


The Weekly Kaitchup #43
SimPO - Training with Sentence Transformers - KV Cache Quantization


Hi Everyone,
In this edition of The Weekly Kaitchup:
SimPO: A Method Simpler than DPO for Preference Optimization
Train Embeddings Directly with Sentence Transformers
KV Cache Quantization with HF Transformers
The Kaitchup has now 3,775 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (70+) and more than 100 articles.
SimPO: A Method Simpler than DPO for Preference Optimization
SimPO is very similar to DPO to align LLMs with human preferences. However, while DPO requires a reference model fine-tuned on an instruction dataset, SimPO doesn’t need it. Like DPO, it doesn’t need a reward model either.

SimPO still requires a model trained on an instruction dataset (SFT) but only uses it for initialization. In other words, SimPO only loads one model in memory while DPO loads two models, the reference model and the model to align.
It makes SimPO as memory-efficient as ORPO but note that ORPO is even more simple since ORPO doesn’t need to be initialized with an SFT model.

SimPO is presented in this paper:
SimPO: Simple Preference Optimization with a Reference-Free Reward
The method learns how to discriminate between bad and good responses by using the average log probability of a sequence as the reward. It also applies a length-normalized reward formulation to penalize excessively long responses.
SimPO seems to outperform ORPO and DPO:
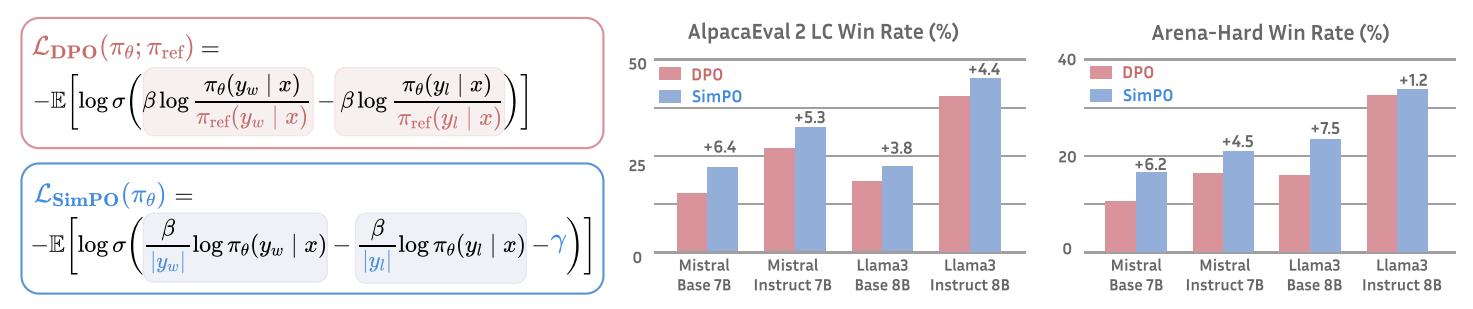
The authors released their implementation that is based on Hugging Face’s TRL:
GitHub: princeton-nlp/SimPO
I think it can be a good alternative to ORPO if you already have an SFT model fine-tuned on an instruction dataset. I’ll experiment with it once it’s officially integrated into TRL.
Train Embeddings Directly with Sentence Transformers
Sentence Transformers is the go-to library for manipulating embeddings, especially in RAG applications.

With the V3, we can now also use it to fine-tune embeddings. It is based on Hugging Face transformers, so if you are familiar with training models using HF transformers, fine-tuning embeddings with sentence transformers will be straightforward.
Here is a code example provided by the authors:
from datasets import load_dataset
from sentence_transformers import (
SentenceTransformer,
SentenceTransformerTrainer,
SentenceTransformerTrainingArguments,
SentenceTransformerModelCardData,
)
from sentence_transformers.losses import MultipleNegativesRankingLoss
from sentence_transformers.training_args import BatchSamplers
from sentence_transformers.evaluation import TripletEvaluator
# 1. Load a model to finetune with 2. (Optional) model card data
model = SentenceTransformer(
"microsoft/mpnet-base",
model_card_data=SentenceTransformerModelCardData(
language="en",
license="apache-2.0",
model_name="MPNet base trained on AllNLI triplets",
)
)
# 3. Load a dataset to finetune on
dataset = load_dataset("sentence-transformers/all-nli", "triplet")
train_dataset = dataset["train"].select(range(100_000))
eval_dataset = dataset["dev"]
test_dataset = dataset["test"]
# 4. Define a loss function
loss = MultipleNegativesRankingLoss(model)
# 5. (Optional) Specify training arguments
args = SentenceTransformerTrainingArguments(
# Required parameter:
output_dir="models/mpnet-base-all-nli-triplet",
# Optional training parameters:
num_train_epochs=1,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_ratio=0.1,
fp16=True, # Set to False if GPU can't handle FP16
bf16=False, # Set to True if GPU supports BF16
batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss benefits from no duplicates
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=100,
save_strategy="steps",
save_steps=100,
save_total_limit=2,
logging_steps=100,
run_name="mpnet-base-all-nli-triplet", # Used in W&B if `wandb` is installed
)
# 6. (Optional) Create an evaluator & evaluate the base model
dev_evaluator = TripletEvaluator(
anchors=eval_dataset["anchor"],
positives=eval_dataset["positive"],
negatives=eval_dataset["negative"],
name="all-nli-dev",
)
dev_evaluator(model)
# 7. Create a trainer & train
trainer = SentenceTransformerTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss=loss,
evaluator=dev_evaluator,
)
trainer.train()
# (Optional) Evaluate the trained model on the test set, after training completes
test_evaluator = TripletEvaluator(
anchors=test_dataset["anchor"],
positives=test_dataset["positive"],
negatives=test_dataset["negative"],
name="all-nli-test",
)
test_evaluator(model)
# 8. Save the trained model
model.save_pretrained("models/mpnet-base-all-nli-triplet/final")
# 9. (Optional) Push it to the Hugging Face Hub
model.push_to_hub("mpnet-base-all-nli-triplet")You can find more details in this blog post:
Training and Finetuning Embedding Models with Sentence Transformers v3
KV Cache Quantization with HF Transformers
Hugging Face Transformers can now quantize the KV cache of transformer models during inference. The KV cache can be quantized to 4-bit and 2-bit (and I guess 3-bit too) using HQQ or Quanto backends. Note: I don’t recommend Quanto since it only performs block-wise quantization. It’s a very simple quantization method that doesn’t seem to perform well once applied to the KV cache.
Quantizing the KV cache means that we can do inference on larger sequences or batches.

As we can see in the Figure above, without quantization (fp16), memory consumption increases dramatically as the sequence gets longer. A sequence of 2k tokens occupies 2 GB. Thanks to quantization, its memory consumption can be reduced below 1 GB.
However, 2-bit quantization doesn’t seem to be significantly more memory-efficient than 4-bit quantization while it leads to a much worse perplexity.

Perplexity-wise, HQQ 4-bit seems to perform as well as fp16 (i.e., no quantization).

If you want to use this feature, 4-bit quantization with the HQQ backend seems like a good configuration. A major downside is that it almost halves the decoding speed.
You can activate the quantization of the KV cache when calling model.generate:
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"backend": "hqq", "nbits": 4})The details of the implementation are documented here:
Unlocking Longer Generation with Key-Value Cache Quantization
I’ll write a detailed article about this feature in the coming weeks.
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) and articles I have checked and updated, with a brief description of what I have done.
This week, I made a tiny but important modification to the notebook and article showing how to fine-tune Llama 3. This modification correctly adds the EOS token at the end of each training example.

The standard way to do this is to pass “add_eos_token=True” to the tokenizer:
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B", add_eos_token=True, use_fast=True)However, this has no effect on Llama 3. The issue was known almost as soon as Llama 3 was released on the Hugging Face hub. More than 1 month later, it’s still not fixed. Instead of using “add_eos_token”, we have to add the EOS token manually:
ds = load_dataset("timdettmers/openassistant-guanaco")
#Add the EOS token
def process(row):
row["text"] = row["text"]+"<|end_of_text|>"
return row
ds = ds.map(
process,
num_proc= multiprocessing.cpu_count(),
load_from_cache_file=False,
)The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed and experimented with MoRA, a new PEFT method for fine-tuning a high-rank adapter. MoRA works but it feels like DoRA to me: An interesting idea that is not significantly better than LoRA and thus won’t probably be widely adopted.

This week in the Salt, I briefly reviewed:
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
⭐MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
Distributed Speculative Inference of Large Language Models
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!