


Meta MMS Better than OpenAI Whisper? Not So Sure…
“Our scores are not comparable, but they are better.” — A very classic reasoning in AI evaluation

Meta AI released the Massively Multilingual Speech (MMS) project. MMS introduces speech-to-text and text-to-speech for more than 1,100 languages.
I believe it will have a significant impact on the development of language technologies for understudied/low-resource languages.
As usual, Meta makes many claims in this release. And as usual, verifying these claims is difficult since Meta rarely discloses the evaluation pipeline.
But sometimes it is so obviously wrong or misleading that we just have to read the paper to spot the errors.
It’s Better, Trust Me!
I could easily spot errors within 1 hour after Yann LeCun tweeted about this work:
The evaluation problem I found is a very common one: Scores are copied from various papers and all put together in the same table to draw conclusions.
Unfortunately, researchers almost always fail to correctly compare copied scores. I demonstrated it many times: Meta, Google, OpenAI, Amazon, etc. all did it. Sometimes it even leads to some chains of errors with scores and wrong conclusions copied from one paper to another (check my review of PaLM’s evaluation for instance).
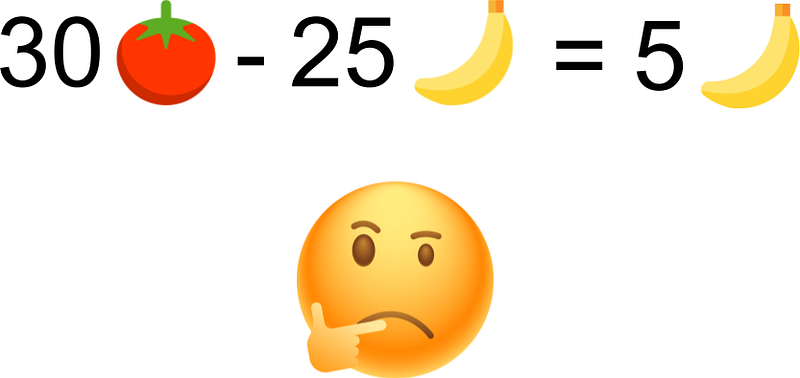
In Meta’s MMS, Meta makes the same error here:

Can you see where is the problem?
Hint: It is acknowledged in the caption.
Whisper scores are not comparable.
Update v1: What follows is my wrong understanding of the paper! Meta doesn’t claim that MMS performs better than MLS here. Thanks to Michael Auli for kindly correcting me.
— — — — — — — — — — — — — Original version— — — — — — — — — — —
In the analysis, we can read:
“Whisper results are not strictly comparable due to the different normalization but [MMS] appears to perform better on MLS”
My error here is that “it” was not [MMS] but “Whisper”
You can interpret it like this:
MMS is the best
We get better scores
By the way, the scores are not comparable
But MMS is the best
Indeed, it doesn’t make sense.
— — — — — — — — — — — — Corrected version— — — — — — — — — — — —
In the analysis, we can read:
“Whisper results are not strictly comparable due to the different normalization but [Whisper] appears to perform better on MLS”
You can interpret it like this:
Whisper is better
Because the score is better
By the way, the score is not comparable
But Whisper is better
Indeed, it doesn’t make sense.
Note: They do write some words like “not strictly” and “appears”. I have no idea what is a “not strictly” comparable score. Can we compare the scores or not? The answer is no.
This is not the first time I see this. OpenAI did the same in the Whisper paper. Comparing scores that are not comparable, acknowledging it, but still claiming to be better because the scores are better. I complained about it here:
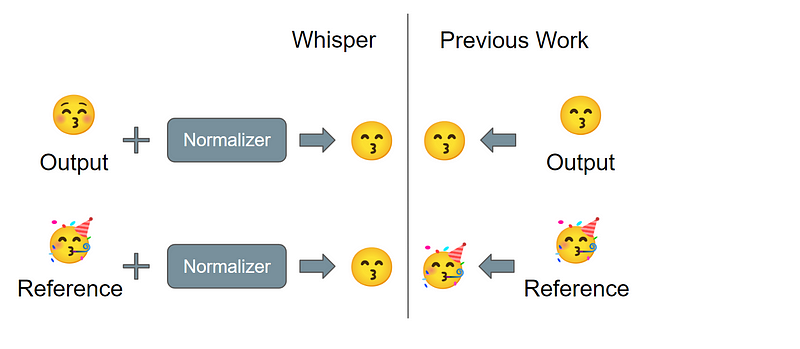
I only scanned quickly the MMS paper. There could be other errors like this. I’m especially skeptical that the other scores in this table (not with a *) are all comparable.
WER scores are usually computed on normalized texts. I don’t know how Meta can have the guarantee here that all the scores were computed with the same normalization.
Google doesn’t publish code or details.
The VoxPopuli work published an evaluation pipeline that lowercases everything and keeps only ASCII characters in addition to some punctuation processing of the references.
Did they all do the same thing? I doubt it.