


The Weekly Kaitchup #36
JetMoe - Schedule-Free Learning - Unsloth for long context


Hi Everyone,
In this edition of The Weekly Kaitchup:
JetMoE: Pre-training an 8B LLM Better than Llama 2 7B but for Only $80k
Schedule-Free Learning
Longer Context with Less Memory for Unsloth
The Kaitchup has now 2,950 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (50+) and more than 100 articles. There is a 7-day trial.
JetMoE: Pre-training an 8B LLM Better than Llama 2 7B but for Only $80k
The pre-training of LLMs is getting cheaper. Last week, I presented GaLore which makes possible the pre-training of 7B LLMs on consumer hardware.

Another way to reduce pre-training costs is to exploit a mixture-of-expert (MoE) architecture. MoEs are fast learners.
MyShell pre-trained and released a new MoE with 8B parameters. It exploits 4 expert subnetworks. However, in contrast with popular MoE models, such as Mixtral-8x7B, the 4 experts don’t share the same self-attention parameters. There are two router networks: one for the self-attention and one for the MLP:

For inference, only 2.2B parameters are activated which makes it very fast.
This model particularly stands out for its low pre-training cost. MyShell used 96 H100 GPUs for two weeks for a cost of $80k.
This is very cheap and short. Within two weeks, the model could only be trained on 1.25T tokens, with a batch size of 4M tokens. This is much less than LLMs of similar size: Google Gemma was trained on 6T tokens and Llama 2 on 2T tokens.
Yet, thanks to the MoE architecture (and better training data?), it’s enough to outperform Llama 2:
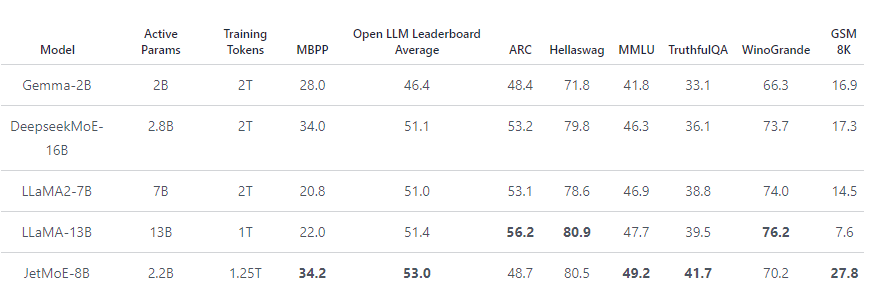
The model is available on the HF hub:
It runs without quantization on a 24 GB GPU.
Schedule-Free Learning
Meta released a new algorithm to remove the need for a learning rate scheduler during training.
Learning rate scheduler
The purpose of a learning rate scheduler is to change the learning rate according to a predefined plan during training. This approach can help to avoid getting stuck in local minima or overshooting the minimum.
For LLMs, the learning rate usually starts from a smaller value and gradually increases to a predetermined value over several epochs or steps. This is the warmup phase. Then, the learning rate usually decreases after each training step. This strategy is particularly useful when training starts with large pre-trained models as it helps prevent sudden large updates that could destabilize the model.

A scheduler-free optimizer as proposed by Meta doesn’t need to gradually decrease the learning rate.
Simple implementations for scheduler-free SGD and scheduler-free AdamW are available here:
GitHub: facebook research/schedule_free
Schedule-Free learning replaces the momentum of an underlying optimizer with a combination of interpolation and averaging.
For now, they only showed results on simple datasets. Their schedule-free AdamW learns faster and better than AdamW with a learning rate scheduler. And since it’s scheduler-free, we have less hyperparameters to set.
No results of experiments with LLMs have been released, yet.
Longer Context with Less Memory for Unsloth
The last version of Unsloth is now more memory-efficient for processing long context:

With 16 GB of GPU memory, Mistral 7B can now process up to 32k tokens! That’s 4x more than vanilla FlashAttention!
Processing the RoPE embeddings also became 28% faster.

Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) I have checked and updated, with a brief description of what I have done.
This week, I have checked and updated the following notebook:
#31 Fine-tune Mistral 7B with Distilled IPO
The notebook runs supervised fine-tuning and IPO training to align Mistral 7B with human preferences.
When I wrote this notebook, the computation of the IPO loss was bugged. Hugging Face has fixed it and I reran the notebook to confirm that the loss has now a much more reasonable value (it was above 10000 before the fix…). As in all my recent notebooks, I added the automatic setting of FlashAttention and bfloat16 if the GPU is compatible.
Moreover, IPO training now only loads the base model once. The SFT adapter is used as reference and also to initialize the training.
As for the training data, the notebook applies the default chat template rather than a custom format.
I have updated the related article to reflect these changes:

The Salt
The Salt is my other newsletter that takes a more scientific approach. In it, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I published a review of the Ada-instruct method to generate complex instruction datasets from given documents. I conclude that it can generate complex instructions but the quality is not great. The generated datasets with this method require to be heavily filtered.

This week in the Salt, I also briefly reviewed:
⭐ReFT: Representation Finetuning for Language Models
AURORA-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Long-context LLMs Struggle with Long In-context Learning
Training LLMs over Neurally Compressed Text
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!