


The Weekly Kaitchup #74
Open Phi-4 - OLMo 2 Paper


Hi Everyone,
In this edition of The Weekly Kaitchup:
Phi and the MIT licenses
OLMo 2 Paper: What Do We Learn?
Phi and the MIT licenses
Microsoft released Phi-4 last month. I reviewed the model here:

Phi-4 is great for most tasks, but it’s not the best when it comes to following strict instructions. For instance, if you need it to generate output in a specific format you’ve defined in the prompt, it might completely ignore that and generate its answer in a completely different format.
Another downside was the licensing. The model was only officially available through Microsoft Azure, and the license didn’t allow commercial use. Microsoft mentioned they’d release it on the Hugging Face Hub a week later.
It finally took one month. The model is here:
They switched the license to an MIT license, which now allows you to use Phi-4 for commercial purposes.
It’s unclear why Microsoft takes this approach. They’ve done the same with earlier Phi models: starting with a restrictive license and then, a few weeks later, switching to a more open one.
There are a couple of possible reasons for this:
They might want to gauge whether a model like Phi-4 drives more Azure subscriptions or usage before fully opening it up.
The Phi-4 team might need to navigate multiple internal processes before releasing a model under a more permissive license. This could involve additional checks by their IP and legal departments.
Nonetheless, we are all happy to have one more good Phi model.
OLMo 2 Paper: What Do We Learn?
AI2 released several open LLMs towards the end of 2024. We had the TULU 3 models for which they applied a new post-training recipe on Llama 3.1 models. I reviewed them for The Salt:


They also released the OLMo 2 models that they pre-trained from scratch. They publish their pre-training and post-training recipes this week in this paper:
As usual, this paper from AI2 is very informative
The training itself was split into two key stages. First, there’s the pre-training phase, which used a massive amount of web-sourced data to establish a broad knowledge base. Then came the mid-training phase, which was more targeted. This stage introduced high-quality data and synthetic datasets.
What’s particularly new and interesting here is how the training process was refined to avoid common pitfalls. For example, they adjusted the way the model initializes, opting for a new method that keeps things more stable as the model learns. They also reworked the learning rate schedules, incorporating a gradual warm-up phase followed by a tapered reduction to ensure smoother and more stable training.
They didn’t try a schedule-free optimizer:

Another big change was in how certain layers of the model handle outputs and normalize data. By tweaking these details—like switching to RMSNorm and reordering some computations—they reduced instability and kept the training process more consistent.
Data was another area where they brought in fresh ideas. They filtered out patterns in the training data that could cause spikes in training loss, such as repeated sequences of words or symbols. This might seem minor, but these changes significantly improved how the model handled the data without getting tripped up.
On top of all this, the team leaned into a concept called "micro-annealing" during the mid-training phase. Instead of just running the model once with the same data, they ran multiple iterations with slight changes in data order and then averaged the results. This approach helped the model settle into a better "solution" during training.
Overall, what’s new isn’t just one big flashy feature, it’s the collection of smaller, thoughtful improvements over OLMo (the first) that come together to make the training process smoother, more stable, and more effective.
If you don’t know what to read this weekend, read the OLMo 2 paper!
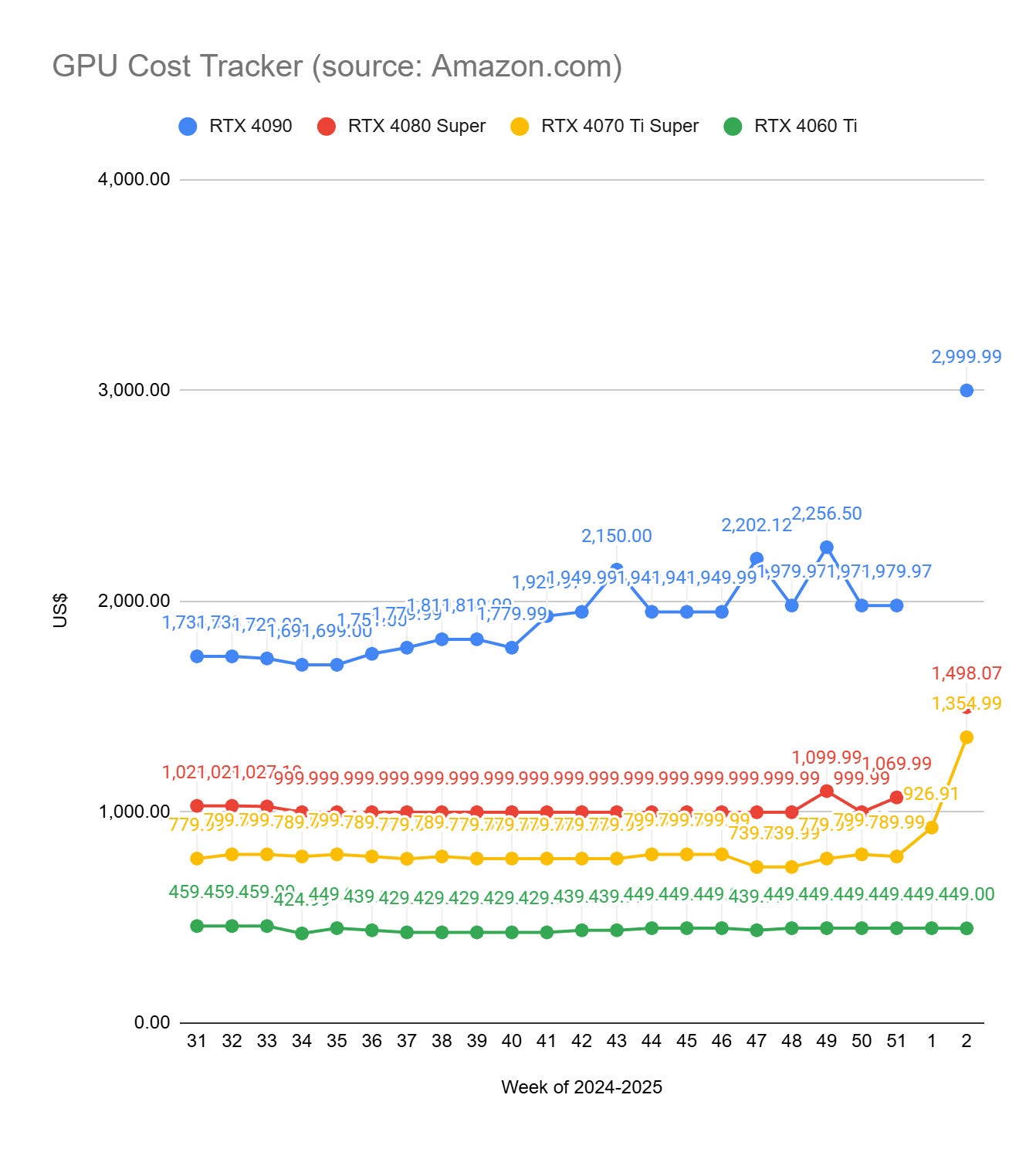
GPU Selection of the Week:
To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
With NVIDIA's announcement of the RTX 50 series, all the RTX 4090/4080/4070 became unaffordable. Since an RTX 5060 wasn’t announced, the RTX 4060 remains at the same price.

RTX 4090 (24 GB): Zotac NVIDIA GeForce RTX 4090 AMP Extreme AIRO 24GB GDDR6X
RTX 4080 SUPER (16 GB): MSI GeForce RTX 4080 16GB Gaming X Trio
RTX 4070 Ti SUPER (16 GB): MSI GeForce RTX 4070 Ti Super 16G Expert
RTX 4060 Ti (16 GB): Asus Dual GeForce RTX™ 4060 Ti EVO OC Edition 16GB

The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

⭐Understanding and Mitigating Bottlenecks of State Space Models through the Lens of Recency and Over-smoothing
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Support The Kaitchup by becoming a Pro subscriber:
What You'll Get
Priority Support – Fast, dedicated assistance whenever you need it to fine-tune or optimize your LLM/VLM. I answer all your questions!
Lifetime Access to All the AI Toolboxes – Repositories containing Jupyter notebooks optimized for LLMs and providing implementation examples of AI applications.
Full Access to The Salt – Dive deeper into exclusive research content. Already a paid subscriber to The Salt? You’ll be refunded for the unused time!
Early Access to Research – Be the first to access groundbreaking studies and models by The Kaitchup.
30% Discount for Group Subscriptions – Perfect for teams and collaborators.
The Kaitchup’s Book – A comprehensive guide to LLM fine-tuning. Already bought it? You’ll be fully refunded!
All Benefits from Regular Kaitchup Subscriptions – Everything you already love, plus more. Already a paid subscriber? You’ll be refunded for the unused time!
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!