


The Weekly Kaitchup #18
FP8 inference - URIAL - Gemini evaluation


Hi Everyone,
In this edition of The Weekly Kaitchup:
FP8 Inference with Optimum-NVIDIA
Towards the End of Fine-tuning for LLM alignment?
Gemini: A New State of the Art with a High Scientific Credibility
The Kaitchup has now 1,216 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
FP8 Inference with Optimum-NVIDIA
Hugging Face and NVIDIA released Optimum-NVIDIA: a new library optimizing inference for NVIDIA GPUs.
For instance, on the NVIDIA H100, inference with Llama 2 70B is 28x faster with Optimum-NVIDIA and reaches an inference speed of 1,200 tokens/second (batch size of 4).
The library also optimizes the support for FP8 inference but only for the GPUs using the NVIDIA Ada Lovelace (RTX 40xx GPUs) and Hopper (H100 GPU) architectures. I wonder whether this would work with FlashAttention 2 to further accelerate inference.

For now, there isn’t a package available with pip to install optimum-nvidia. To try it, you can use docker:
docker pull huggingface/optimum-nvidiaThen, import from the optimum-nvidia library instead of transformers in your code. For instance for Llama models, import:
from optimum.nvidia import LlamaForCausalLMTowards the End of Fine-tuning for LLM Alignment?
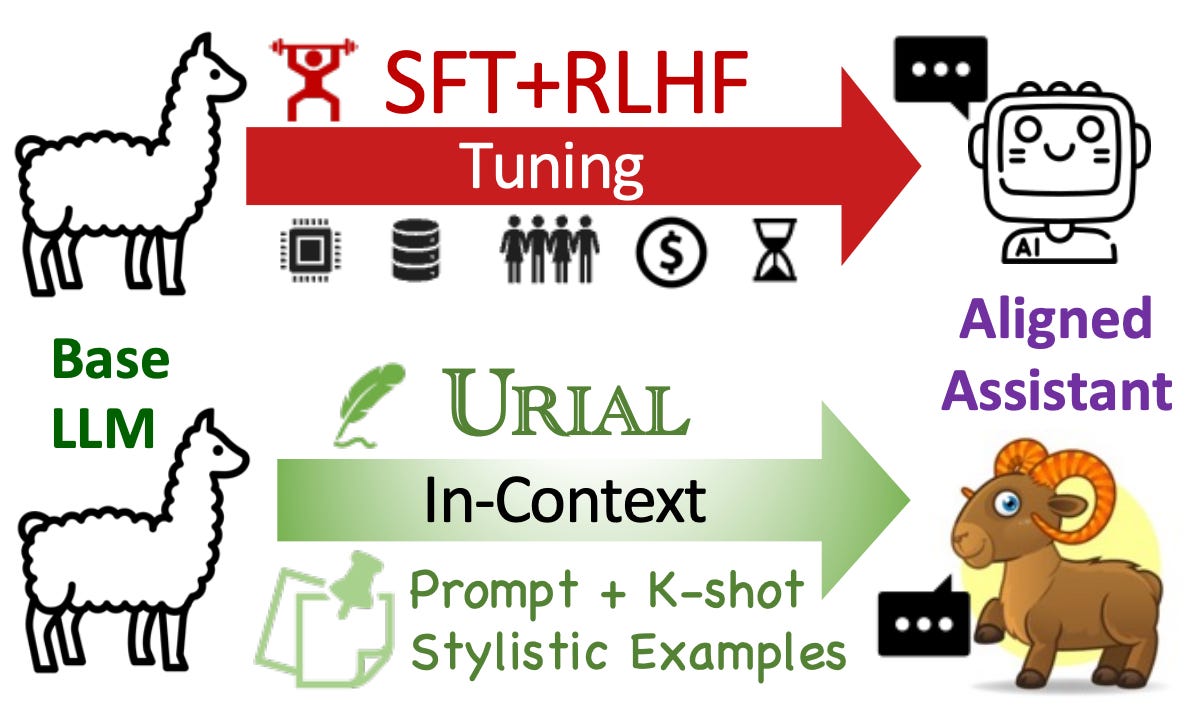
A new research work by the Allen Institute for AI (AI2) has demonstrated that LLM alignment with human preferences doesn’t require an additional training step as usually done with DPO, RLHF, or IPO.
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
They show that few-shot in-context learning (ICL) is often enough, or even better than, alignment training. In other words, we only need to find the best formulation for the instructions and a few examples in the style we want the model to reproduce to align it with human preferences.
They recommend putting in the context (prompt) between 3 and 8 high-quality examples of instructions paired with outputs in the expected style.
To find the right examples and instructions format, their method denoted URIAL for Untuned LLMs with Restyled In-context ALignment, only requires some analysis of the token distribution and strategic prompting (more details in their paper). You can find prompt examples in the GitHub repository (Apache 2.0 license).
Here are the comparisons between instruct LLMs and pre-trained LLMs using URIAL.

I would have imagined that, indeed, good prompting could be enough to align large LLM, e.g., with more than 35B parameters, since they are already well-trained and have the capacity (thanks to their huge number of parameters) for good ICL. But AI2 shows that URIAL also works very well for smaller models such as Mistral 7B.
However, since URIAL requires examples to be included in the prompt, it can have a significant impact on the inference time. Caching and buffering help to reduce this impact but the offline nature of fine-tuning for LLMs remains a significant advantage.

Gemini: A New State of the Art with a High Scientific Credibility
LLMs tend to be poorly evaluated by their creators. They are often using wrong or outdated metrics while including the evaluation benchmarks in the (pre-)training data.
Nonetheless, with the recently published LLMs, we can see that more effort is made towards more credible evaluations (from a scientific point of view).
This week, Google released Gemini along with a technical paper evaluating the model against other LLMs such as GPT-4 on numerous public benchmarks.
They claim that they have removed the benchmarks from training data (Section 4 of the paper), hence avoiding data contamination:
We apply quality filters to all datasets, using both heuristic rules and model-based classifiers. We also perform safety filtering to remove harmful content. We filter our evaluation sets from our training corpus.
OpenAI and Meta for instance don’t do that. They usually do the opposite by removing the training data from the benchmarks which is problematic for many reasons.
Note however that Google doesn’t provide any technical information on how this filtering has been done. We have to trust that it has been correctly done.
Gemini seems to be outperforming GPT-4 on most of the benchmarks. In my opinion, the most impressive is their result in multilingual tasks. Gemini knows many languages. It is very good at machine translation, even on recent benchmarks such as WMT23. They also didn’t use the metric BLEU for their machine translation evaluation but BLEURT which is much better.

What to Read on Substack
Note: These recommendations are articles that I’ve read, found instructive, and that I think may interest The Kaitchup’s readers.


That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!