
Fixing Faulty Gradient Accumulation: Understanding the Issue and Its Resolution
Years of suboptimal model training?


When fine-tuning large language models (LLMs) locally, using large batch sizes is often impractical due to their substantial GPU memory consumption. To overcome this limitation, a technique called gradient accumulation is commonly used to simulate larger batch sizes. Instead of updating the model weights after processing each batch, gradient accumulation involves summing the gradients over several smaller mini-batches. The model weights are updated only after a predetermined number of these mini-batches have been processed. This method effectively mimics training with a larger batch size without the memory overhead typically associated with it.
For instance, setting a mini-batch size of 1 and accumulating gradients over 32 mini-batches should be equivalent to training with a full batch size of 32. However, about two weeks ago, I discovered that gradient accumulation often results in significantly degraded performance compared to training with larger actual batch sizes.
After sharing this issue on X and Reddit, Daniel Han from Unsloth AI replicated the problem. He found that it was affecting not only gradient accumulation but also multi-GPU setups. In such configurations, gradients are implicitly accumulated across multiple devices, leading to suboptimal model training due to this issue. This suggests that we may have been unknowingly training less-than-optimal models for years.
In this article, I’ll start by explaining gradient accumulation, providing examples to illustrate the problem and what the faulty accumulation process entailed. We'll explore which training scenarios were likely the most and least affected by this issue. We will then test the correction implemented by Hugging Face in Transformers.
For reference, here is the notebook I used to test gradient accumulation and draw the learning curves for this article:
Gradient Accumulation in a Nutshell
What Happens During Training
When training a neural network, each batch of training examples goes through a few steps: a forward pass to make predictions, calculating a loss (the difference between predictions and actual values), and a backward pass to compute gradients (the adjustments needed for model weights to minimize this loss). Normally, once the gradients are computed for a batch, they’re used to update the model’s weights immediately.
Using larger batch sizes (more training samples at a time) often leads to more stable training and can improve the model’s performance and generalization. However, large batch sizes require more memory, especially for computing and storing gradients. When memory is limited, we may not be able to fit a large batch into memory all at once, which limits how big our batches can be.
How Gradient Accumulation Solves This
Gradient accumulation allows us to train with a large "effective batch size" by breaking it into smaller "mini-batches." Instead of updating the model’s weights after every mini-batch, we accumulate gradients over multiple mini-batches and only update the weights after processing all mini-batches in what’s called an "accumulation step."
Here’s how it works:
We set a target effective full batch size and a mini-batch size that fits in memory. For example, if we want an effective batch size of 64 but can only fit 16 samples in memory at once, we’ll need to accumulate gradients over 4 mini-batches of size 16.
During training, for each mini-batch, we perform a forward pass, compute the loss, and perform a backward pass to calculate the gradients. Instead of updating the weights immediately, we add these gradients to an "accumulated gradients" buffer.
After processing enough mini-batches to reach the desired effective batch size (in this case, 4 mini-batches of 16), we average the accumulated gradients and use this average to update the model’s weights. Then, we clear the accumulated gradients and repeat the process for the next set of mini-batches.
Typical Use Cases for Gradient Accumulation
Recent models, such as LLMs and VLMs, are very large. They are often larger than what the GPU memory can handle to make large batch sizes.
Some examples of use cases for gradient accumulation are:
Training large models on limited memory: Models like large Transformers or convolutional neural networks (CNNs) for image tasks require substantial memory. Gradient accumulation allows the training of these models with effective batch sizes that would otherwise exceed memory limits.
Distributed training across multiple devices: Gradient accumulation can also reduce synchronization frequency in multi-device setups. Instead of synchronizing after every mini-batch, devices accumulate gradients locally and only synchronize after a full accumulation step, reducing communication overhead.
In other words, gradient accumulation is almost always used to train (pre-train, fine-tune, post-train, etc) models.
The Problem: A Faulty Normalization When Accumulating the Gradients
Using a batch size of N examples is mathematically equivalent to using 4 mini-batches of N/4 examples with gradient accumulation.
Except it wasn’t.
Unsloth explained very well the issue and how they fixed it in this blog post:
Bugs in LLM Training - Gradient Accumulation Fix
Gradient accumulation and full batch training are not mathematically equivalent if applied naively by simply summing the gradients. The cross-entropy loss used to train most LLMs is typically computed by normalizing over the number of non-padded or non-ignored tokens, ensuring that the loss is divided by the number of tokens being trained in each sequence. To simplify the analysis, we assume the length of each sequence is equal to the mean length of the entire dataset.
When using gradient accumulation, each loss is calculated independently, for each mini-batch, and then summed, but this approach results in a total loss that is G times larger (where G is the number of gradient accumulation steps) compared to the full batch loss. To correct this, we must scale each accumulated gradient by G to match the original full batch result. This scaling approach holds only if the sequence lengths across mini-batches are consistent.
However, varying sequence lengths, which are common when training models like LLMs, can introduce discrepancies in how losses are calculated.
In tasks such as causal language model training, the correct approach when using gradient accumulation is to calculate the total loss across all batches during the accumulation step and then divide it by the total number of non-padding tokens across those batches. This differs from simply averaging the loss for each batch individually. Note: The first time I saw this as a possible explanation for this problem was here actually, in a comment dropped by Remixa in The Weekly Kaitchup.
If you are unfamiliar with padding, I recommend reading this to better understand how it impacts the batches:

The problem has been very well illustrated on X by shxf0072:

It also means that if we have mini-batches with sequences of the same length, without padding, gradient accumulation as we were doing would be fine.
In practice, I suspect the pre-training stage of LLMs has almost not been affected by this issue. While pre-training LLMs require many GPUs (i.e., "accumulate" a lot of gradients), this stage usually exploits full gigantic batches containing big chunks of documents without any need to pad. Pre-training maximizes what the model will learn during one training step. Note: This is also why many LLMs are released without padding tokens in their vocabulary since padding wasn’t used during pre-training.
Hugging Face worked with Unsloth to fix gradient accumulation with an approach close to this code that they published in their blog post:
def ForCausalLMLoss(logits, labels, vocab_size, **kwargs):
# Upcast to float if we need to compute the loss to avoid potential precision issues
logits = logits.float()
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
shift_logits = shift_logits.view(-1, vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
num_items = kwargs.pop("num_items", None)
+ loss = nn.functional.cross_entropy(shift_logits, shift_labels, ignore_index=-100, reduction="sum")
+ loss = loss / num_items
- loss = nn.functional.cross_entropy(shift_logits, shift_labels, ignore_index=-100) # how it was computed before
return loss
The Impact of Buggy Gradient Accumulation
To see the impact of the faulty gradient accumulation on the training loss, I fine-tuned SmolLM-135M (Apache 2.0 license), using Unsloth, with different batch sizes, gradient accumulation steps, and sequence lengths.
I used Unsloth (Apache 2.0 license), which is memory-efficient, and a small LLM to be able to use a large batch size for fine-tuning on a 48 GB GPU (an A40 provided by RunPod (referral link)).
For large gradient accumulation steps
First, let’s confirm that gradient accumulation is buggy. The following settings should yield nearly identical learning curves:
per_device_train_batch_size = 1 and gradient_accumulation_steps = 32
per_device_train_batch_size = 32 and gradient_accumulation_steps = 1
per_device_train_batch_size = 2 and gradient_accumulation_steps = 16
per_device_train_batch_size = 16 and gradient_accumulation_steps = 2
The total training batch size is always 32.
We are not interested here in the absolute loss values but in the differences between the loss of these configurations.
The learning curves with sequences of 2048 tokens (the maximum sequence length supported by SmolLM):

The learning curves with sequences of 512 tokens (the maximum sequence length supported by SmolLM):

The difference between configurations using a batch size (bs) of 32 and gradient accumulation steps (gas) of 32 is quite significant. As expected, this difference is reduced when using a smaller gas of 16.
It seems that the gas=32 configuration will never fully match the loss of bs=32. I measured the loss differences between them, which mostly stayed around 0.2 to 0.3 for sequences of 2048 tokens, and between 0.1 and 0.2 for sequences of 512 tokens.
The configuration with 2048-token sequences is more impacted, suggesting that having more padded sequences within each mini-batch amplifies the discrepancy.
For batches with very diverse sequence lengths
We can artificially worsen the issue by intentionally creating mini-batches with highly varying sequence lengths. For example, consider a scenario where the maximum sequence length is 2048 tokens. If one mini-batch contains a sequence of just 1 token (with 2047 padding tokens), while another contains a full sequence of 2048 tokens (with no padding), the gradient accumulation will be significantly skewed because of the stark difference in sequence lengths.
We can simulate a high diversity of sequence lengths by removing sequences of common lengths from our fine-tuning dataset. After analyzing the length distribution, I retained only sequences shorter than 256 tokens and those longer than 1024 tokens to amplify the disparity in sequence lengths.
The learning curves:
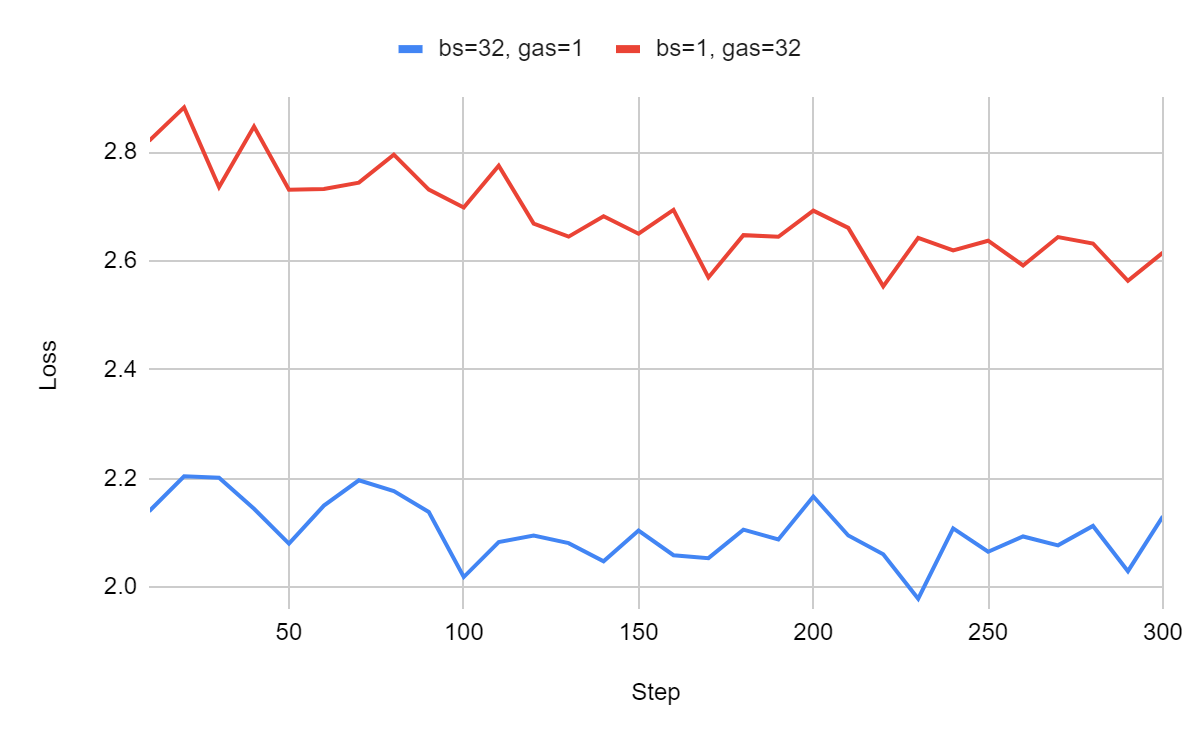
The difference is amplified, as expected, the extreme variation (and sparsity) of the sequence length worsens the results. The difference between the loss remains between 0.45 and 0.70.
What does it mean? Because of this issue, training configurations using datasets with a wide range of sequence lengths may have significantly underperformed.
For batches with the same sequence length
Finally, while large variations in sequence lengths worsen the results when using gradient accumulation, we can expect the impact to be less pronounced when working with datasets where all sequences have a similar length. In such cases, the gradient accumulation issue should be minimized.
To simulate this scenario, I set the maximum sequence length to 1024 and filtered the fine-tuning dataset to include only sequences with 1024 tokens or more. In this setup, no sequences are padded, and any sequences longer than 1024 tokens are truncated.
All the sequences in all the mini-batches have the same length:
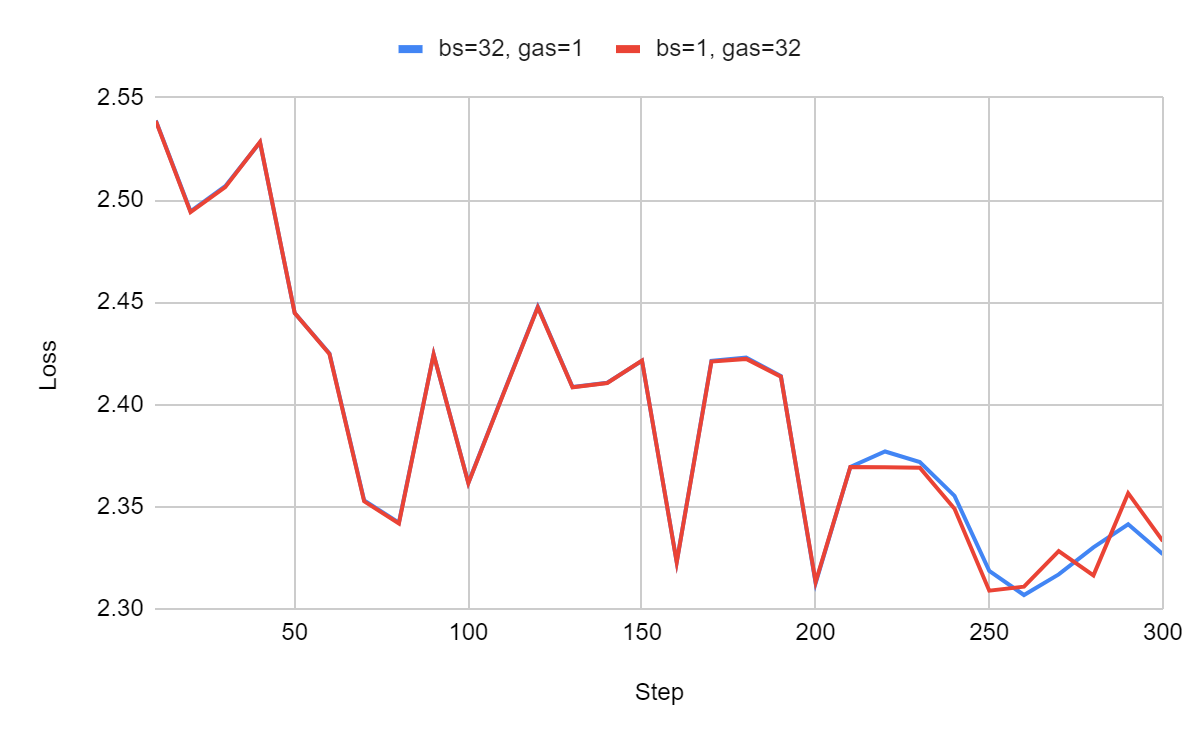
As expected, the learning curves are nearly identical. However, a slight difference emerges after around 210 training steps, which I believe is due to minor approximations introduced by the 8-bit quantized AdamW optimizer I used to reduce memory consumption.
This empirically confirms that when sequences are of uniform length, gradient accumulation functions as intended. As previously mentioned, the pre-training phase of LLMs hasn’t (probably) been significantly affected by this issue. During pre-training, sequences are seldom padded, as LLM developers maximize the number of tokens in each batch to avoid wasting memory on padding.
The Fixed Gradient Accumulation
Now, we want to check that with the fix proposed by Unsloth and implemented by Hugging Face, the learning curves with and without gradient accumulation are (almost) identical.
We have to upgrade Transformers. Since the update has been pushed recently, I upgraded from source:
pip install --upgrade --no-cache-dir "git+https://github.com/huggingface/transformers.git"The learning curves for a maximum sequence length of 2048:
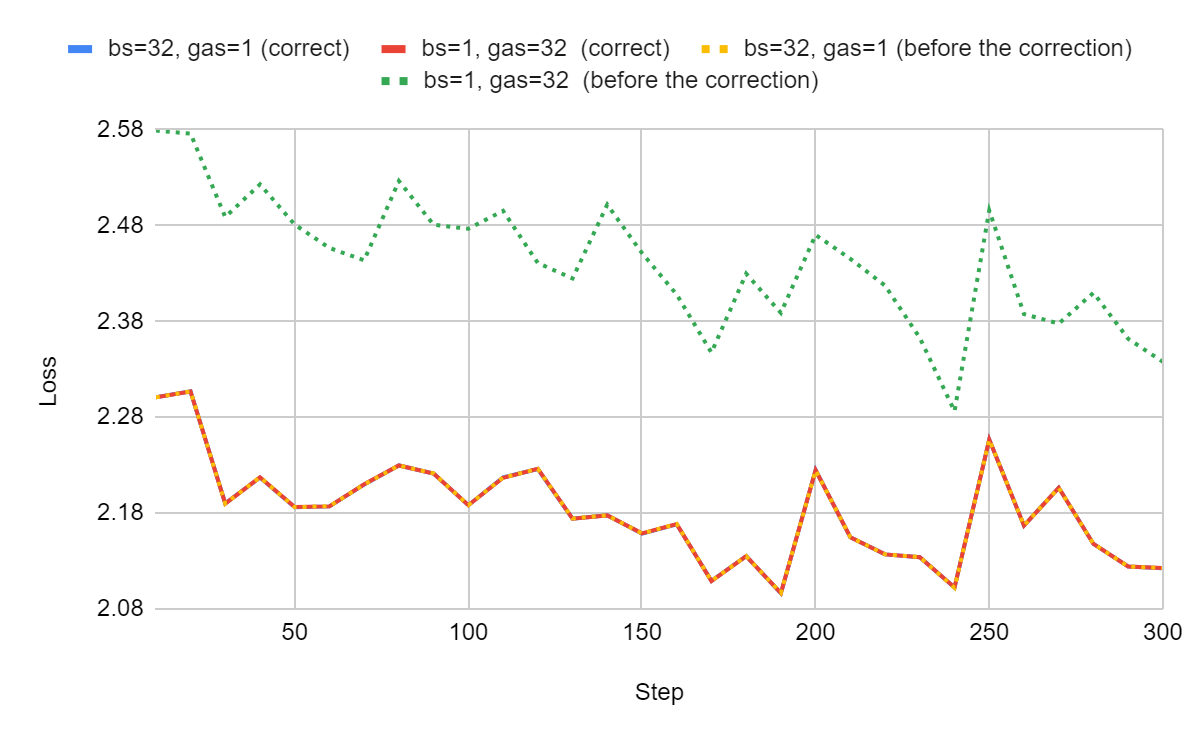
It works! bs=32, gas=1 and bs=1, gas=32 are now aligned. The gradient accumulation is correct. We can’t see them on this figure but it remains very tiny differences of up to 0.0004 for some training steps. I assume they are due to the numerical approximations introduced by the quantization of AdamW.
Conclusion
Given that this issue affects how gradients are accumulated across multiple devices and mini-batches, it’s plausible that some model performance results may have been suboptimal for years.
The critical question is whether this bug has a measurable impact on downstream tasks. I would argue that it likely does, depending on the training configurations used, particularly the number of GPUs and gradient accumulation steps involved. Models trained with large gradient accumulation steps or highly varied sequence lengths may have suffered from less effective learning, potentially leading to worse performance on various downstream tasks.
Now that this issue has been identified and corrected in Hugging Face Transformers, future model fine-tuning and training efforts should yield better and more consistent results. For those in the research community or industry who used frameworks impacted by this issue, it may be worth revisiting past results to reassess whether training with corrected gradient accumulation yields significant improvements.
In conclusion, while the exact scope of the issue’s impact remains uncertain, it is clear that models trained with faulty gradient accumulation could have been better trained.
Wow. I remember when minibatch/batch normalization/gradient accumulation was offered as a performance improvement to lessen the number of weight updates in backpropagation. Carried forward because that's how it's always been done.
Now we await differences in model performance after the Transformers change.
Glad to see it fixed!