
Most LLMs Don’t Comply with the Draft of the EU AI Act
A study by Stanford University

A study by Stanford University
The European Union (EU) tries to act fast on regulating AI. A first draft of potential rules to comply with regarding AI models has been issued:
MEPs ready to negotiate first-ever rules for safe and transparent AI | News | European Parliament
A study by Stanford University rated the most popular large language models (LLMs) according to their compliance with these rules.
GPT-4, Claude, PaLM 2, LLaMa, etc. none of them comply with these regulations.
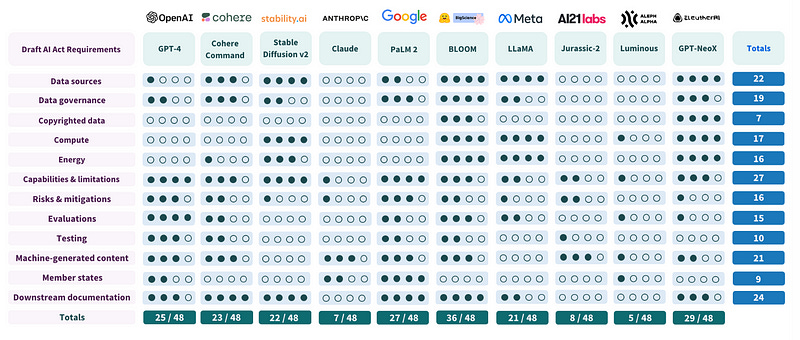
Each requirement can be summarized as follows:

Some LLMs almost comply. BLOOM for instance only misses a few points, mainly not disclosing EU member states where the model is on the market. These points are easy to get I think.
The main limitations of this study is that it could only look at models trained and released before the draft of the AI Act was published.
We can’t assess how difficult it is to comply with these regulations yet. BLOOM, and potentially most of the other LLMs, could have easily gotten more points if teams knew these regulations before training.
Disclosing Information about Training Data
The EU wants the actors to disclose much more information about the training data: sources, data governance measures, and copyrights.
This is probably on this point that big techs will argue the most. The trend is going in the other direction: companies provide less and less information about their training data.
I don’t see big tech companies complying with this point anytime soon.
Toward more Contaminated Evaluation
The AI Act also requires evaluations on standard benchmarks.
Most LLMs are directly trained on public benchmarks, i.e., the benchmarks are not removed from the training data. If the evaluation data are in the training data, the evaluation is “contaminated” and is thus scientifically useless and misleading.
All LLMs are impacted by data contamination because dealing with data contamination is extremely challenging. It can impact the performance and the marketing strategy:
Performance: If we remove the evaluation benchmark for a given task from the training data, the LLM will be less accurate for this task. Benchmarks are gold data. If you want your LLM to be as good as possible, which makes sense if you plan to turn it into a product like Open AI did with ChatGPT, you must train your models on all the available benchmarks.
Marketing strategy: Many actors ignore data contamination. They usually “assume” that the benchmarks are not in the training data, evaluate their LLM on the benchmarks anyway, obtain state-of-the-art results, and make headlines. No one could certify that the evaluation is credible, but at that point, the model is already popular. On the other hand, if you remove the benchmark from the training data, you will get lower results, you won’t reach a new state of the art, and your LLM will likely be ignored.
This is critical but regulations won’t solve this. We only need better scientific practices. See my recent studies about this for PaLM 2 and GPT-4:
PaLM 2 Evaluation: Automatic Summarization
Here we go again — Struggling with Contaminated Training Datamedium.com
The Decontaminated Evaluation of GPT-4
GPT-4 won’t be your lawyer anytime soontowardsdatascience.com
Encouraging evaluation is great, but if it comes at the cost of scientific credibility it is pointless.