


The Weekly Kaitchup #11
VeRA - Flash-Decoding - DistillSpec


Hi Everyone,
In this edition of The Weekly Kaitchup:
VeRA: LoRA but 10x Smaller
8x Faster Inference with Flash-Decoding
DistillSpec: Faster LLM inference using Speculative Decoding
I’m preparing two articles/tutorials on the very popular Mistral 7B. Expect the first article in your mailbox by Monday. The related notebook might be available today or tomorrow on the notebook page (#22).
The Kaitchup has now 794 subscribers. Thanks a lot for your support!
If you are a free subscriber, consider upgrading to paid to access all the notebooks and articles. There is a 7-day trial that you can cancel anytime.
If you are a monthly paid subscriber, switch to a yearly subscription to get a 17% discount (2 months free)!
VeRA: LoRA but 10x Smaller
LoRA has been introduced in 2022 to improve fine-tuning efficiency. It adds low-rank (i.e., small) tensors on top of the model to fine-tune. The model’s parameters are frozen. Only the parameters of the added tensors are trainable.
It greatly reduces the number of trainable parameters compared to standard fine-tuning. For instance, for Llama 2 7B, LoRA typically trains between 4 and 50 million parameters, against 7 billion for the standard fine-tuning.
However, the number of LoRA’s trainable parameters can be much larger than that. It increases with the rank of the tensors (often denoted r in LoRA) and the number of target modules. If we want to target all the modules of the model (which is recommended to achieve optimal performance) with a large rank r (let’s say, greater than 64), then we may still have to train several hundred million parameters.
This week, VeRA has been introduced to further reduce the number of LoRA’s trainable parameters.
VeRA: Vector-based Random Matrix Adaptation (Kopiczko et al., 2023)

VeRA simply adds trainable vectors on top of the LoRA’s frozen low-rank tensors. Only the added vectors are trained in VeRA. In most of the experiments shown in the paper, VeRA trains 10 times fewer parameters than the original LoRA.
But what about the original low-rank tensors (A and B on the illustration)? How are they trained or initialized?
A and B are randomly initialized and then frozen. They may look like two useless tensors that we could get rid of in this framework. Actually, they are still essential. Even random tensors can be useful for training. Previous work showing it is introduced in Section 2 of the paper. The authors conclude from previous work:
Collectively, these works create a compelling case for the utilization of frozen random matrices in finetuning methods, providing both a theoretical and an empirical foundation for the approach taken in this paper.
To the best of my knowledge, the authors didn’t release their implementation yet.
8x Faster Inference with Flash-Decoding
Inference with long contexts is slow. This is mainly due to the computation of the attention which has quadratic complexity. During decoding, new tokens that are generated attend to all previous tokens, hence the increasing computational cost as the length of the context increases.
To mitigate this increasing computational cost, Dao et al. propose Flash-Decoding. It is based on FlashAttention but adds a new parallelization dimension: the keys/values sequence length. It works as illustrated below.
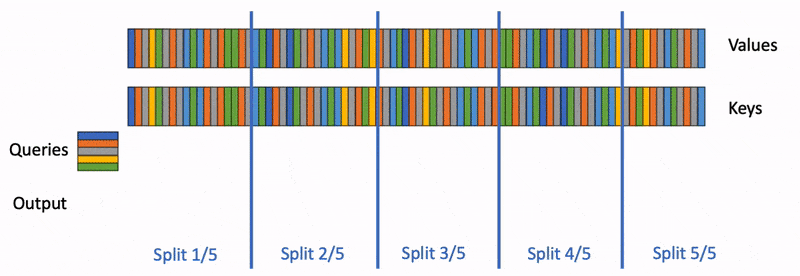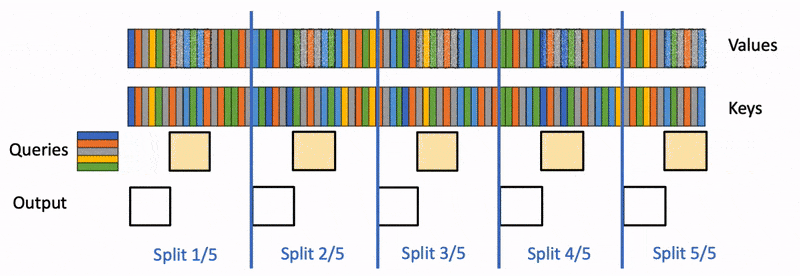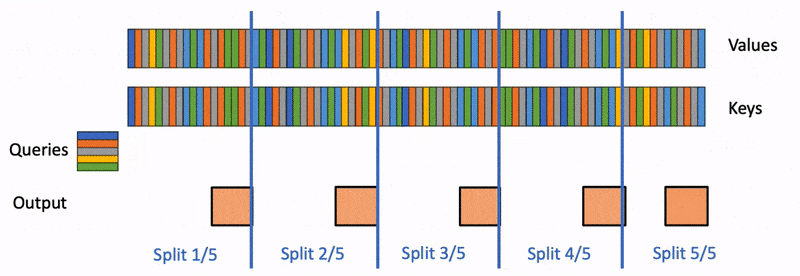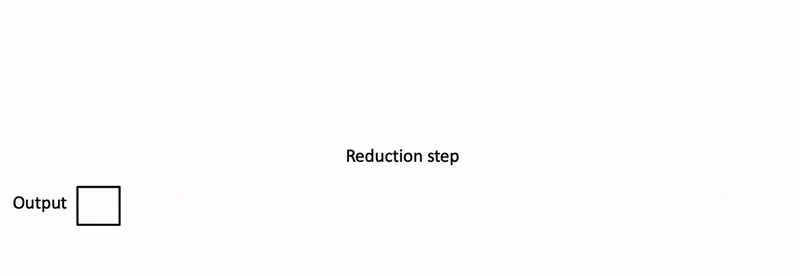
There are 3 steps:
Split the keys/values into smaller chunks.
Use FlashAttention to compute in parallel the attention of the query for each split obtained at step 1. The log-sum-exp of the attention values is also written as one extra scalar per row and per split.
The output is computed given all the splits, using the log-sum-exp to scale the contribution of each split.
In contrast with FlashAttention which is particularly efficient for training, Flash-Decoding is optimized for inference. It also fully exploits the GPU.
The evaluation conducted by Dao et al. shows that Flash-Decoding is significantly faster than previous work, especially for long contexts.

You can find more details in this blog post and an implementation in the FlashAttention repository, from version 2.2.
DistillSpec: Faster LLM inference using Speculative Decoding
Speculative Decoding is a fast inference algorithm exploiting a fast “draft” model that “speculates” on blocks of tokens that should be generated. Then, at each step, the “target” model that we actually want to use for generation will check the tokens speculated by the draft model. How much faster will it be compared to standard decoding depends on how often the speculated tokens are approved by the target model.
DistillSpec proposes to further improve speculative decoding with the introduction of knowledge distillation (KD).
DistillSpec: Improving Speculative Decoding via Knowledge Distillation (Zhou et al., 2023)
It trains the draft model to be aligned with the target model by minimizing their divergence. Thanks to the better alignment, the acceptance rate is better, and consequently decoding is faster.
In this work, they tried several strategies for distillation. They found that the best strategy depends on the downstream task.

That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers:
Have a nice weekend!