


The Weekly Kaitchup #66
LoRA vs. FFT - Small LM - TRL 0.12.0


Hi Everyone,
In this edition of The Weekly Kaitchup:
LoRA not as Good as Full Fine-Tuning? Yes, but Why?
All You Need to Know about Small Language Models
TRL 0.12.0: More Flexible Online DPO and New Breaking Changes Incoming
If you are a free subscriber, consider upgrading to paid to access 100+ notebooks and more than 200 articles.
LoRA not as Good as Full Fine-Tuning? Yes, but Why?
LoRA fine-tunes an adapter (tensors) on top of the model’s frozen parameters. It is mainly used to reduce the cost of fine-tuning. While the LoRA paper claimed that LoRA could perform on par with full fine-tuning, later research work, and a lot of feedback from the AI industry, have shown otherwise. LoRA is an approximation of full fine-tuning and won’t match or outperform full fine-tuning in most tasks.
What does LoRA learn, exactly?
To best understand why LoRA can’t match full fine-tuning’s performance, a new paper investigates the differences between full fine-tuning and LoRA.
LoRA vs Full Fine-tuning: An Illusion of Equivalence
The study especially focuses on finding whether the solutions learned by LoRA and full fine-tuning are equivalent.
The authors found:
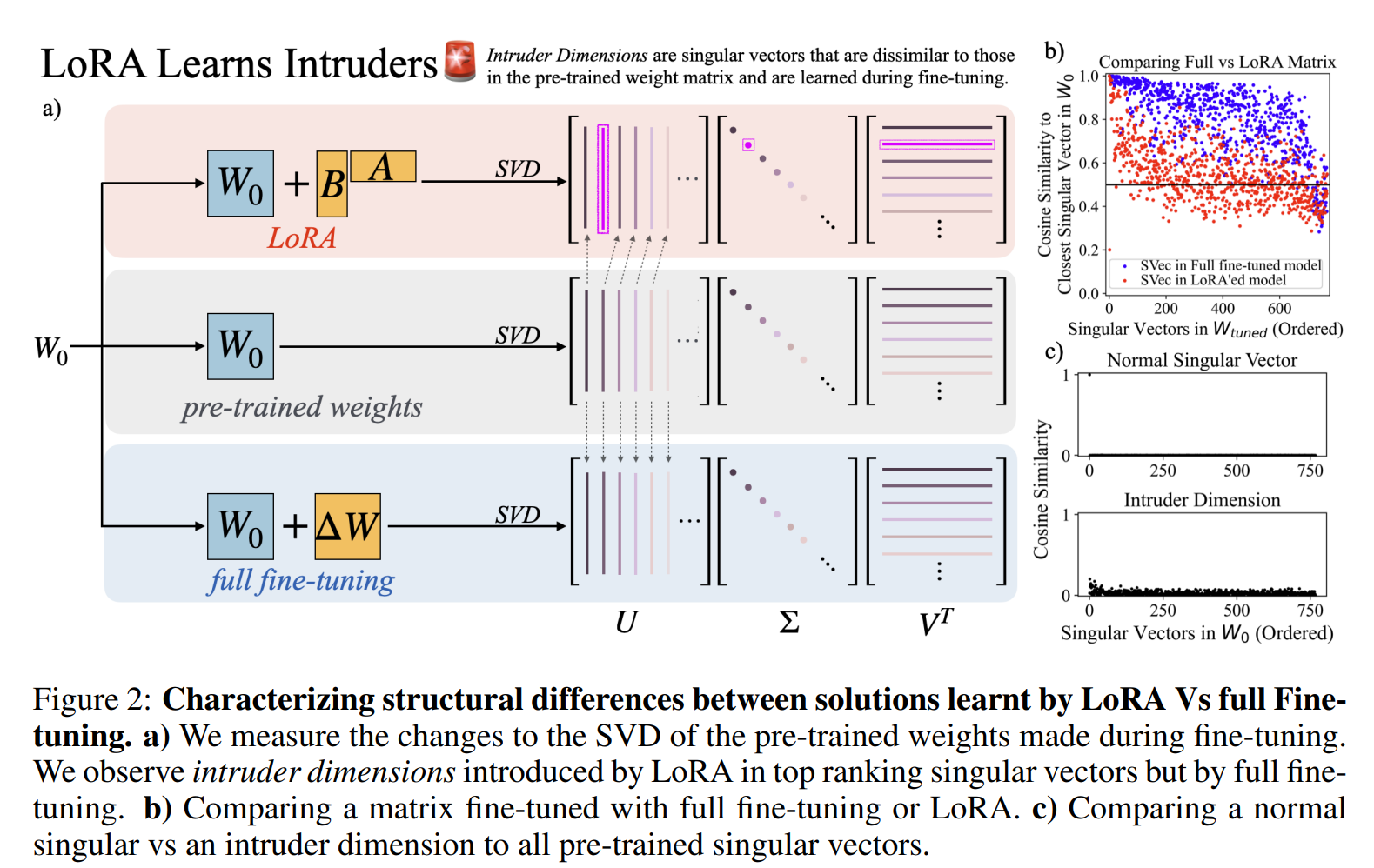
Structural Differences in Parameter Updates: LoRA and full fine-tuning yield distinct structural changes. LoRA introduces “intruder dimensions”—singular vectors that are mostly orthogonal to those in the pre-trained model, diverging from the spectral structure of fully fine-tuned models.
Generalization and Robustness Differences: LoRA-tuned models with intruder dimensions tend to forget more of the original pre-training distribution and show less robust learning outside the target task. In contrast, fully fine-tuned models retain better alignment with the pre-training distribution. LoRA models with higher ranks (or full-rank LoRA) perform better outside the training distribution, although they still experience the trade-off between specificity and generalization.
Benefits of Higher-Rank LoRA: While low-rank LoRA can match full fine-tuning on specific tasks, higher-rank configurations (e.g., r=64) improve generalization and adaptability. To maximize these benefits, however, high-rank LoRA models require rank stabilization to prevent overfitting, i.e., rsLoRA.

I also discuss the difference in the training cost and performance between LoRA and full fine-tuning in the first chapter of The Kaitchup’s book. You can still get the book here with a 30% discount:
All You Need to Know about Small Language Models
With the release of models like Qwen2.5, Llama 3.2, and SmolLM2, we’re seeing a surge in high-performance small language models. These models are good for several reasons, including innovative architectural choices, efficient training techniques, and progress in data quality and curation. But what specific factors make these smaller models so effective, and why are they improving at such a rapid pace?
To address these questions, a new survey has been published by researchers from Pennsylvania State University, UTHealth Houston, and Amazon.
Though it’s a long read, I highly recommend it for anyone frequently working with small language models. The paper is not too complicated and introduces many techniques from scratch for easier understanding.
The authors also cover techniques for downsizing large models, such as pruning and quantization.

TRL 0.12.0: More Flexible Online DPO and New Breaking Changes Incoming
Online DPO has shown better performance than standard DPO for optimizing alignment with human preferences. Supported by TRL for several months, it still falls short in flexibility compared to other trainers in TRL. As of my last test a few weeks ago, training an adapter on a quantized model or using datasets in alternative formats was not yet possible with the online DPO trainer.
With the release of v0.12.0, online DPO has become more adaptable. Now, we can use reward models with a chat template that differs from the one used to train the main model. I'll be testing online DPO again, and if the results are promising, I'll share an article on my findings.
TRL 0.12.0 also brings automatic support for conversational datasets to many more trainers. For instance, popular datasets for preference optimization like mlabonne/orpo-dpo-mix-40k use this format:
[{"role":"user", "content":"Hello!"}, {"role":"assistant", "content":"Hello User!"}]The chat template of the tokenizer is automatically applied to convert it into a sequence of tokens. SFTTrainer was already supporting this functionality. Now, the DPOTrainer and ORPOTrainer, among others also make this conversion.
Be aware also that, once again, TRL is making some changes in the training arguments of the trainers. dataset_text_field is now set to "text" by default. But more importantly, the argument "tokenizer" is replaced with "processing_class"…

"tokenizer" is now deprecated and won’t be supported in the next releases. This will break again many scripts and frameworks. I recommend to start updating your code now.
source: https://github.com/huggingface/trl/releases/tag/v0.12.0
GPU Cost Tracker
This section keeps track, week after week, of the cost of GPUs. It only covers consumer GPUs, from middle-end, e.g., RTX 4060, to high-end, e.g., RTX 4090.
While consumer GPUs have much less memory than GPUs dedicated to AI, they are more cost-effective, by far, for inference with small batches and fine-tuning LLMs with up to ~35B parameters using PEFT methods.

To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
GPU Selection of the Week:
RTX 4090 (24 GB): GIGABYTE GV-N4090AERO OC-24GD GeForce RTX 4090 AERO
RTX 4080 SUPER (16 GB): GIGABYTE GeForce RTX 4080 Super WINDFORCE V2
RTX 4070 Ti SUPER (16 GB): GIGABYTE GeForce RTX 4070 Ti Super WINDFORCE
RTX 4060 Ti (16 GB): Asus Dual GeForce RTX™ 4060 Ti EVO OC Edition 16GB GDDR6

The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week, I wrote about the cost of unnecessary few-shot learning for evaluations. For instance, if you evaluate with MMLU using the standard 5-shot setting, you are likely wasting resources for nothing.

I also reviewed:

⭐Why Does the Effective Context Length of LLMs Fall Short?
Aligning Large Language Models via Self-Steering Optimization
SemiEvol: Semi-supervised Fine-tuning for LLM Adaptation
Can Knowledge Editing Really Correct Hallucinations?
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!