
Qwen3 Instruct "Thinks": When Token Budgets Silently Skew Benchmark Scores
Replicating Qwen3-30B-A3B-Instruct-2507 shows accuracy riding on verbosity, not just GSPO

A few weeks ago, the Qwen team shipped updated Qwen3 models with two goals:
Improve overall quality, and
Split the lineup into separate Instruct and Thinking variants.
This separation simplifies usage: the chat template is easier to use, and behaviors are clearer. Instruct models answer user prompts directly with human-readable, informative sequences of tokens. Thinking models first produce a reasoning trace, which then guides the final answer.
The Qwen team started by updating the Qwen3 MoE family, models that likely benefit most from GSPO reinforcement learning (as discussed in a previous article). I summarized their published MoE benchmarks, comparing the updates and the original versions, as follows:
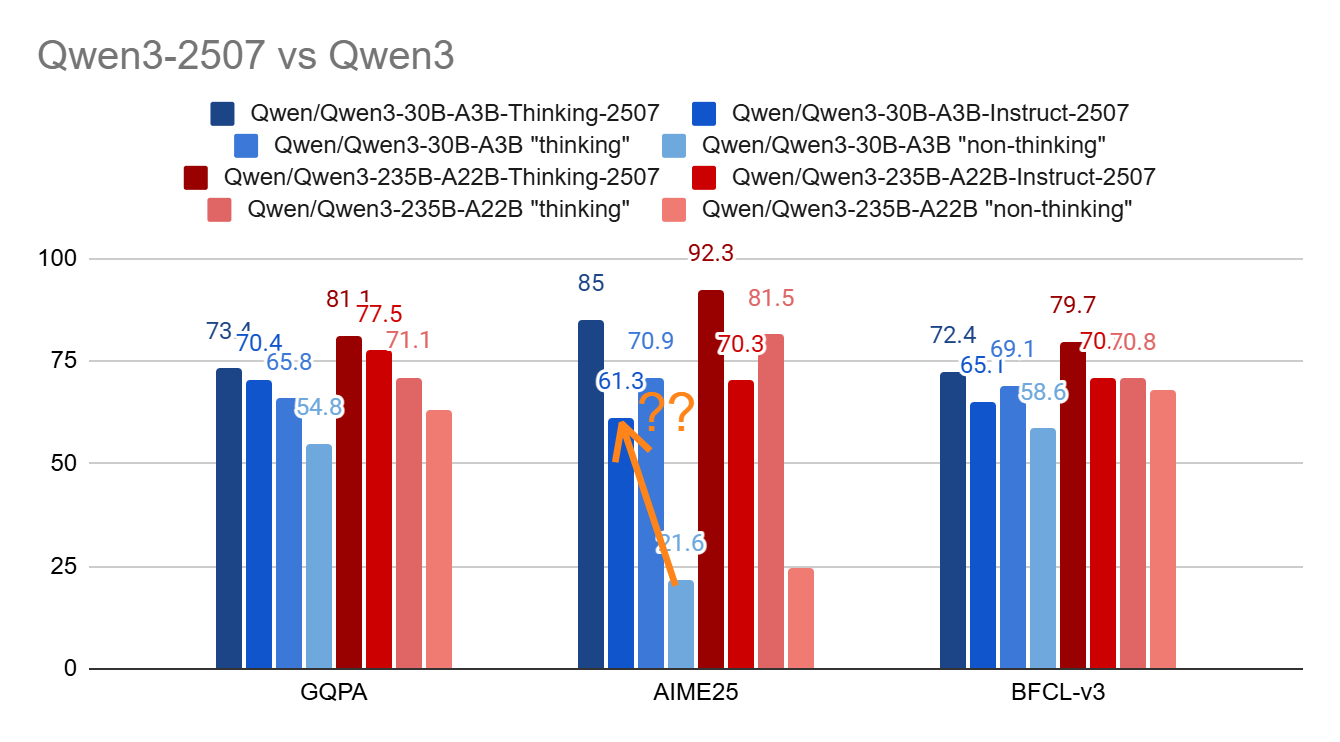
The gains are both impressive and puzzling. The Instruct version of Qwen3-30B-A3B-2507 improves by ~40 accuracy points on AIME25, a math benchmark that demands strong reasoning, over the previous non-thinking Qwen3. As far as I know, this would make it the first Instruct model to reach such a high score.
Is GSPO alone that good?
Things get stranger. The team also updated the Qwen3-4B dense models, architectures that shouldn’t, in theory, benefit as much from GSPO, and yet:
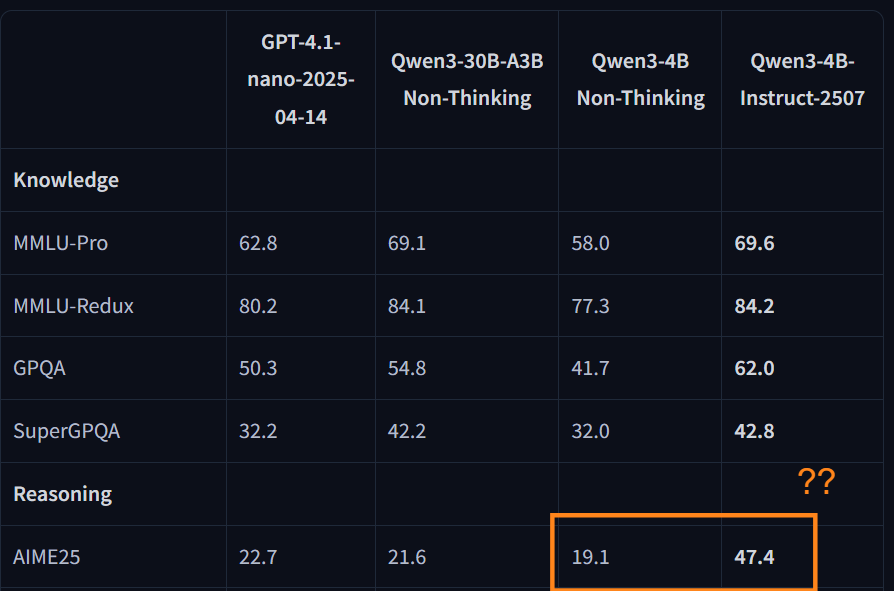
AIME25 gains remain outstanding even for a 4B-parameter dense model.
What’s going on?
Let’s dig in. In this article, we’ll replicate and analyze all Qwen3-30B-A3B variants on AIME25:
Qwen/Qwen3-30B-A3B (the original hybrid version)
Thinking “on”
Thinking “off”
First, we’ll verify the Qwen team’s reported scores using their recommended inference hyperparameters. Next, we’ll inspect the model’s generations to understand the gap between the hybrid and Instruct versions.
Although this piece focuses on Qwen3, the broader point is methodological: evaluations often hide many knobs, and raw accuracy can be misleading, especially with test-time scaling. We will determine what the Qwen team didn’t report that explains the high scores of the Qwen3 Instruct versions, while significantly deteriorating the user experience.
You can replicate my experiments using this notebook: