


The Weekly Kaitchup #44
Qwen2 - Continued Pre-training - FineWeb-Edu - MMLU-Pro


Hi Everyone,
In this edition of The Weekly Kaitchup:
Qwen2: The Best Alternative to Llama 3?
“Continued” Pre-training with Unsloth
FineWeb-Edu: 1.3T Tokens of High-Educational Content
MMLU-Pro: A Better MMLU to Benchmark LLMs
The Kaitchup has 3,862 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (70+) and more than 100 articles.
AI Notebooks and Articles Published this Week by The Kaitchup

The code for fine-tuning and merging adapters for Phi-3 medium is implemented in this notebook:

The notebook demonstrating VeRA fine-tuning for Llama 3 is available here:
Qwen2: The Best Alternative to Llama 3?
Qwen2 LLMs are now available:
Hugging Face collection: Qwen2 (Apache 2.0 license)
Qwen2 includes pre-trained and instruction-tuned models of 5 sizes: 0.5B, 1.5B, 7B, 57B-A14B, and 72B. The version 57B-A14B is a mixture of experts (MoE).
Qwen1.5 LLMs were already very good but Qwen2 LLMs look even better!

According to Alibaba’s evaluation, the company behind the Qwen LLMs, Qwen2 largely outperforms Llama 3:
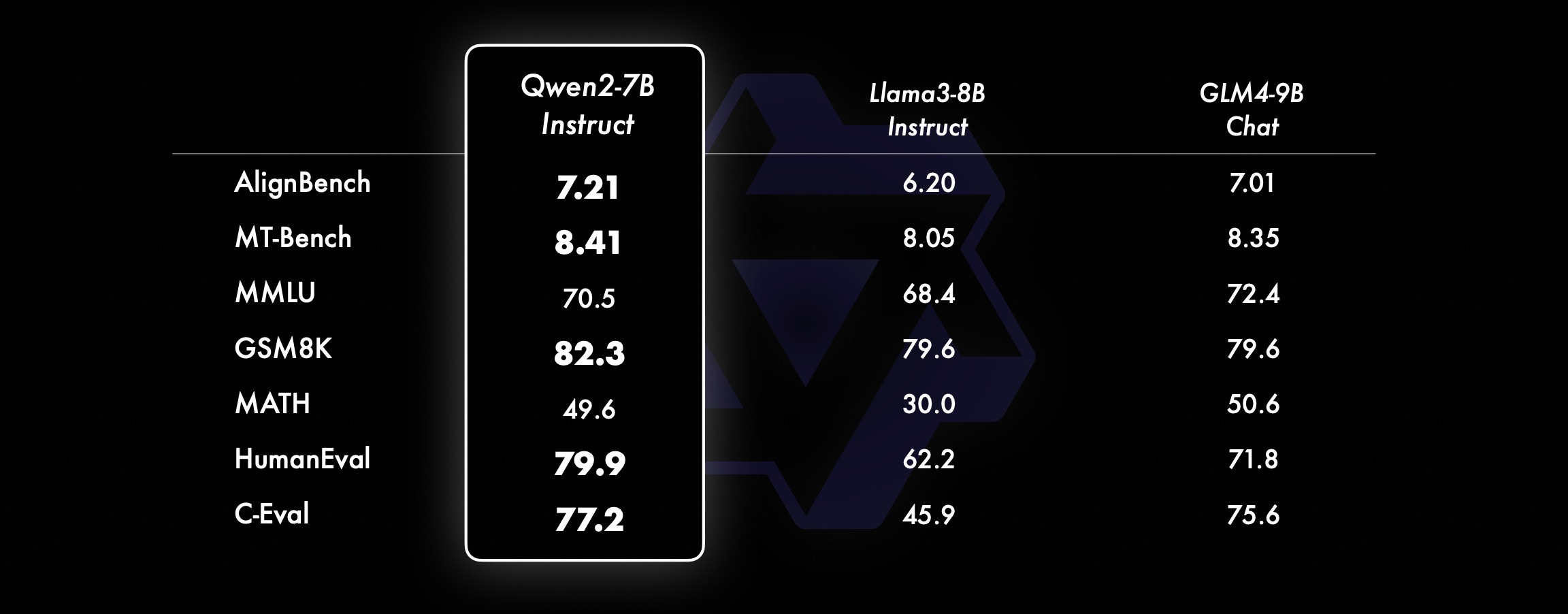
Moreover, Qwen2 officially supports many more languages:

In an article next week, I will review the models and compare the performance of QLoRA fine-tuning and quantization between Qwen2 and Llama 3.
“Continued” Pre-training with Unsloth
Continued pre-training is fine-tuning but on a dataset without a specific format. The training batches don’t contain self-contained training examples but as many consecutive tokens as possible.
Continued pre-training with QLoRA is now fully supported by Unsloth. Thanks to custom code and manual optimization for back-propagation, Unsloth is much faster and more memory-efficient than most frameworks. My last article using Unsloth was about the instruct fine-tuning of Gemma on consumer hardware:

Unsloth AI claims that continued pre-training is 2x faster and uses 50% less VRAM than Hugging Face’s Trainer:
Continued Pretraining with Unsloth (blog post by Unsloth)
What is most interesting is their recipe to continue pre-training LLMs:
Decoupling learning rates: The training of the token embeddings should use a much smaller learning rate than for the layers of the model.
Fully fine-tuning the token embeddings and language modeling head is necessary when the domain/genre/style/language of the training data is very specific, e.g., training on non-English data. I showed how to do this with Transformers in this article:
Using rank-stabilized LoRA (rsLoRA) significantly improves the results. Note: I have an article about rsLoRA in my drafts, I’ll publish it this month.

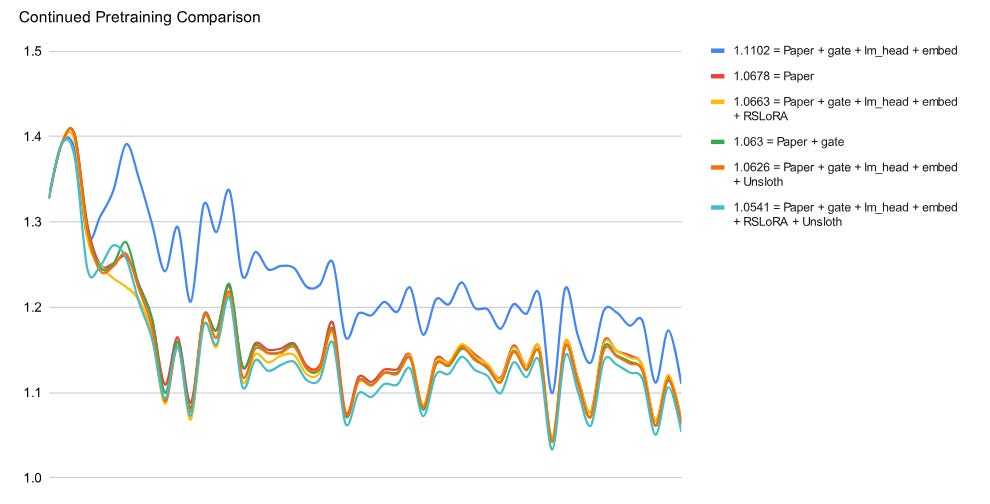
This is very interesting for a low-cost continued pre-training. I’ll try it and write a detailed article about it.
FineWeb-Edu: 1.3T Tokens of High-Educational Content
A few weeks ago, Hugging Face released FineWeb, a high-quality dataset of 15T tokens outperforming datasets of similar sizes for pre-training LLMs.
Hugging Face further polished and filtered this dataset to keep only the best data. The resulting data is FineWeb-Edu which contains 1.3T tokens of very high-quality educational content.
Hugging Face hub: HuggingFaceFW/fineweb-edu
They trained LLMs on this dataset and showed that it yields even better results than the 15T tokens of the original FineWeb. The results on the ARC and MMLU benchmarks are very impressive, and trustworthy since Hugging Face carefully checked for data contamination:


It demonstrates once more that for training LLMs data quality is more important than quantity.
MMLU-Pro: A Better MMLU to Benchmark LLMs
MMLU is currently recognized as one of the most meaningful benchmarks for evaluating LLMs’ language understanding and knowledge.

The original MMLU dataset provides only 4 answer choices for each question, the new MMLU-Pro expands this to 10. This expansion introduces a more realistic and challenging evaluation, significantly reducing the likelihood of correct answers through random guessing.
The original MMLU dataset also predominantly features knowledge-based questions that require minimal reasoning. In contrast, MMLU-Pro elevates the difficulty level and incorporates more reasoning-intensive questions.
Finally, by increasing the number of distractors, MMLU-Pro lowers the chances of correct guesses by luck. It improves the robustness of the benchmark. Specifically, when testing with 24 different prompt styles, the sensitivity of model scores to variations in prompts decreased from 4-5% in the original MMLU to just 2% in MMLU-Pro.
Here are the results of recent LLMs on MMLU-Pro:

More details on how MMLU-Pro was built in this article:
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) and articles I have checked and updated, with a brief description of what I have done.
Hugging Face TRL has been updated. They are deprecating the TrainingArguments object for the SFTTrainer and we should now pass an SFTConfig object instead.
When this update arrived on pip, all the notebooks using TrainingArguments for the SFTTrainer stopped working. Note: This is not the case anymore and all the notebooks should work again even without the hotfix described below. Hugging Face quickly released a new version with better backward compatibility.
I hotfixed all the notebooks from #62 to the most recent one, simply replacing:
training_arguments = TrainingArgumentswith
from trl import SFTConfig
training_arguments = SFTConfigAll these notebooks are now working again but yield many warnings due to arguments that are overridden.
For instance, “packing”, “dataset_text_field”, and “max_seq_length” should be passed to the SFTConfig from now on but my hotfix left them in the SFTTrainer. This is allowed by TRL until the release of version 1.0.
Moreover, I noticed that PyTorch 2.4 (release scheduled for July) will break Transformers’ gradient checkpointing for almost all models. We will have to pass “use_reentrant=True” explicitly as a gradient checkpointing argument. I’ll start from next week updating all the notebooks to add use_reentrant, replacing:
model = prepare_model_for_kbit_training(model)with
model = prepare_model_for_kbit_training(model, gradient_checkpointing_kwargs={'use_reentrant':True})The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
This week in the Salt, I briefly reviewed:
Zamba: A Compact 7B SSM Hybrid Model
⭐Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!