


The Weekly Kaitchup #56
NanoFlow - Comparison of LLM Inference Services (Accuracy) - Zamba2-1.2B


Hi Everyone,
In this edition of The Weekly Kaitchup:
NanoFlow: Faster than vLLM and TensorRT-LLM
Comparing LLM Inference Services: Same Model, Different Accuracy
Zamba2-1.2B: A Smaller Hybrid SSM/Transformer
The Kaitchup has now more than 5000 subscribers! Thank you all for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (90+) and more than 150 articles.
If you are looking for custom AI notebooks, priority support, or professional LLM services, have a look at The Kaitchup Pro:
To all Kaitchup Pro subscribers: I’m putting the finishing touches on my first exclusive article for Pro subscribers, which details the research I've conducted over the past three months on better compressing and accelerating LLMs. I’ll be publishing it within the next two weeks, along with some exclusive LLMs that I’m currently refining. In September, you will also have early access to the first sections of my book, “LLMs on a Budget”.
AI Notebooks and Articles Published this Week by The Kaitchup

Notebook: #98 Quantize and Evaluate Mistral-NeMo-Minitron-8B-Base and Llama-3.1-Minitron-4B

Notebook: #99 Run Llama 3.1 70B Instruct with ExLlamaV2 on Your GPU, and Comparison with AWQ and GPTQ
NanoFlow: Faster than vLLM and TensorRT-LLM
We have a new open source framework to serve LLMs very fast:
GitHub: efeslab/Nanoflow (Apache 2.0 license)
NanoFlow is a high-performance serving framework that optimizes throughput using techniques like intra-device parallelism, asynchronous CPU scheduling, and SSD offloading. According to their benchmark, it significantly outperforms frameworks like TensorRT-LLM, achieving up to 1.91x higher throughput.
The techniques are explained in more detail in this paper:
NanoFlow: Towards Optimal Large Language Model Serving Throughput
It is open-sourced with a C++ backend, Python frontend, and integrates state-of-the-art kernel libraries.
Their benchmark results:

The latency is also impressively low.
However, all the experiments were conducted on an 8xA100 80GB DGX node. We don’t know how well it performs on consumer hardware and the documentation doesn’t mention whether it supports quantization.
I’ll try it and if it works well for 24 GB GPUs and smaller, I’ll write about it.
Meanwhile, if you are searching for a library to server LLMs, vLLM is still the best in my opinion. It’s not the fastest. For instance, TensorRT-LLM is faster but vLLM is one of the most versatile as it is easy to set up and supports speculative decoding, several quantization formats, Marlin, and LoRA adapters.

Comparing LLM Inference Services: Same Model, Different Accuracy
An increasing number of companies are offering LLM services through their own proprietary frameworks, which often outperform open-source solutions in terms of inference throughput.
Groq, Cerebras, and Together are among the industry leaders in this space. Cerebras recently published a compelling study comparing the accuracy of Llama3.1-8B Instruct and Llama3.1-70B Instruct models across different platforms, including Fireworks, Groq, Cerebras, and Together:
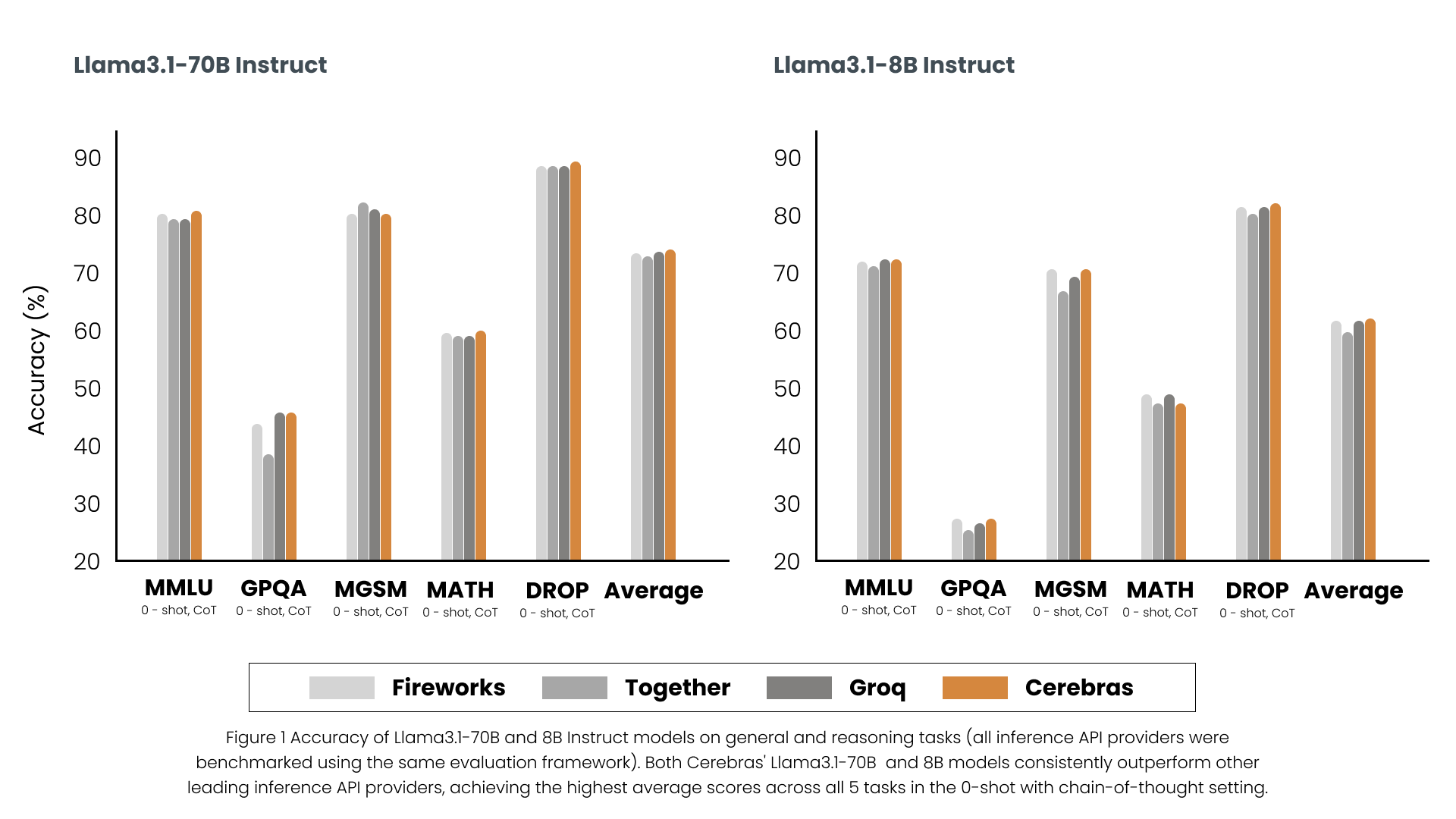

Note: It's important not to draw definitive conclusions about which solution is the most accurate based on these plots alone. An independent third-party evaluation would be necessary to make such a determination.
The plot clearly shows that, despite serving the same models, the performance of each solution varies. This discrepancy likely comes from differences in how each service approximates the model's computations to improve speed and reduce costs, particularly within the self-attention mechanism and/or because of the use of quantization.
The differences are especially noticeable for the Llama 3.1 8B model. It would be interesting to see how open-source frameworks like vLLM or TGI compare in terms of accuracy against these online solutions.
source: Llama3.1 Model Quality Evaluation: Cerebras, Groq, Together, and Fireworks
Zamba2-1.2B: A Smaller Hybrid SSM/Transformer
Last week, in The Weekly Kaithcup #55, I wrote about Jamba 1.5, a hybrid model made of a state-space model and transformer blocks for very efficient inference.
Jamba 1.5 are huge model that can’t run on consumer hardware. Jamba 1.5 Mini is actually a 51B parameter model. Fortunately, smaller alternatives exist.
Zamba2-1.2B has been released by Zyphra. Similar to Jamba, it’s a hybrid model, but it combines state-space models and transformer blocks in a different configuration compared to Jamba.

A slightly larger version, Zamba2-2.7B has also been published two months ago.
However, Zamba is not natively supported by Hugging Face Transformers. We have to install a fork prepared by Zyphra. You will find all the details to run the models on their model cards.
Next week, we will see how to use SSMs and hybrid models (fine-tuning and quantization). Unfortunately, I can already say that most frameworks poorly support all these new kinds of models.
GPU Cost Tracker
This section keeps track, week after week, of the cost of GPUs. It only covers consumer GPUs, from middle-end, e.g., RTX 4060, to high-end, e.g., RTX 4090.
While consumer GPUs have much less memory than GPUs dedicated to AI, they are more cost-effective, by far, for inference with small batches and fine-tuning LLMs with up to ~35B parameters using PEFT methods.

To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
RTX 4090 (24 GB): GIGABYTE GV-N4090AERO OC-24GD GeForce RTX 4090 AERO ($1,699.00, same as last week)
RTX 4080 SUPER (16 GB): GIGABYTE GeForce RTX 4080 Super WINDFORCE V2 ($999.99, same as last week)
RTX 4070 Ti SUPER (16 GB): ZOTAC GAMING GeForce RTX 4070 Ti SUPER Trinity Black Edition ($799.99 (+$10.00); last week: $789.99)
RTX 4060 Ti (16 GB): ZOTAC Gaming GeForce RTX 4060 Ti 16GB AMP DLSS 3 16GB ($449.99 (+$15.00); last week: $424.99)
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) and articles I have checked and updated, with a brief description of what I have done.
This week, I have updated the notebook and article showing how to fine-tune Gemma 2.
I added “add_eos_token=True” for the instantiation of the tokenizer. It wasn’t supported when the model was released but now it works. EOS tokens are automatically added at the end of each training example.
I added FlashAttention which is now supported by Gemma 2.
I modified the SFTConfig to be compatible with the recent update of TRL.

Notebook #87: Fine-tune Gemma 2 on Your Computer -- With Transformers and Unsloth
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
Including code in the pre-training data of large language models (LLMs) has become standard practice, even before these models were explicitly used for code generation tasks. Today, code in various programming languages (such as Python, Java, and HTML) constitutes a significant portion of the pre-training data for state-of-the-art LLMs like Llama 3, Gemma 2, and Qwen2, improving their ability to perform code generation tasks effectively.
However, the impact of including code in the training data on non-code tasks—such as natural language generation, reasoning, and world knowledge—has not been thoroughly investigated.
Does the inclusion of code in LLM training data improve or degrade their performance on non-code tasks?
In this article for The Salt, I review a paper by Cohere showing the importance of including code in training data:

This week, I also reviewed:
Multi-Layer Transformers Gradient Can be Approximated in Almost Linear Time
FocusLLM: Scaling LLM's Context by Parallel Decoding
⭐Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
LLM Pruning and Distillation in Practice: The Minitron Approach
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!