


The Weekly Kaitchup #65
SmolLM2 - Layer Skip - MaskGCT


Hi Everyone,
In this edition of The Weekly Kaitchup:
SmolLM2: Very Good Alternatives to Qwen2.5 and Llama 3.2
Faster Llama Models with Layer Skip
MaskGCT: High-Quality Non-Autoregressive Text-to-Speech
If you are a free subscriber, consider upgrading to paid to access all the notebooks (110+) and more than 200 articles.
My data shows that monthly subscribers are likely to stay subscribed for at least 8 months. If you are on the monthly paid plan, Switch to the yearly plan now and save 40%!
The yearly plan is also now available with a discount if purchased with The Kaitchup’s book, here. Note: I activate this subscription manually so it may take a few hours before you become a paid subscriber this way.
SmolLM2: Very Good Alternatives to Qwen2.5 and Llama 3.2
Hugging Face has doubled down on their SmolLM initiative.

They released SmolLM2: 1.7B, 360M, and 135M models trained on 11T tokens (against 1T for SmolLM). They released based and instruct versions:
Hugging Face Collection: SmolLM2 (Apache 2.0 license)
They used new datasets for pre-training that they will release soon. To make the instruct versions, they used a recipe similar to what they did to train Zephyr (SFT+DPO on ultrafeedback).

It looks like SmolLM2 performs very well:

Note that Hugging Face fully releases the pre-training data and the recipe they used to prevent data contamination. In other words, their published evaluation results are probably accurate and fully reproducible.
Hugging Face used its own framework for pre-training, Nanotron. I’ve never written about Nanotron but I think it’s a very interesting project that deserves to be better known, especially if you are interested in understanding how pre-training is done. I’ll try to find the time to publish an article explaining Nanotron before 2025!
Meta also released a series of small models, MobileLLM:
Hugging Face Collection: MobileLLM (CC-BY-NC)
This is a new release but note that these models are actually quite old. They were trained for this work published in February 2024:
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Faster Llama Models with Layer Skip
Meta introduced Layer Skip (or LayerSkip??) as part of several research advancements from its FAIR (Facebook AI Research) division:
Sharing new research, models, and datasets from Meta FAIR
Layer Skip is a method to make LLMs faster and more efficient. It works by running only some layers of the model while relying on other layers to check and correct the results. The details of these techniques are given in this paper:
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
Layer Skip borrows from layer dropout. Layer dropout randomly skips some layers during training to save computation. The dropout rate increases across layers, making it more likely to skip higher layers. This selective dropout makes faster training since fewer layers are processed, reducing the model’s workload without significantly affecting accuracy according to Meta.
To improve early-layer accuracy, early exit loss supervises predictions at different layers, so the model can exit before reaching the final layer. This helps the model learn to make accurate predictions from earlier layers, which speeds up inference when full-layer processing isn’t necessary.
For inference, the model can exit at a specific layer and produce an output. The model also drafts tokens with early layers and verifies them with later layers in the same model. This avoids the need for the two separate models normally used in speculative decoding. Meta called this technique self-speculative decoding.

Lastly, a cache reuse method saves results from early layers, allowing the model to skip recomputation in verification steps.

Meta released models exploiting this new technique on the Hugging Face Hub (limited license: research purposes only):
Hugging Face Collection: LayerSkip
MaskGCT: High-Quality Non-Autoregressive Text-to-Speech
MaskGCT is a new non-autoregressive Text-to-Speech (TTS) model using masked generative transformers without needing text-speech alignment.
MaskGCT works in two stages: first, it predicts semantic tokens from text, and then it generates acoustic tokens based on these semantic tokens. This is done using a mask-and-predict approach which allows the model to generate speech of various lengths in parallel.

Compared to other existing TTS models, MaskGCT seems to achieve better or comparable results in quality, naturalness, and intelligibility across multiple benchmarks (like LibriSpeech and SeedTTS). It maintains human-level similarity to prompt speech, low error rates, and stable performance over varied speech durations.
I tried it with the demo and it is indeed very good, even in other languages. The authors released code and model (but with a cc-by-nc license):
Hugging Face: amphion/MaskGCT
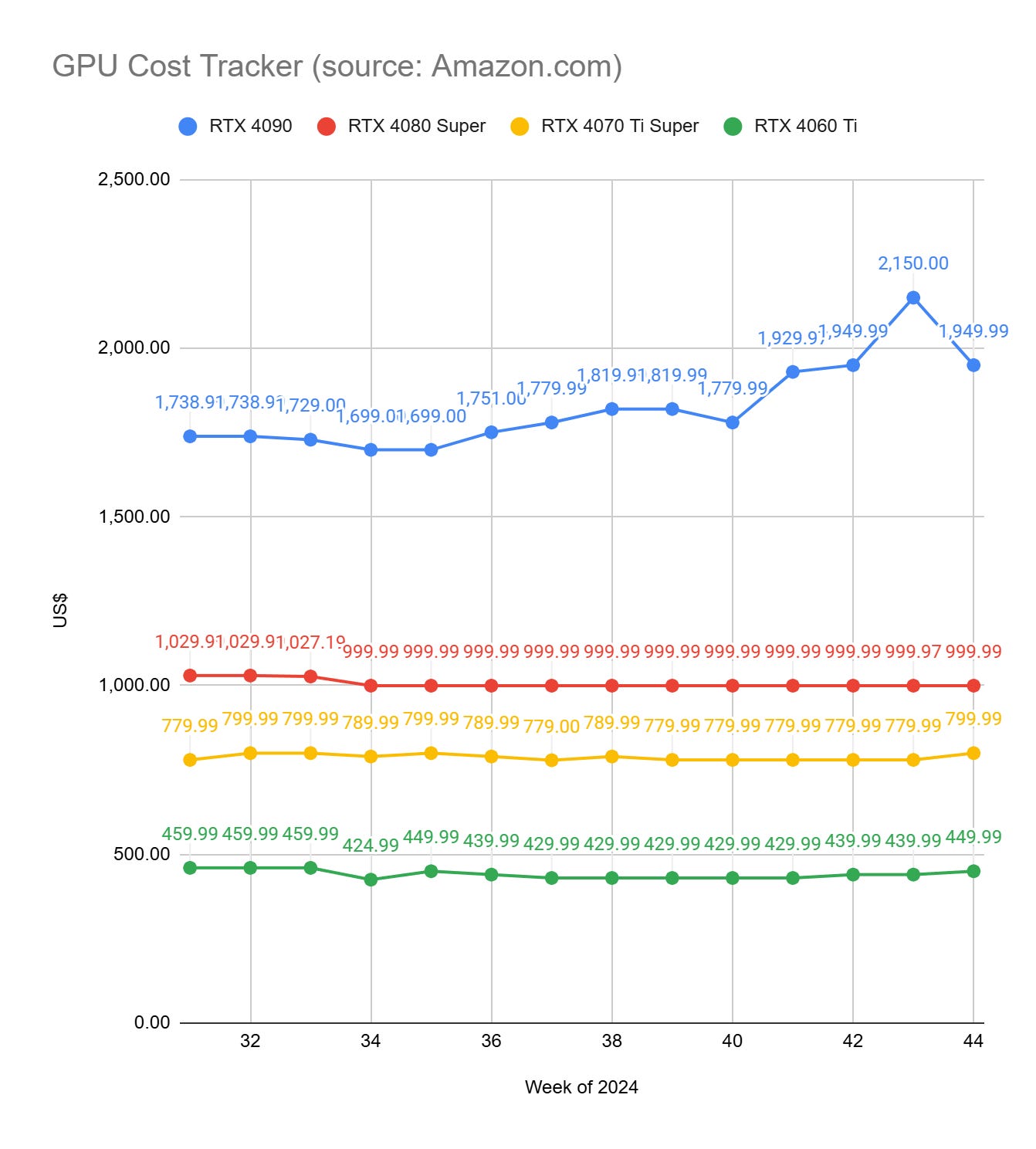
GPU Cost Tracker
This section keeps track, week after week, of the cost of GPUs. It only covers consumer GPUs, from middle-end, e.g., RTX 4060, to high-end, e.g., RTX 4090.
While consumer GPUs have much less memory than GPUs dedicated to AI, they are more cost-effective, by far, for inference with small batches and fine-tuning LLMs with up to ~35B parameters using PEFT methods.

To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
GPU Selection of the Week:
RTX 4090 (24 GB): MSI Gaming GeForce RTX 4090
RTX 4080 SUPER (16 GB): GIGABYTE GeForce RTX 4080 Super WINDFORCE V2
RTX 4070 Ti SUPER (16 GB): GIGABYTE GeForce RTX 4070 Ti Super WINDFORCE
RTX 4060 Ti (16 GB): PNY GeForce RTX™ 4060 Ti 16GB Verto™
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week, I reviewed:
⭐Why Does the Effective Context Length of LLMs Fall Short?
Aligning Large Language Models via Self-Steering Optimization
SemiEvol: Semi-supervised Fine-tuning for LLM Adaptation
Can Knowledge Editing Really Correct Hallucinations?

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!