


The Weekly Kaitchup #53
FlexAttention - SAM2 - MiniCPM-V 2.6


Hi Everyone,
In this edition of The Weekly Kaitchup:
FlexAttention: A Flexible Pytorch API for Implementing Attention Optimizations
Segment Anything Model, V2 (SAM2)
MiniCPM-V 2.6: A Very Powerful Multimodal LLM for Interacting with Single Images, Multiple Images, and Videos
If you are a free subscriber, consider upgrading to paid to access all the notebooks (90+) and more than 100 articles.
If you are looking for custom AI notebooks, priority support, or professional LLM services, have a look at The Kaitchup Pro:
AI Notebooks and Articles Published this Week by The Kaitchup

Notebook: #92 Fine-tune Llama 3.1 70B with Two Consumer GPUs -- Using FSDP and QLoRA

Notebook: #93 Fine-tune SmolLM 135M and 370M with Distilled DPO
FlexAttention: A Flexible Pytorch API for Implementing Attention Optimizations
Real-world applications require optimized attention implementations for various purposes: extending context length, accelerating inference, reducing memory consumption, etc. For instance, Gemma’s soft-capping, vLLM’s PagedAttention, and FlashAttention, among many others, are different attention implementations that have been optimized manually and exploit custom CUDA kernels.
Most of these implementations are not compatible with each other out of the box. Note: For instance, when Gemma 2 was released with soft-capping, FlashAttention had to be disabled. Now, they are fully compatible.

These optimizations have improved performance but at the cost of flexibility.
Pytorch’s new API, FlexAttention, brings more flexibility by allowing easy implementation of various attention variants with just a few lines of code. It converts them into efficient FlashAttention kernels, maintaining performance without extra memory usage.

I believe this new API will substantially accelerate the development of new optimized attention implementations on top of existing ones.
This API compiles new attention implementations into kernels matching the performance of handwritten versions without extra memory usage. It also automates the backward pass using PyTorch's autograd and optimizes performance by leveraging sparsity in the attention mask.
More details here:
FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention
Segment Anything Model, V2 (SAM2)

The Segment Anything Model (SAM) is a base model for image segmentation. The first version, released last year, was trained on a dataset of 1.1 billion mask annotations from 11 million images.
A new version, SAM2, has been released by Meta:
It is described in this paper:
SAM 2: Segment Anything in Images and Videos
It is a unified model designed for both video and image segmentation, treating an image as a single-frame video. SAM 2 takes input prompts, such as points, boxes, or masks, on any video frame to define a segment of interest. It then predicts a spatio-temporal mask, or "masklet," which can be refined iteratively with additional prompts in subsequent frames.
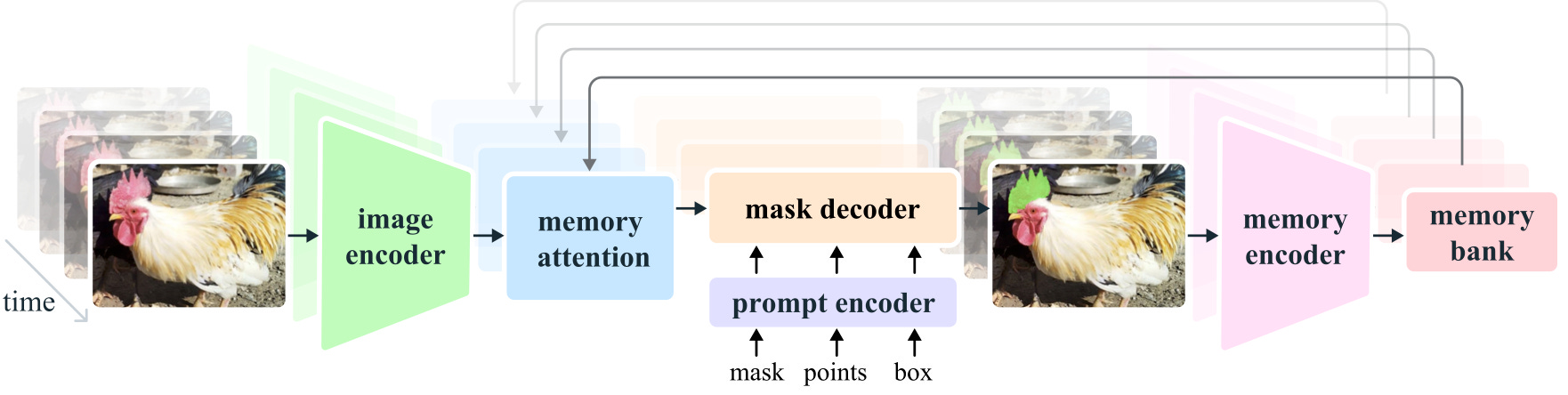
Its streaming architecture processes video frames sequentially, using a memory attention module to reference previous memories of the target object.
SAM models are very small. We can use them on consumer hardware. Meta provides examples in the repository:
GitHub: facebookresearch/segment-anything-2 (Apache 2.0 license)
Potential applications are numerous. It can be used for instance to accurately track an object on a video.
MiniCPM-V 2.6: A Very Powerful Multimodal LLM for Interacting with Single Images, Multiple Images, and Videos
MiniCPM-V 2.6 is a multimodal LLM of 8 billion parameters. It has been built from SigLip-400M for the vision part (preprocessing and encoding), and Qwen2-7B for language understanding and generation:
According to public benchmarks, it surpasses popular models like GPT-4V and Claude 3.5 Sonnet in single image comprehension. It seems very good for reasoning from multiple images, for OCR, and with high-resolution images. It’s also a multilingual model.
MiniCPM is much larger than other VLMs such as Florence-2 which, on the other hand, is only capable of processing single images.

MiniCPM-V 2.6 is already supported by most inference frameworks such as vLLM and Transformers.
They also released a 4-bit version that seems to work on an 8GB GPU:
The model card provides several code examples to run it with video, single image, and multiple image inputs.


GPU Cost Tracker
This section keeps track, week after week, of the cost of GPUs. It only covers consumer GPUs, from middle-end, e.g., RTX 4060, to high-end, e.g., RTX 4090.
While consumer GPUs have much less memory than GPUs dedicated to AI, they are more cost-effective, by far, for inference with small batches and fine-tuning LLMs with up to ~35B parameters using PEFT methods.

To get the prices of GPUs, I use Amazon.com. If the price of a GPU drops on Amazon, there is a high chance that it will also be lower at your favorite GPU provider. All the links in this section are Amazon affiliate links.
RTX 4090 (24 GB): PNY GeForce RTX™ 4090 24GB VERTO™ ($1,738.99, same price as last week)
RTX 4080 SUPER (16 GB): ZOTAC GAMING GeForce RTX 4080 SUPER Trinity Black Edition ($1,029.99, same price as last week)
RTX 4070 Ti SUPER (16 GB): ZOTAC GAMING GeForce RTX 4070 Ti SUPER Trinity Black Edition ($799.99 (+$20.00); last week: $779.99)
RTX 4060 Ti (16 GB): PNY GeForce RTX™ 4060 Ti 16GB XLR8 ($459.99, same price as last week)
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
MMLU is currently the #1 benchmark to evaluate generative LLMs… without generating anything. MMLU is a classification task.
An LLM can guess the right answer to a question while not being able to communicate it to humans. I explain how in this article:

This week, I also reviewed:
Improving Text Embeddings for Smaller Language Models Using Contrastive Fine-tuning
ThinK: Thinner Key Cache by Query-Driven Pruning
⭐POA: Pre-training Once for Models of All Sizes
Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!
A datapoint on budgeting. On quickpod going rate ATM for an RTX4090 is $0.23/hr. 6500 hours to get to the $1700 price new. 9 months or so, 24hrs a day.