


Scientific Credibility in Machine Translation Research: Pitfalls and Promising Trends
Are we at a turning point? My conclusions from the annotation of 1,000+ scientific papers


How do scientists assess an improvement in machine translation quality?
Mostly by using automatic evaluation metrics. A machine translation system with a better metric score is considered better.
Since improving metric scores is so important to demonstrate progress in machine translation, it is critical to understand how these metrics scores are computed and compared.
In 2021, I, with my colleagues Atsushi Fujita and Raphael Rubino, manually annotated and analyzed 761 machine translation evaluations published from 2010 to 2020 (Marie et al., 2021).
The results of our analysis were published by the ACL 2021, one of the most selective venues for machine translation publications. We showed that machine translation research lacked scientific credibility. We highlighted several pitfalls and concerning trends in machine translation evaluation.
I presented this work during the award session of the ACL 2021.
This was 2 years ago.
How has evaluation in machine translation research evolved since 2021 and this publication? Did it improve or get worse? What are the new trends?
I updated the analysis to include the machine translation research papers published in 2021 and 2022. The annotation methodology remains the same as the one used for the first analysis published at ACL 2021.
The dataset that I created is here:
A Meta-Evaluation Dataset of Machine Translation Research (May - 2023)
Annotations This dataset contains annotations of machine translation evaluations conducted in *ACL publications. If you…docs.google.com
In this blog post, I present my main findings.
The annotation of 1,000+ papers
For this study, I manually annotated a total of 1,023 papers (+254 papers compared to the original study published in 2021).
I selected the papers to annotate with the following criteria:
Published between 2010 and 2022 (included) by one of the top-tier ACL conferences: AACL, ACL, EACL, EMLP, NAACL, and CoNLL. I limited the study to ACL publications since they are the primary choice of researchers in machine translation to publish their best work. The papers submitted to ACL conferences undergo a double-blind peer review process. ACL conferences have low acceptance rates (almost always below 30% for the past 13 years). In other words, the papers published by the ACL are expected to be with high scientific credibility.
Have the words “translation” or “MT” in their title.
Report on the comparison between at least two machine translation systems.
Of course, this selection leaves out some papers but I judged that it contains enough articles to observe trends in machine translation research.
This set of papers doesn't include all the papers published by all the other ML/AI conferences that are not focused on NLP. They are far less numerous than the machine translation papers published by the ACL conferences, especially before 2015. Yet, I believe ML/AI papers focusing on machine translation could have their place in this study. Some of these papers are also very cited. I hope I will find the time, maybe this year, to extend this study to ICML, NIPS/NeurIPS, ICLR, IJCAI, and AAAI conferences.
What aspect of machine translation evaluation did I annotate?
Six different aspects of the evaluation:
the automatic metrics used
the use of a human evaluation
the statistical significance testing of the results and comparisons
the use of a framework, SacreBLEU, that facilitates the reproducibility of a machine translation evaluation
the comparison of metric scores copied from previous work
the comparison of machine translation systems not trained/validated/tested on the exact same datasets
All these aspects are particularly easy to annotate, but they are also informative enough to identify pitfalls and trends in machine translation research.
My main observations are as follows.
2021–2022: 100% BLEU
I listed all the automatic metrics used in evaluations comparing machine translation systems. I also regrouped under a single metric identifier all the variants of the same metrics. For instance, chrF and chrF++ are both labeled chrF.
BLEU (Papineni et al., 2002) is an extremely popular metric to evaluate machine translation despite its many flaws.
How many machine translation papers used BLEU?
Almost of all them have since 2010.

In 2020, 2021, and 2022, 100% of the annotated papers used BLEU.
This number doesn’t mean that the papers don’t use other metrics. They do. But papers using other metrics in addition to BLEU are a minority.

In 2021 and 2022, respectively 29.9% and 39.1% of the papers used other metrics. This is extremely low considering that countless other and better metrics than BLEU are available.
Traditional Versus Neural Metrics for Machine Translation Evaluation

100+ new metrics since 2010 An evaluation with automatic metrics has the advantages to be faster, more reproducible, and cheaper than an evaluation conducted by humans. This is especially true for the evaluation of machine translation. For a human evaluation, we would ideally need expert translators
But, on a positive note, we can see that these percentages are much higher than in 2020 which was the last year annotated in the first version of this work. Machine translation researchers tend to use a more diverse set of metrics.
Looking more closely, here are the metrics that were the most used in 2022, in addition to BLEU:
chrF: 10.0%
COMET: 10.0%
METEOR: 5.5%
TER: 4.5%
METEOR (Banerjee and Lavie, 2005) and TER (Snover et al., 2006) are old metrics published before 2010. Neural metrics, which are state-of-the-art for machine translation evaluation, are still rarely used. I can’t explain why. This is something I don’t understand.
Nonetheless, COMET (Rei et al., 2020), a neural metric, is more and more used. This is encouraging and I wouldn’t be surprised to see this percentage increasing in 2023.
The use of chrF (Popović, 2015) remains stable.
The rarity of human evaluation
Almost 100% of machine translation papers rely on automatic evaluation.
But how many also perform human evaluation?
Hiring humans to evaluate machine translation systems is extremely challenging and costly. Evaluators have to be bilingual and ideally native speakers of the language towards which we want to translate. Available evaluators are rare for most language pairs of the world.
This makes machine translation an unusual research area of natural language processing in which human evaluation is rare.
Yet, human evaluation remains ideal and should be conducted when possible.

In 2020, only 7.7% of the papers performed some kind of human evaluation to support the results of their automatic evaluation.
In 2021 and 2022, more than 10% of the papers performed human evaluation. This is a positive trend. I also noticed during my annotations that human evaluations are becoming more rigorous, better documented, and conducted at a larger scale than before.
Statistical significance testing is slowly coming back
When two systems are compared, deciding which one is better is not as simple as comparing the metric scores.
A metric score is only an overview of the performance of a system on a specific evaluation dataset.
We should test for the statistical significance of a score to make sure that a system didn’t get a better score by chance.
If you are interested, I already discussed why we need statistical significance testing in machine translation here:
Yes, We Need Statistical Significance Testing
A rule of thumb may yield correct results but can’t be scientifically credible. Take any research paper or blog post presenting a new method for AI, you’ll very probably find a statement similar to this: […] a significant improvement over previous work.
Do machine translation researchers perform statistical significance testing of their results?

They were. But since 2015 there was a constant decrease in the adoption of statistical significance testing. It is slowly coming back. In 2022, 43% of the papers tested the statistical significance of their results.
This leaves out 57% of papers claiming improvements in translation quality without checking whether their metric scores are coincidental.
This is still a lot. Yet, I think we are going in the right direction here.
Note: The importance of statistical significance testing is not unanimously recognized by the machine translation community. Renowned machine translation researchers are clearly against its systematic adoption. More generally, the necessity in Science of statistical significance testing is a controversial topic. You can find an interesting discussion about it in the work of Wasserstein et al. (2019).
Almost no more copies of scores from previous work
One of the most concerning trends I observed when publishing the first version of this work was the copy of scores from several previous works for comparisons.
Why is this concerning?
Let’s say paper A published a BLEU score of 30.0 and another paper B published a BLEU score of 35.0. You would conclude that B has a better score, right?
Well, we can’t conclude this. BLEU is not just one metric. It comes with many options and parameters that change the way it is computed. Some options artificially increase the scores.
This is very well discussed in the work of Post (2018).
We should never assume that two metrics scores published by two different papers are comparable. Very often, they're not.
This is concerning since it means that a paper may conclude that a proposed system is better simply because of the use of a BLEU variant that yields higher BLEU scores.
I demonstrated several times (e.g., here and here) that the comparison of copied scores can lead to wrong conclusions and make an entire evaluation false.
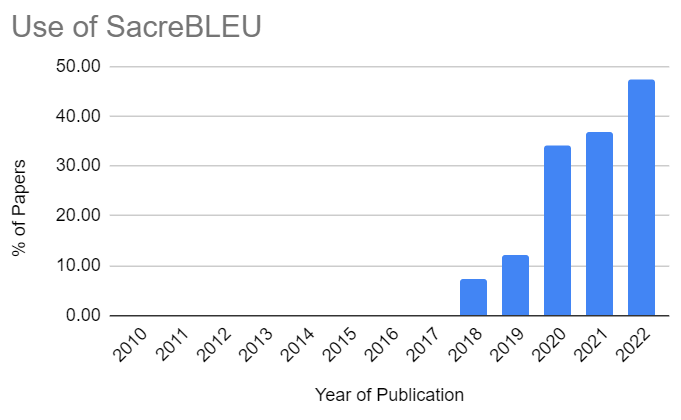
Researchers in machine translation have also a tool at their disposal to make sure their BLEU scores are comparable. This tool is SacreBLEU. SacreBLEU generates a signature that shows the parameters and evaluation data used for the computation of BLEU, among other information, for replicability. Two BLEU scores computed by SacreBLEU, with the same SacreBLEU signature, are comparable.
SacreBLEU is the only tool with this feature. It was released in 2018 and is used more and more in research papers. In 2022, 47.3% of the papers used SacreBLEU, a significant increase compared to 2021. But still, 52.7% of the research papers report on BLEU scores that are not replicable.
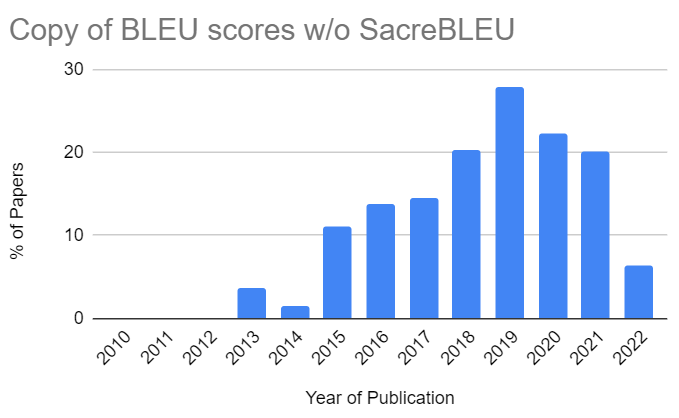
The good news is that the comparisons of BLEU scores copied from previous work without using SacreBLEU reached a peak in 2019, with 27.8% of the publications who adopted this practice:
We can see in the chart that we are getting rid of this practice. In 2022, only 6.4% of papers did it.
Conclusion: Toward more credible machine translation evaluations
Let’s draw the overall picture of the years 2021–2022 of machine translation evaluation. I’ll start with the bad:

43% of the papers still rely exclusively on non-replicable BLEU scores to conclude that their proposed method improves machine translation quality. They are not computed with SacreBLEU and are not supported by human evaluation or statistical significance testing.
Considering that BLEU is a 20-year-old metric with many well-identified flaws, there is here a very large margin for improvement in machine translation evaluation.
When I review machine translation papers for conferences and journals, I now systematically request the authors to provide more evidence than just BLEU scores.
I should also highlight that this reliance on BLEU seems to be decreasing, and BLEU scores are more and more often supported by other metrics since 2020.
Even better, the percentage of papers exhibiting all the different types of machine translation evaluation pitfalls is decreasing:
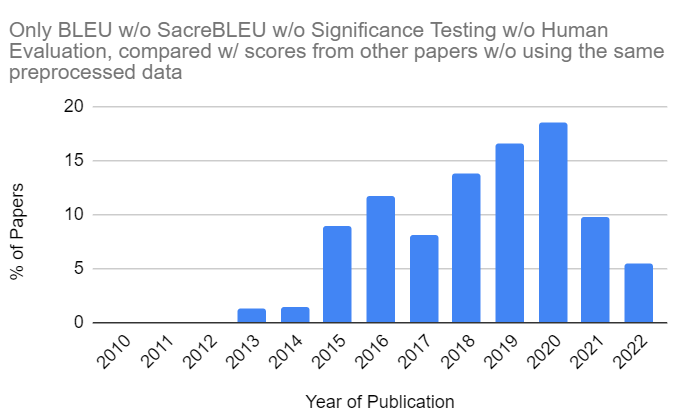
These problematic papers are:
Using only BLEU for automatic evaluation
Don’t use SacreBLEU so their scores are not replicable
Don’t perform a human evaluation
Don’t test the statistical significance of their results
Compare score(s) copied from different paper(s)
Directly compare systems trained, validated, and evaluated on different preprocessed datasets to claim that their proposed method is better
18.4% of the publications were in this category in 2020, against 5.5% in 2022.
This is a huge improvement in my opinion. Will 2023 confirm this trend? Let’s hope so!
To conclude, here are my recommendations for evaluating machine translation with scientific credibility:
Don’t exclusively rely on BLEU. Ideally, use two different metrics, one that I would call “traditional”, such as chrF (preferably not chrF++ which is tokenization-dependant), and another one that should be neural, such as COMET or BLEURT.
Don’t copy and compare scores published by previous work.
Perform human evaluation (if you have the budget and can find evaluators)
Perform statistical significance testing. If you don’t do it, we have no way to know how significant is the improvement.
Only compare translations generated by systems trained/validated/evaluated on the same datasets. If you change the datasets, we cannot conclude whether the improvement comes from the change in the data or from the proposed method. In other words, follow the scientific methodology.
I’ll continue to monitor machine translation evaluation.
The next update will be in 2024!