


The Weekly Kaitchup #32
Sequoia - Fuyou


Hi Everyone,
In this edition of The Weekly Kaitchup:
Sequoia: Hardware-Aware Speculative Decoding
Fuyou: Unlocking NVMe SSDs for Fine-tuning 100B+ LLMs with 1 GPU
The Kaitchup has now 2,514 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks (50+) and more than 100 articles.
Sequoia: Hardware-Aware Speculative Decoding
Speculative decoding can significantly speed up inference if you choose the right pair of draft and main models. I have discussed it in this article:

A new framework, Sequoia, improves speculative decoding by making it “aware” of your hardware and the computational cost of speculating with the draft model.
For specific draft/target model pairs, Sequoia employs a dynamic programming algorithm to identify the most efficient tree structure, allowing for quicker expansion in terms of the number of tokens processed within a given computational budget.
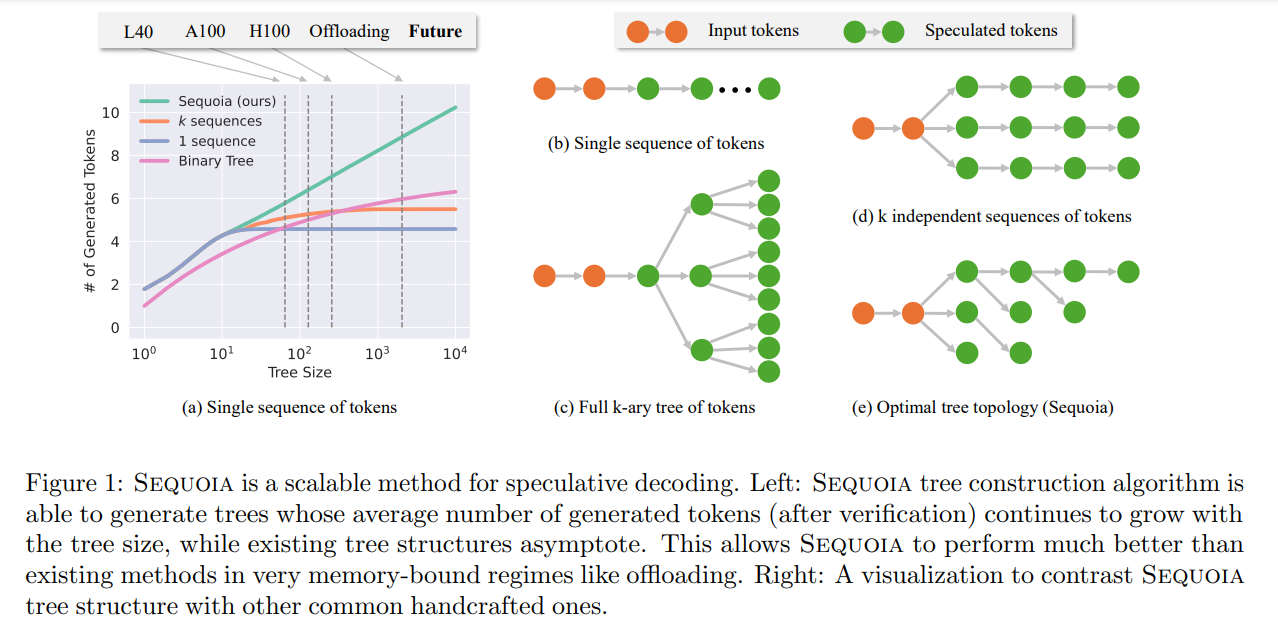
Sequoia also uses a sampling without replacement technique to make it more stable in generating outputs at various temperatures, compared to top-k sampling or sampling with replacement.
This approach yields a very fast speculative decoding as shown by the team behind Sequoia:

The framework is presented in detail in this paper:
Sequoia is available here:
GitHub: Infini-AI-Lab/Sequoia
Fuyou: Unlocking NVMe SSDs for Fine-tuning 100B+ LLMs with 1 GPU
Fuyou introduces a cost-effective training framework designed to facilitate the fine-tuning of massive 100 billion parameter models on budget-friendly hardware.
Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
The framework employs solid-state drives (SSDs) to improve activation swapping efficiency and integrate a new CPU optimizer that concurrently operates with backward propagation, eliminating downtime in GPU usage. This approach ensures that the training convergence speed remains unaffected.

Fuyou has been implemented in PyTorch and tested on NVIDIA A100-80GB and RTX 4090 GPUs within a standard server setup. In the paper, they demonstrate how to fine-tune 100B parameter LLMs leveraging SSDs.
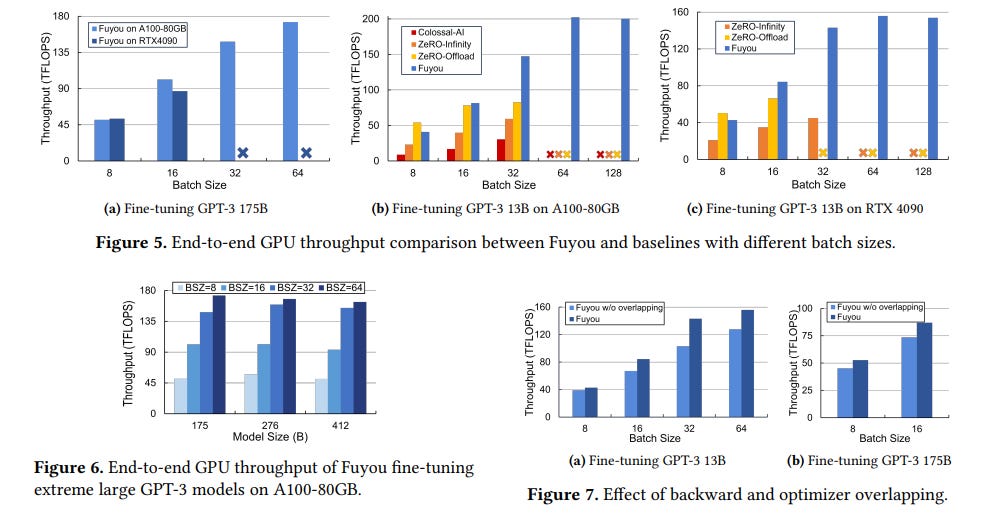
The paper doesn’t mention any plan to release their implementation.
Evergreen Kaitchup
In this section of The Weekly Kaitchup, I mention which of the Kaitchup’s AI notebook(s) I have checked and updated, with a brief description of what I have done.
This week, I have checked and updated the following notebook:
#24 Fine-tune an Instruct Version of Mistral 7B with DPO
FlashAttention and bfloat16 are now automatically used if your GPU is compatible. I have updated the reference model used for the DPO training for a much better one. Moreover, the DPO trainer now loads the base model only once. One adapter is the one from the reference model and the other adapter is trainable by DPO. The reference adapter also initializes this second adapter. Overall, these changes yield a better learning curve while consuming only 14.1 GB of GPU RAM.
I have also updated the related article to reflect these changes:

The Salt
In The Salt this week, I reviewed:
Resonance RoPE: Improving Context Length Generalization of Large Language Models
DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models
⭐GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Teaching Large Language Models to Reason with Reinforcement Learning

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!