salt? You’ll be refunded for the unused time!
Early Access to Research – Be the first to access groundbreaking studies and models by The Kaitchup.
30% Discount for Group Subscriptions – Perfect for teams and collaborators.
The Kaitchup’s Book – A comprehensive guide to LLM fine-tuning. Already bought it? You’ll be fully refunded!
All Benefits from Regular Kaitchup Subscriptions – Everything you already love, plus more. Already a paid subscriber? You’ll be refunded for the unused time!
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!