


The Weekly Kaitchup #5
Reinforced self-training - Falcon 180B - A survey on instruction tuning - BatchPrompt


Hi Everyone,
In The Weekly Kaitchup, I briefly comment on recent scientific papers, new frameworks, tips, open models/datasets, etc. for affordable and computationally efficient AI.
In this edition, we will see:
Reinforced Self-Training (ReST) for LLMs
Falcon 180B: The Best and Biggest Open LLM
Instruction Tuning for Large Language Models: A Survey
BatchPrompt: Accomplish more with less
I’ll publish next week the article detailing the second step for fine-tuning instruct LLMs. We will see how to train the reward model, which is the simplest of the 3 steps. If you missed the first article on supervised fine-tuning with DeepSpeed Chat, you will find it here:

The Kaitchup has now 447 subscribers. Thanks a lot for your support!
Reinforced Self-Training (ReST) for LLMs

In this work by Google DeepMind, the LLM self-trains in 3 steps:
The LLM generates multiple outputs for each prompt to make a synthetic dataset.
A reward model ranks the outputs for each prompt in the synthetic dataset. Only the top n outputs, according to the reward model, are kept in the synthetic dataset.
Then, the filtered synthetic dataset is used to further fine-tune the LLM.
This is an iterative process. After each iteration, the synthetic dataset gets better and improves the LLM.
It reminds me a lot of iterative back-translation (Hoang et al., 2018). This method uses a machine translation system to generate synthetic translations which are then used to retrain the machine translation system. Note: Some of the authors of ReST, such as Caglar Gulcehre and Orhan Firat, have a strong background in machine translation. The experiments in the ReST paper are mainly done with machine translation datasets.
ReST is a much simpler approach than the typical reinforcement learning with human feedback (RLHF). According to the authors’ experiments, several iterations of ReST outperform online RL.
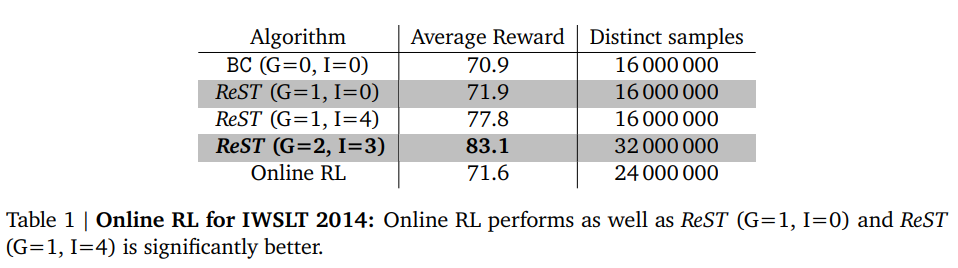
You can find more details in their arXiv paper:
Reinforced Self-Training (ReST) for Language Modeling
Falcon 180B: The Best and Biggest Open LLM
The Falcon models were the best open LLMs for many tasks before Meta released Llama 2. Falcon 40B was the largest of the Falcon LLMs.
TII released a much bigger version: Falcon 180B. It is significantly better than Llama 2 60B and is ranked first on the OpenLLM leaderboard for pre-trained models.
Falcon 180B is trained on 3.5 trillion tokens (RefinedWeb corpus), with 4 times the compute resources of Meta’s Llama 2.
You can download it from the Hugging Face hub:
It is distributed with a license allowing commercial use.
We will find more details in the paper they will publish soon. Note: I was wondering why it was taking so long for them to publish the paper. It was announced as “coming soon“ in May 2023. The reason for this delay is now obvious: They were training/evaluating a much bigger version of the model.
Instruction Tuning for Large Language Models: A Survey
Every month several works on improving instruction tuning for LLMs are published. It’s difficult to keep track of all of them.
Zhang et al. (2023) published a survey that describes and explains recent methods for creating instruction tuning datasets:
Instruction Tuning for Large Language Models: A Survey
There are a lot of interesting works to discover in this paper.
It also references useful datasets and models.
BatchPrompt: Accomplish more with less
Prompts for LLMs may contain three different kinds of information:
The instruction: What do we want the model to do
Examples: Several examples of the expected results/outputs (for few-shot learning)
The user input
Imagine that you have a user who wants to use the LLM only for translating text into German. (1) might be “translate into German” and (2) several translation examples (typically between 2 and 5 high-quality examples for few-shot learning). (1) and (2) would be added for each user input. If the user inputs, e.g., sentences to translate, are sent one by one, the cost of processing (1) and (2) each time would be considerable.
Microsoft proposes BatchPrompt (Lin et al., 2023) to make this more efficient.
The idea is simple and intuitive: Pack as many user inputs as you can into one prompt, while leaving some space to add (1) and (2) at the beginning of the prompt.
The main challenge here is that the order in which the user inputs are provided will have an impact on the results.
Lin et al. (2023) propose two new techniques to alleviate this impact: Batch Permutation and Ensembling (BPE) and Self-reflection-guided EArly Stopping (SEAS).
In practice, it seems to work well. The authors demonstrate that BatchPrompt obtains results as good as packing a single input per prompt while being much more efficient.
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!