
SlimQwen Compression, Elastic Models, and Aurora Optimization
The Weekly Kaitchup #142


Hi everyone,
In this edition of The Weekly Kaitchup, let’s discuss:
SlimQwen: How the Small Qwen3.6 Are Trained?
Elastic LLMs: Many Models Inside One Checkpoint
Aurora: 100x Data Efficiency for LLM Training?
A $35 Coupon to Try Verda
In collaboration with Verda, I’m sharing a $35 coupon that you can redeem in your Verda account to try their platforms. That’s enough to try an RTX Pro 6000 for almost a full day, or a B200 for about 7 hours.
Coupon code:
KAITCHUP-35Follow these instructions to redeem it.
SlimQwen: How the Small Qwen3.6 Models Are Trained
Alibaba’s Qwen researchers shared how large mixture-of-experts language models can be compressed into smaller, cheaper models without starting from scratch.
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
In this paper, SlimQwen, studies structured pruning and knowledge distillation, compressing Qwen3-Next-80A3B into a 23A2B model while retaining competitive performance. The paper doesn’t directly talk about Qwen3.5/Qwen3.6, but these models adopt the same architecture as Qwen3-Next, and the author confirmed that’s what they did to train the smaller Qwen3.5/3.6 models:



The core recipe: prune, then recover
This reminds me a lot of what NVIDIA did with Minitron, one year ago, although SlimQwen is much more complex/advanced.
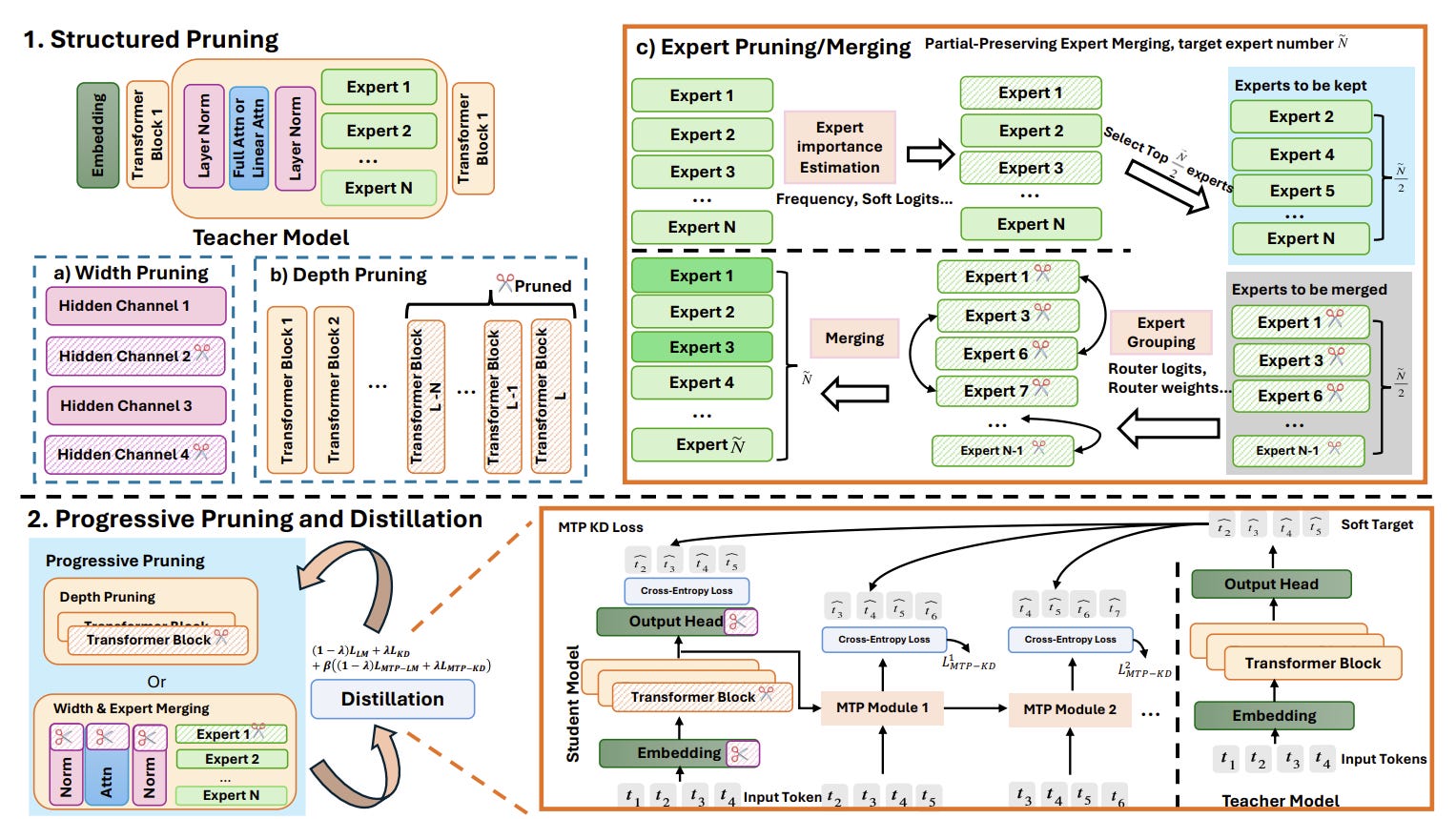
SlimQwen begins with a pre-trained MoE teacher and removes structure in three places: depth, width and experts. For depth, the authors drop the last quarter of layers. For width, they keep hidden dimensions judged important by activation statistics on a calibration set.
For experts, they compare pruning and merging strategies, including a new partial-preservation method that keeps roughly half of the target experts intact and builds the rest by merging discarded experts into similar retained ones.
The key finding is that pruning a strong teacher gives the smaller model a better starting point than random initialization. In the paper’s 120B-token comparison, a pruned model trained with the combined distillation objective averaged 73.45 across benchmarks, compared with 61.66 for a randomly initialized student trained under the same budget. The authors said the pruned student recovered 86.5% of the teacher’s average score despite being about 3.4 times smaller.
Distillation
The training stage combines standard language modeling loss with knowledge distillation, rather than relying on distillation alone. SlimQwen also adds multi-token prediction distillation, supervising future-token predictions to improve both the main model and speculative decoding behavior. The full objective combines backbone language modeling, backbone distillation, MTP language modeling and MTP distillation.
In the authors’ ablations, adding language modeling loss improved knowledge-heavy benchmarks, while MTP distillation produced broader gains. The full objective posted the strongest overall balance among the tested losses.
Gradual compression beats one-shot shrinking
Qwen also found that a smaller model trains better when the architecture transition is staged. A one-stage 400B-token run was generally beaten by two-stage progressive pruning, where the model is first partially compressed and trained for 40B tokens, then compressed again and trained for another 360B tokens. The depth-first SlimQwen schedule reached 77.39 on MMLU and 78.01 on MMLU-Redux, compared with 75.86 and 75.41 for one-stage pruning.
Elastic LLMs: Many Models Inside One Checkpoint
Instead of releasing three separately trained models, NVIDIA embeds several nested variants inside a single checkpoint: 30B, 23B, and 12B parameters, derived from Nemotron 3 Nano, and all sharing the same parameter space. The smaller models can then be extracted by slicing the full checkpoint (slicing is provided in the model’s repository), without additional training or fine-tuning.
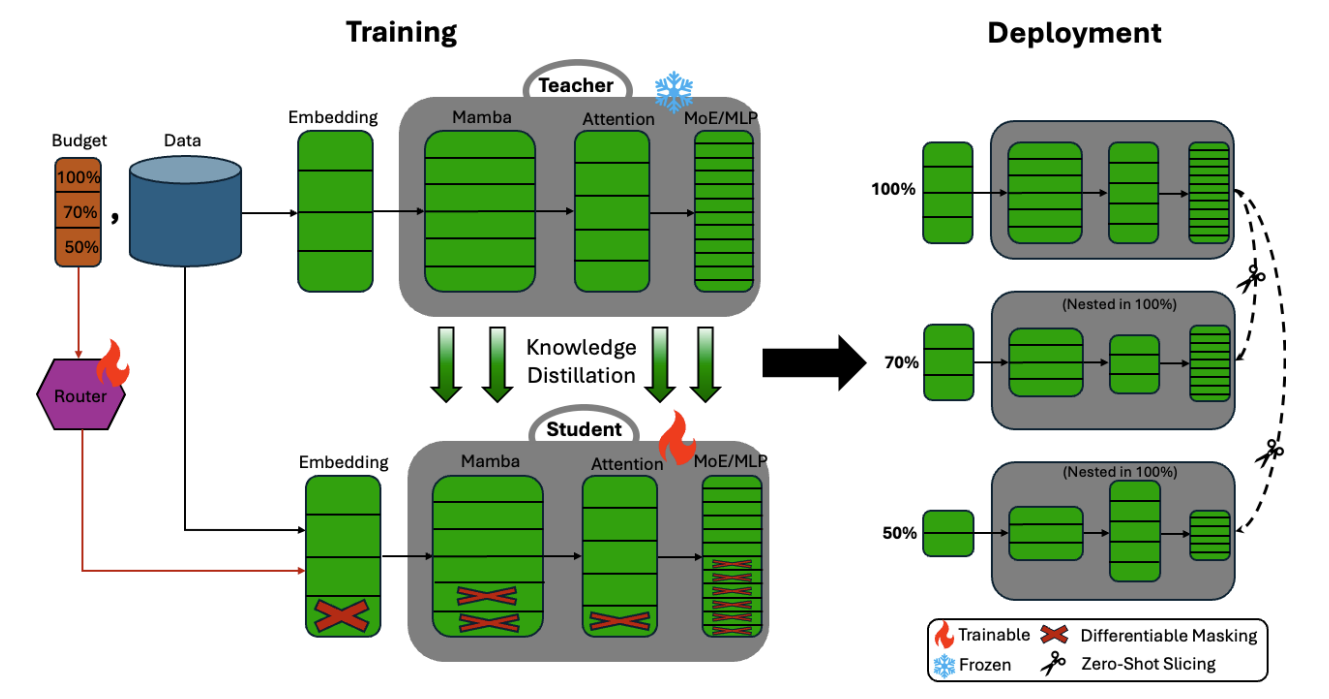
How is this different from Gemma 3n/4 E2B and E4B?
Gemma 3n uses a MatFormer architecture where the larger E4B model contains the smaller E2B model, enabling elastic inference and intermediate sizes between roughly 2B and 4B effective parameters. Nemotron Elastic is conceptually similar, but applies the idea to a much larger hybrid Mamba-Transformer-MoE reasoning model.
The immediate benefit is deployment flexibility. You can store one BF16 checkpoint and derive smaller variants for cheaper serving. NVIDIA reports that storing the 12B, 23B, and 30B elastic variants together requires 58.9 GB, compared with 126.1 GB for three independent checkpoints. The smaller variants also serve faster: the 23B version is reported at 1.8× the throughput of the 30B baseline, and the 12B version at 2.4×.
But the more interesting idea is elastic budget control.
Reasoning models spend many tokens in the thinking phase, then produce a shorter final answer. Nemotron Elastic proposes using different model sizes for these two phases. For instance:
23B model: generate the reasoning trace
30B model: produce the final answerThe thinking phase is token-heavy, so using a smaller model there saves a lot of compute. The final answer is shorter but requires better instruction following, consistency, and synthesis, so using the larger model there can preserve quality.
In other words, elastic models can make compute allocation more granular:
small model for exploration
large model for final synthesisThat is a more natural fit for reasoning LLMs than simply choosing one fixed model size for the whole generation.
The caveat is that this is not yet a standard inference path. NVIDIA notes that switching nested submodels inside one generation, such as 23B → 30B between thinking and answering, is not currently supported by standard vLLM. It requires a custom inference path, although native support is being worked on.
Check the paper: Star Elastic: Many-in-One Reasoning LLMs with Efficient Budget Control
Aurora: 100x Data Efficiency for LLM Training?
Tilde Research says its new optimizer, Aurora, can deliver sharply better data efficiency for language model pre-training by fixing a failure mode in Muon-style optimization, which is now used by most LLMs during pre-training.
Aurora: A Leverage-Aware Optimizer for Rectangular Matrices
They wrote that their Aurora-trained 1.1B model achieved “100x data efficiency” on several benchmarks, while adding only about 6% overhead over traditional Muon in its untuned form.
What Aurora is
Aurora is a leverage-aware optimizer for non-square matrices, especially the tall and big matrices found in MLP up and gate projections. Tilde argues that Muon leaves some MLP neurons with persistently tiny updates early in training. Those neurons can effectively “die,” wasting a portion of the model’s capacity.
Aurora tries to preserve Muon’s useful orthogonalization while also enforcing more uniform row update norms. It iteratively projects toward a joint constraint: keep updates orthogonal enough while spreading update mass more evenly across rows.
The 100x claim
Tilde says 1.1B-parameter model trained on roughly 100B tokens matches or approaches Qwen3-1.7B, which it describes as trained on 36T tokens, on HellaSwag and Winogrande despite using two orders of magnitude fewer tokens, fewer parameters and an uncurated data mixture.
The researchers emphasize that the Aurora-1.1B run was meant to isolate the optimizer. They said they did not rely on special data, architecture tricks or distillation, and noted that the model was trained on about 100B tokens of Nemotron-CC without explicit math or science data. That helps explain why the results look stronger on some language-understanding benchmarks than on knowledge-heavy tests such as MMLU.
I’m curious whether it could also improve Muon’s performance with LoRA, where Muon largely underperforms AdamW. Intuitively, Muon “killing” a significant number of neurons could explain why it struggles with LoRA, since LoRA already has a very small number of trainable parameters.
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!
‘Intuitively, Muon “killing” a sgnificantly numbers of the neurons could explain why it doesn’t work well for LoRA, whose number of trainable parameters is already tiny.’
Spelling / grammar issues.