


The Weekly Kaitchup #58
AdEMAMix - FLUTE


Hi Everyone,
In this edition of The Weekly Kaitchup:
AdEMAMix: Achieve the Same Results as with AdamW Using Only Half as Many Training Tokens
FLUTE: Finally, NF4 Models Are Accelerated!
My book “LLMs on a Budget” is now available for pre-order! Get all the details here:
![Announcing The Kaitchup's Book: LLMs on a Budget [Pre-sales Open]](https://substackcdn.com/image/fetch/$s_!F5Dh!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa2920b00-5ab4-4e2d-9ebb-6b46642e4876_1024x768.jpeg)
I’m planning to publish the first chapter around the 15th of October.
The Kaitchup has now more than 5000 subscribers. If you are a free subscriber, consider upgrading to paid to access all the notebooks (100+) and more than 150 articles.
Note: Consider switching to a yearly subscription if you are a monthly subscriber. It is 38% cheaper.
AdEMAMix: Achieve the Same Results as with AdamW Using Only Half as Many Training Tokens
AdamW is by far the most used optimizer for training large neural networks. However, as a momentum-based optimizer relying on a single Exponential Moving Average (EMA) of gradients, it struggles to balance weighting recent gradients heavily while still considering older gradients. This imbalance leads to inefficiencies in the optimization process.
Indeed, gradients can remain useful for tens of thousands of training steps, but a single EMA cannot effectively capture both recent and older gradient information. By combining two EMAs with different decay rates, AdEMAMix uses both recent and old gradients to help models converge faster and more reliably.
The AdEMAMix Optimizer: Better, Faster, Older
It also leverages older gradients to reduce the rate at which the model forgets training data during optimization.
AdEMAMix has two momentum terms:
A fast EMA (with low β) for responding to recent changes
A slow EMA (with high β) for utilizing older gradients
The update rule for AdEMAMix modifies the Adam update by incorporating both EMAs to balance gradient information more effectively. When switching from AdamW mid-training, AdEMAMix initializes the second momentum term to zero, ensuring a smooth transition.
According to the authors, the AdEMAMix optimizer consistently outperforms AdamW in both language modeling and vision tasks. It improves optimization stability, speeds up convergence, and slows down model forgetting compared to AdamW.
It takes twice as less training tokens to achieve the same results as AdamW!
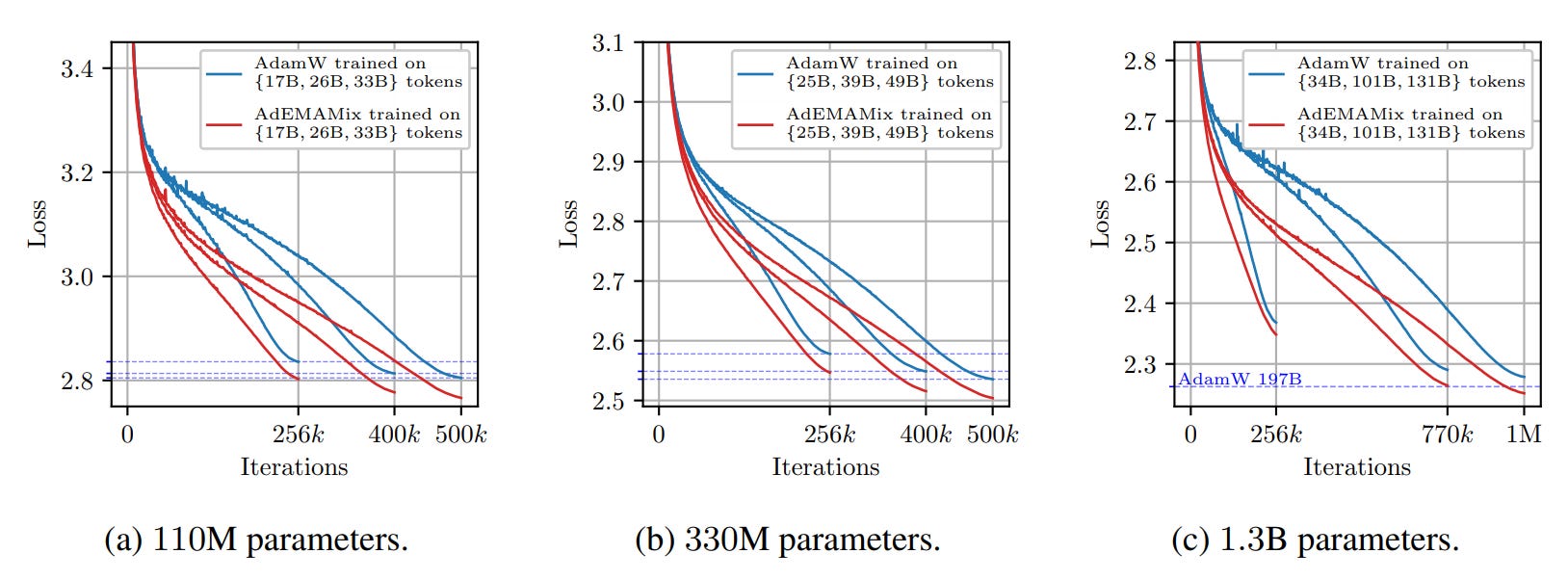
You can find the official implementation here:
FLUTE: Finally, NF4 Models Are Accelerated!
The NormalFloat4 (NF4) data type is currently often used to quantize LLMs in the context of QLoRA fine-tuning. NF4 is often superior to the INT4 data type used by other quantization methods. This is the data type used by default for the quantization with bitsandbytes. Moreover, this quantization is calibration-free, i.e., the model is efficiently quantized directly at loading time.
But quantization with NF4 has a major flaw, it makes the quantized models very slow.
To accelerate models quantized with NF4, we now have FLUTE which employs a Lookup Table (LUT) quantization:
GitHub: HanGuo97/flute (Apache 2.0 license)
Uniform quantization converts full-precision weights into lower-precision intervals of equal size, while Lookup Table (LUT) quantization, a more flexible variant of non-uniform quantization, maps intervals to arbitrary values using a lookup table.
In Uniform Quantization, the quantized weight is de-quantized as a product of the weight and a scaling factor. In LUT Quantization, a lookup table provides values for the de-quantized weight by mapping the quantized weight to its corresponding value from the table. This flexibility allows for more complex quantization methods, as supported in FLUTE, including int4, fp4, and even custom learned lookup tables.
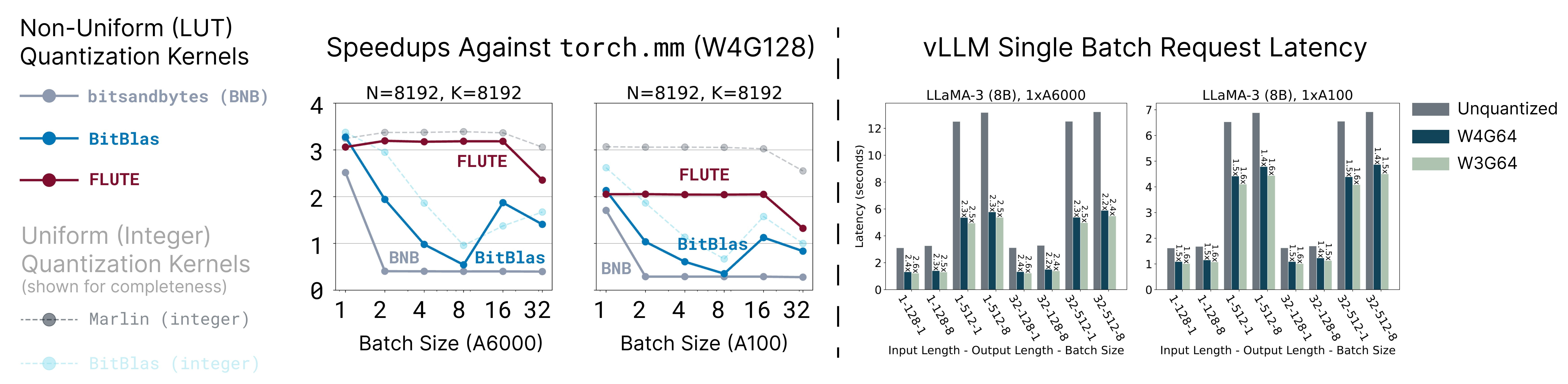
FLUTE-quantized models can be deployed using existing frameworks such as vLLM and Hugging Face’s accelerate library. FLUTE can be applied to models quantized with bitsandbytes as follows:
flute.integrations.base.prepare_model_flute(
name="model.model.layers",
module=model.model.layers,
num_bits=num_bits,
group_size=group_size,
fake=False,
prepare_bnb_layers=True,
default_bnb_dtype=torch.float16,
)It supports both torch.float16 and torch.bfloat16 input data types, with 4-bit, 3-bit, and 2-bit precision. Performance optimizations for bfloat16 on Ampere GPUs are still in progress, and certain combinations may cause numerical instability.
I’ll probably try in an upcoming article to see whether we can make QLoRA fine-tuning faster with FLUTE!
GPU Cost Tracker
This section keeps track, week after week, of the cost of GPUs. It only covers consumer GPUs, from middle-end, e.g., RTX 4060, to high-end, e.g., RTX 4090.
While consumer GPUs have much less memory than GPUs dedicated to AI, they are more cost-effective, by far, for inference with small batches and fine-tuning LLMs with up to ~35B parameters using PEFT methods.

To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
Bad timing for buying an RTX 4090. Price increases again!
RTX 4090 (24 GB): PNY GeForce RTX™ 4090 24GB XLR8 Gaming VERTO™ ($1,779.99 (+$28.99), changed for a cheaper card)
RTX 4080 SUPER (16 GB): GIGABYTE GeForce RTX 4080 Super WINDFORCE V2 ($999.99, same card as last week)
RTX 4070 Ti SUPER (16 GB): MSI Gaming RTX 4070 Ti Super 16G Ventus 2X OC ($779.00 (-$10.99); hanged for a cheaper card)
RTX 4060 Ti (16 GB): MSI Gaming GeForce RTX 4060 Ti 16GB GDRR6 Extreme Clock ($429.99 (-$10.00), changed for a cheaper card)
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week in The Salt, I reviewed:
⭐OLMoE: Open Mixture-of-Experts Language Models
LongRecipe: Recipe for Efficient Long Context Generalization in Large Language Models
Statically Contextualizing Large Language Models with Typed Holes

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% (or 30% for Pro subscribers) discount for group subscriptions):
Have a nice weekend!