


Qwen2.5-VL: What's New and How Good Are They for Chart and Table Analysis
Can Qwen2.5-VL analyze cosmology data without any context?

The Qwen2-VL models rank among the most advanced vision-language models (VLMs), outperforming other open VLMs across most benchmarks. The largest variant, Qwen2-VL-72B, even competes with commercial alternatives like GPT-4o.
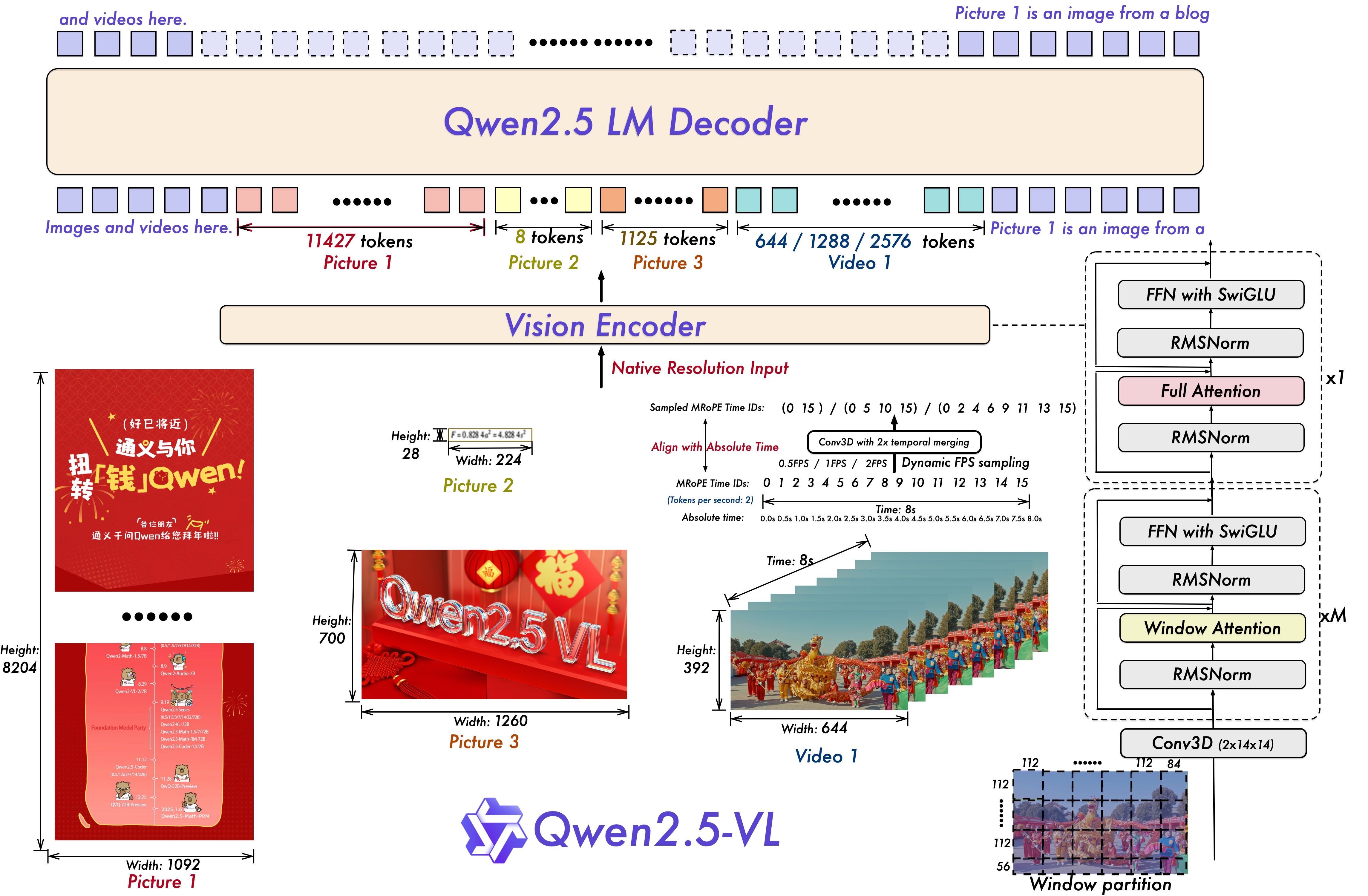
Building on this success, the Qwen team has introduced Qwen2.5-VL, leveraging the latest Qwen2.5 LLMs and incorporating training on more complex tasks. This new version demonstrates significant improvements across multiple domains, including:
Visual understanding, with enhanced object recognition, text, and graphic analysis.
Dynamic tool use, enabling agent-like interactions.
Long video comprehension, allowing precise event pinpointing.
Structured object localization, producing accurate, structured outputs.
Stable JSON generation, particularly beneficial for finance and commerce applications.
In this article, we will take a look at the updates introduced in Qwen2.5-VL. Since VLMs are resource-intensive, largely due to the high memory consumption of image tokens, we will also evaluate inference. Additionally, we will test the models on a range of real-world tasks, such as table and plot analysis.
The following notebook shows how to use Qwen2.5-VL, with examples: