


The Weekly Kaitchup #72
Falcon 3 - Apollo-LMMs - Qwen2.5 report


Hi Everyone,
In this edition of The Weekly Kaitchup:
Falcon 3: The New Best LLMs for Consumer Hardware?
Apollo-LMMs: Promising Models for Long Video Understanding
Qwen2.5: The Technical Report
Next Week's Schedule Update
Next week, I’ll be publishing only one article, likely on Monday. Exceptionally, there won’t be a Weekly Kaitchup on Friday unless there’s major AI news—though that’s unlikely given the time of year.
Falcon 3: The New Best LLMs for Consumer Hardware?
The Technology Innovation Institute (TII) in Abu Dhabi is well-known for its Falcon models. When the first Falcon was released last year, it was considered the best 7B model for a few months until Meta introduced Llama 2. On the other hand, the launch of Falcon 2 in May 2023 coincided with the widespread adoption of the extremely good and well-marketed Llama 3, overshadowing its release. Falcon 2 didn’t stay long in the “trending” models on Hugging Face.
This week, TII released Falcon 3, months after Meta's Llama 3.2 and Alibaba's Qwen2.5.
Hugging Face Collection: Falcon3
The models look very good. If tech giants like Google, Meta, or Alibaba don’t release new open models soon, Falcon 3 has the potential to dominate the sub-10B parameter space for some time.
According to TII’s evaluation, Falcon 3 outperforms Qwen2.5 of a similar size in most benchmarks.

source: Welcome to the Falcon 3 Family of Open Models!
While TII also released quantized versions of the Falcon 3 models, they didn’t leverage state-of-the-art quantization techniques. After quantizing the 7B and 10B models myself, I achieved noticeably better results than the official “GPTQ-int4” versions. You can get my models here:
Hugging Face Collection: Quantized Falcon3


I’m publishing these models for free. If you’d like to support my work and help me continue releasing improved models, consider subscribing to The Kaitchup.
Falcon 3 follows the Llama architecture, making it easy to fine-tune, quantize, run, or deploy the models using my Llama Toolbox.
When fine-tuning, you don’t need to set a custom pad token because the tokenizer already includes one—a rarity among LLM tokenizers nowadays. However, the developers followed Hugging Face’s guidelines, which recommend including the chat template only in the tokenizer of the instruct model.
I’m not a fan of this approach because it complicates fine-tuning the base model for chat applications. Specifically, you need to load the tokenizer from the instruct model rather than the tokenizer of the base model you’re fine-tuning. Meta adopted a similar approach with Llama 3.1 and 3.2. On the other hand, Qwen2.5 took a better route (in my opinion…) by including the chat template in the tokenizer of the base and instruct models.
Apollo-LMMs: Promising Models for Long Video Understanding
Meta (or, let’s say, someone working for Meta) recently unveiled its Apollo-LMMs, a series of models that appear to excel in video understanding. The models are described here:
Apollo: An Exploration of Video Understanding in Large Multimodal Models
However, the release raised several questions.
Firstly, the models were not published in an official Meta repository on Hugging Face or GitHub, which is unusual for such a high-profile release.
Secondly, the models use the Qwen LLM backbone instead of Meta's own Llama architecture. While it’s widely recognized that Qwen2.5 currently outperforms Llama 3.1, it’s surprising to see Meta adopting an external model for such a significant project.
However, just hours after their release, the GitHub repository went offline (now it’s back but without code), and the models were removed from Hugging Face. This abrupt removal suggests that the team at Meta likely released the models prematurely, without securing all necessary internal approvals.
This isn’t the first time something like this has happened. Earlier this year, Microsoft faced a similar situation with the release of WizardLM 2. The models, which also showed great promise, were pulled just a few hours after going public. The team later admitted that the release had bypassed some of their internal review processes.
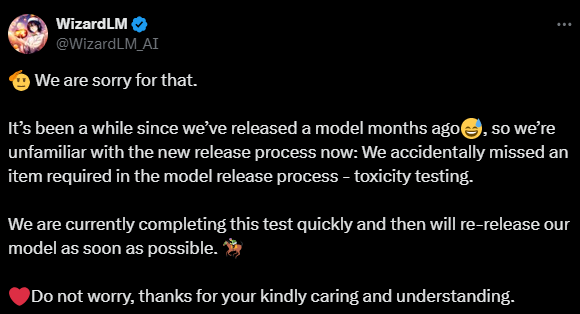
WizardLM 2 was never officially released—was the model deemed too “toxic”?
Note: Initially, I planned to briefly review the Apollo models and their impressive capabilities for this Weekly Kaitchup. These models are compact yet appear to perform exceptionally well with very long, movie-like videos. However, I chose not to, as it remains uncertain whether Meta will re-release them officially. While copies of the models are floating around, I would advise caution when using them. The licensing situation is unclear, and without an official release, it’s hard to determine the legal or ethical boundaries of their use.
Qwen2.5: The Technical Report
The Qwen team delivered one last gift before the end of the year: the highly anticipated Qwen2.5 technical report.
This is a very recent publication, so I haven’t had time for an in-depth review. At first glance, there’s nothing groundbreaking in the methodology behind the development of the best LLMs we currently have. The pre-training and supervised fine-tuning stages appear fairly standard. For the alignment with human preferences, the preference optimization stage uses a combination of offline and online reinforcement learning (RL).
For offline RL, they used Direct Preference Optimization (DPO). However, I’m unclear on why they classify this as RL, as DPO is not typically considered a reinforcement learning algorithm. For online RL, they implemented Group Relative Policy Optimization (GRPO).
Given the standard nature of the recipe, it suggests that Qwen2.5’s strong performance is primarily due to its pre-training data mix. Unfortunately, the details on this are sparse. They mention curating 18 trillion tokens, a well-balanced mix of synthetic, code, and organic datasets, which likely contribute significantly to the model’s capabilities.

Now, we have very high expectations for Qwen3.
New Toolbox Release: Podkaister
I’ve also released a toolbox replicating NotebookLM’s podcast generator, built using open models. It runs efficiently on a single GPU, e.g., using Google Colab’s L4 GPU. While generating the podcast transcript is straightforward and can still be enhanced with prompt engineering, achieving natural-sounding speech remains a challenge with current open TTS models. One persistent issue is that the voices sometimes change randomly during the podcast. Due to these limitations and the fact that this toolbox is still a work in progress, it’s available exclusively to The Kaitchup Pro subscribers. You can find the toolbox here. Unlike my other toolboxes, it is not available as a standalone purchase for now.
GPU Selection of the Week:
To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
RTX 4090 (24 GB): ASUS TUF Gaming GeForce RTX™ 4090 OG
RTX 4080 SUPER (16 GB): ZOTAC Gaming GeForce RTX 4080 Super Trinity OC White Edition DLSS 3
RTX 4070 Ti SUPER (16 GB): GIGABYTE GeForce RTX 4070 Ti Super Gaming OC 16G Graphics Card, 3X WINDFORCE Fans
RTX 4060 Ti (16 GB): Asus Dual GeForce RTX™ 4060 Ti EVO OC Edition 16GB
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week, I published a review of the post-training recipe used by AI2 for the TULU 3 models. While the recipe is undeniably expensive, it offers valuable insights into how hyperparameters and techniques are selected to train such models. I believe the overall cost could be significantly reduced using PEFT techniques and quantization, achieving similar results at a fraction of the expense.

I also reviewed in The Weekly Salt:

If You Can't Use Them, Recycle Them: Optimizing Merging at Scale Mitigates Performance Tradeoffs
⭐Training Large Language Models to Reason in a Continuous Latent Space
I Don't Know: Explicit Modeling of Uncertainty with an [IDK] Token
Support The Kaitchup by becoming a Pro subscriber:
What You'll Get
Priority Support – Fast, dedicated assistance whenever you need it to fine-tune or optimize your LLM/VLM. I answer all your questions!
Lifetime Access to All the AI Toolboxes – Repositories containing Jupyter notebooks optimized for LLMs and providing implementation examples of AI applications.
Full Access to The Salt – Dive deeper into exclusive research content. Already a paid subscriber to The Salt? You’ll be refunded for the unused time!
Early Access to Research – Be the first to access groundbreaking studies and models by The Kaitchup.
30% Discount for Group Subscriptions – Perfect for teams and collaborators.
The Kaitchup’s Book – A comprehensive guide to LLM fine-tuning. Already bought it? You’ll be fully refunded!
All Benefits from Regular Kaitchup Subscriptions – Everything you already love, plus more. Already a paid subscriber? You’ll be refunded for the unused time!
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!