


The Weekly Kaitchup #46
Nematron 4 - Chameleon - Florence-2


Hi Everyone,
In this edition of The Weekly Kaitchup:
Nematron 4 340B: A Huge LLM by NVIDIA
Meta Chameleon and Multi-token Predictions
Florence-2: Compact Multi-task Vision Models
The Kaitchup has 4,045 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (70+) and more than 100 articles.
AI Notebooks and Articles Published this Week by The Kaitchup

Notebook: #79 Quantize the KV Cache for Memory-Efficient Inference -- Example with Llama 3 8B

Notebook: #80 Continue Pre-training LLMs on Your Computer with Unsloth -- Examples with Llama 3 and Mistral 7B
Nematron 4 340B: A Huge LLM by NVIDIA
Nematron 4 by NVIDIA is a huge model with 340 billion parameters.
nvidia/Nemotron-4-340B-Instruct (custom but permissive license)
According to the evaluation conducted by NVIDIA, Nematron 4 is better than OpenAI’s GPT-4 in most tasks.
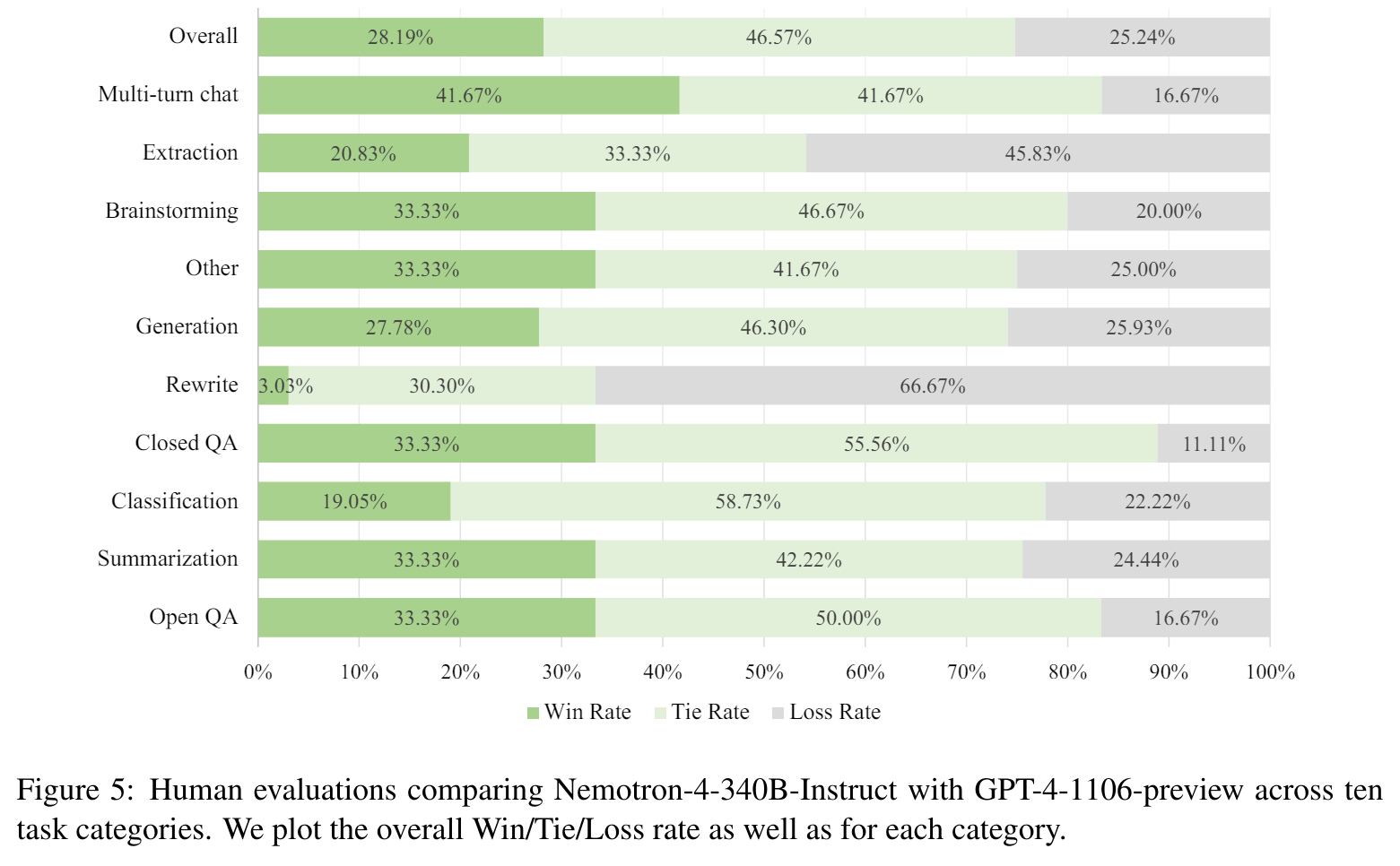
Can you run it locally?
Nematron 4 is 340 billion parameters occupying 2 bytes each.
To load it, you would need 680 GB of GPU RAM (e.g., nine H100 GPUs). Then, for inference, I estimate that you would need 300 additional GBs for buffers, activations, and KV cache. It also depends on the batch size and the sequence length.

NVIDIA reports that 16x H100s are necessary, i.e., 1.2 TB of GPU RAM, but I think they came up with this number for tasks requiring processing very long sequences.
Nematron 4 is a very good target for an almost lossless 4-bit quantization. We know that huge LLMs like this one are very robust to quantization. We could even try 2-bit quantization with HQQ to reduce the size of the model to 100 GB.

However, for now, Nematron 4 remains difficult to use and quantize with most libraries. The models are not yet converted to Hugging Face’s format and are not supported by most quantization frameworks.
Meta Chameleon and Multi-token Predictions
Meta released many models and datasets this week. They published a blog post briefly presenting them:
Sharing new research, models, and datasets from Meta FAIR
I find especially interesting the Chameleon models.
These models are multimodal on both sides: the input can be a combination of image and text and the model can generate image and text.

They released two sizes of models: 7B and 34B. However, the models are not easy to access. You have to request them through this form; they can only be used for research purposes.
Meta also released this week an LLM capable of multi-token predictions:
facebook/multi-token-prediction (for research purposes only)
This model was made using the technique described in this paper:
Better & Faster Large Language Models via Multi-token Prediction

This technique seems to improve the model’s accuracy while making it faster since several tokens are predicted at once.
The limitations of this approach are unclear to me. I assume it is much more difficult to train since the model has to predict multiple tokens at each time step.
Moreover, they didn’t compare this approach with the numerous methods proposed for non-autoregressive decoding. In non-autoregressive decoding, tokens are predicted in parallel instead of being generated one by one. It usually degrades the performance. See for instance this work by Tencent. I see multi-token prediction as a method between non-autoregressive and autoregressive decoding but it would have been insightful to compare these methods.
Why does Meta’s multi-token prediction improve accuracy?
It’s unclear. Meta wrote a section “speculating” on the reasons why it works but it requires further investigations. In other words, we won’t see many LLMs adopting this approach soon.
Florence-2: Compact Multi-task Vision Models
Microsoft released Florence-2, state-of-the-art vision models designed to tackle an extensive array of vision and vision-language tasks using a prompt-based approach. The models are remarkably small and, according to the technical report, Florence-2 is better at these tasks than other vision models 100x larger:
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
microsoft/Florence-2-base (230M parameters)
microsoft/Florence-2-large (770M parameters)
The models have been trained on the FLD-5B dataset, which comprises 5.4 billion annotations spanning 126 million images.
On the Kaitchup, I mainly write about large language models. Would you be interested in reading tutorials and reviews of vision and speech models? I could write about these other types of models too. I’m just not sure whether The Kaitchup’s readers would be interested. Please, answer this survey:
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) and articles I have checked and updated, with a brief description of what I have done.
When I wrote the article demonstrating VeRA fine-tuning for Llama 3, the implementation of VeRA in Hugging Face PEFT was very limited. Only modules with the same shape could be targeted. Targeting all the linear modules, as usually recommended for LoRA fine-tuning, wasn’t possible. With the last version of PEFT, this is now possible.
I updated the notebook and article to draw the learning curves of VeRA when targeting all the linear modules. While it still underperforms LoRA, targeting all the linear layers significantly improves VeRA’s performance. The adapter produced is still 26x times smaller than the adapter created by LoRA.
#76 VeRA: Fine-tuning Tiny Adapters for Llama 3 8B

The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed SimPO, a reference-free method to align LLM with human preferences more efficiently. I wasn’t expecting much when I started to review SimPO. It seemed like one more method for preference optimization very similar to existing ones. However, it achieves good learning curves and is much faster to train than other efficient methods like ORPO.

This week in the Salt, I reviewed:
⭐Scalable MatMul-free Language Modeling
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Transformers meet Neural Algorithmic Reasoners
MaskLID: Code-Switching Language Identification through Iterative Masking
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!