


Hi Everyone,
In this edition of The Weekly Kaitchup:
Is LoRA as Good as Full Fine-Tuning?
DeepSeek V3.2 with Sparse Attention
JetNemotron 2B and 4B: Efficient LLMs with PostNAS
IBM Granite 4.0: MoE-Hybrid-Instruct-Only
Is LoRA as Good as Full Fine-Tuning?
This is a long-standing debate: Is LoRA as good as full fine-tuning (FFT)?
ThinkingMachine published some interesting findings to better answer this:
So, what does it say? Yes, LoRA can be as good as full fine-tuning, if you do it right (of course)!
You can find many papers that already showed this. But the fact that a multi-billion-dollar company says it may convince more LLM users.
What is outstanding in their article is the scientific rigor with which it was written. Many hyperparameter configurations have been tested, and all the results have been explained.
The most important points of this article:
LoRA underperforms when the dataset size exceeds LoRA’s capacity (pretraining-like, very large data). For small-to-medium post-training datasets, it matches FFT. Their experiments run one epoch on Tülu-3 SFT and subsets of OpenThoughts3. Tülu-3 SFT is about 0.94M examples. They treat this as standard post-training scale. Sounds familiar? I did the same thing a few months ago, and also found that LoRA can get close to Tülu-3’s full SFT.
You shouldn’t care about the α. They set it to 32 and tuned the other hyperparameters instead, plus they show parametrization invariances that make many α/LR/init choices effectively equivalent under the usual LoRA scaling.
Higher rank helps on bigger SFT datasets (they sweep ranks 1–512; higher ranks track FFT longer before hitting capacity). Your 64–256 rule-of-thumb is a good practical band.
Optimal LR for LoRA is much higher than FFT and ~independent of rank. They empirically find about 10x the FFT LR (even higher for very short runs).
Large batches penalize LoRA more than full fine-tuning, and the gap grows with batch size; increasing rank doesn’t close it. I’m cautious about that conclusion because their runs appear to keep the learning rate fixed. When batch size changes, the learning rate typically needs to change as well (and the best setting depends on the optimizer and schedule).
Even if the effect holds, many large-dataset setups require bigger batches to keep training time reasonable and fully utilize GPU parallelism. In practice, you tune batch size and LR together.
For MoE, prefer per-expert LoRA and scale rank with the number of active experts to keep parameter ratios consistent.
In RL, even very low ranks work fine. rank = 1 works. They didn’t just use a math-heavy Qwen: they show rank-1 LoRA matches FFT on GSM8K/MATH using Llama-3.1-8B-base, and they also run larger-scale RL on Qwen3-8B-base (DeepMath). So yes: RL works with LoRA, and it can be quite cheap! This is well-motivated, but in practice, I don’t make this observation. With a standard rank, e.g., rank=32, I always get better results and faster than with lower ranks. I wonder, but this finding might only be applicable to some special combinations of task/dataset/model.

As someone who uses LoRA extensively, I can see how much work went into this study. They didn’t need huge GPUs, models were small and LoRA is memory-efficient, but they did need many GPUs to run the sweeps in parallel.
Why would a multi-billion-dollar company like ThinkingMachines focus on a PEFT method such as LoRA? Twenty-four hours later, the answer was obvious: they launched Tinker, an API that simplifies distributed fine-tuning (handling GPU failures, allocation, etc.), via LoRA.
DeepSeek V3.2 with Sparse Attention
Following the release of DeepSeek V3.1 “Terminus”, I was expecting a V4 or an R2. DeepSeek AI released a V3.2 “Experimental”:
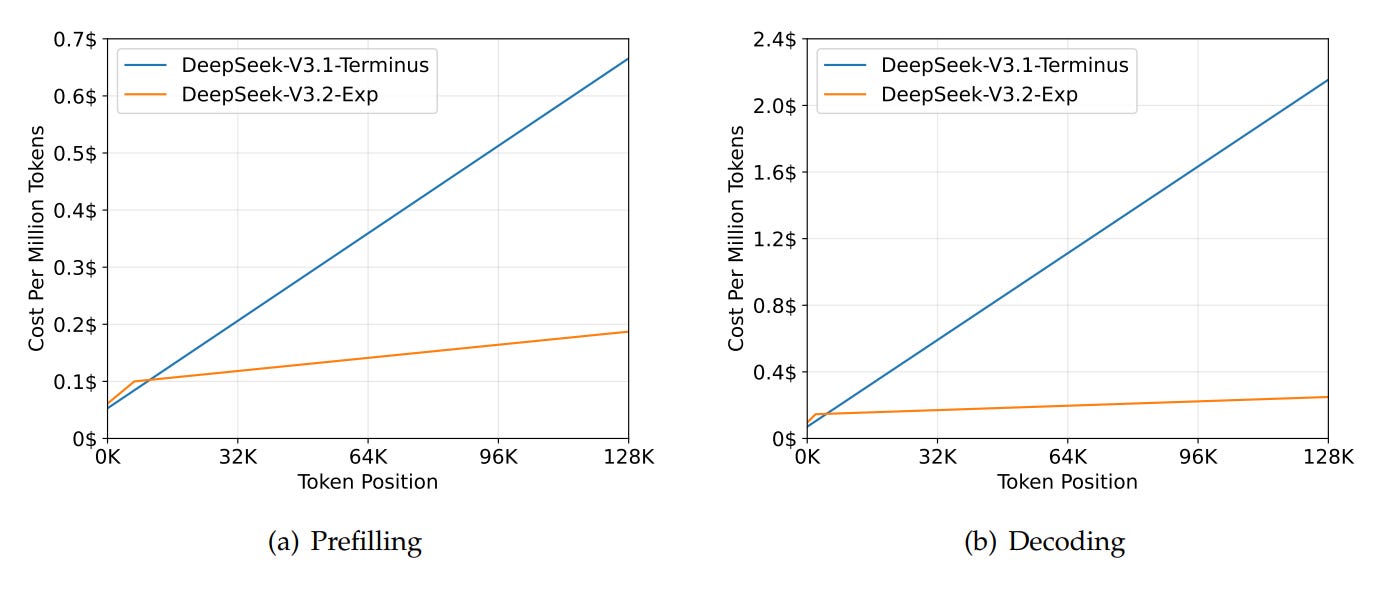
According to the benchmarks, it is not significantly better than “Terminus”. It’s even slightly behind for some tasks. However, it is much more efficient!
DeepSeek-V3.2-Exp is an experimental follow-on to V3.1-Terminus that keeps the same overall architecture while swapping its attention core for “DeepSeek Sparse Attention” (DSA).
Mechanically, DSA replaces full attention with a fine-grained sparse pipeline:
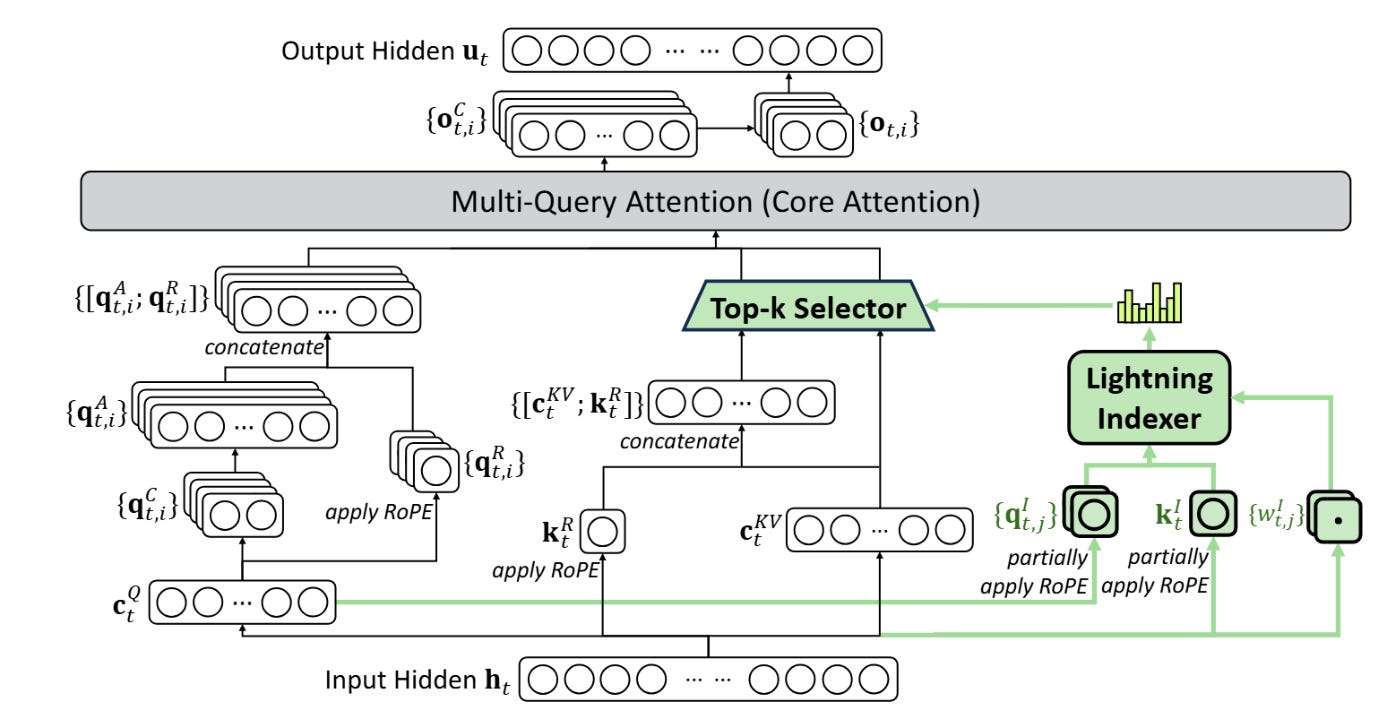
A lightweight index/selector produces a per-query shortlist of candidate keys using downsampled or cached summaries, often combining a local sliding window with a small set of global/sentinel positions
The model then performs attention only over those selected indices, executed by sparse kernels (FlashMLA) that support token-level sparsity and KV cache compression (multi-query / MLA style, frequently stored in FP8) for both prefill and decode
The selection is trained end-to-end so the pattern adapts with the model, rather than being fixed heuristics. This design mirrors the natively-trainable sparse-attention line DeepSeek described earlier (NSA), which couples coarse token compression with fine token selection to preserve global awareness and local precision while cutting memory and FLOPs—DSA applies that idea to V3.2’s serving/training stack with hardware-aligned kernels.
In practice, that means long sequences are handled by cheaply pruning most distant tokens and only scoring a small, relevance-filtered subset, keeping recent tokens and a few globally important ones, so prefill scales sub-quadratically and decode benefits from smaller KV traffic. Because FlashMLA’s kernels are built for these sparse/indexed lookups (and MLA’s shared-KV layout), throughput improves without an obvious drop in quality on public tests.
DeepSeek doesn’t just open-source strong models. They also ship new technologies that other LLM providers take months to adopt. Their sparse MoE-style architecture has since become common (e.g., Qwen3, GPT-OSS). By contrast, DeepSeek’s MLA remains, so far as I know, unique to their models and often outperforms GQA. How long will it take for others to adopt DSA?
source: https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
JetNemotron 2B and 4B: Efficient LLMs with PostNAS
Jet-Nemotron models are efficient LLMs that replace parts of standard attention with “JetBlocks.” NVIDIA developed a post-training neural architecture search (PostNAS) that tries alternative sequence modules (e.g., Gated-DeltaNet, Mamba-2, etc.) and inserts them where they deliver the best speed–accuracy trade-off. They then run a hardware-aware search to choose the dimensions of these blocks for a given GPU setup.
The result: up to 50× faster inference than the original baselines with slightly better accuracy. I’m just not sure whether it can really be applicable to larger models, as linear attention modules usually don’t scale well. They only released 2B and 4B models.
I reviewed the approach in more detail in The Salt:

They released the inference code this week, but I was hoping for the training and PostNAS code as well. I’m not sure they’ll open-source it, as supporting multiple attention block types is complex and costly to maintain.
GitHub: NVlabs/Jet-Nemotron
Models: Jet-Nemotron
IBM Granite 4.0: MoE-Hybrid-Instruct-Only
IBM’s release is unusual: while many teams focus on reasoning models, IBM shipped open-weight Granite 4.0 that doesn’t appear to be trained for explicit “thinking.”
Granite 4.0 Language Models (Apache 2.0)
They are Instruct models.
They use a hybrid MoE design with Mamba-2 layers for more efficient inference, another sign that “linear” attention variants are gaining traction (Nemotron-H, LFM2, Qwen3-Next, …). Base versions are also available for fine-tuning.
The naming is… unexpected: Micro (3B), Tiny (7B), and Small (32B), apparently 7B counts as “tiny” now!
By IBM’s reported results, the models score well on standard (though aging) benchmarks like MMLU-Pro and IFEval. I’ll add them to The Kaitchup Index.
The Salt
The Salt is my other newsletter that takes a more scientific approach. In The Salt, I primarily feature short reviews of recent papers (for free), detailed analyses of noteworthy publications, and articles centered on LLM evaluation.
I reviewed in The Weekly Salt:

⭐Random Policy Valuation is Enough for LLM Reasoning with Verifiable Rewards
Pretraining Large Language Models with NVFP4
Thinking Augmented Pre-training
That’s all for this week.
If you like reading The Kaitchup, consider sharing it with friends and coworkers (there is a 20% discount for group subscriptions):
Have a nice weekend!
“LoRA Without Regret” in context to your “LoRA at Scale” work totally confirms what we all know about you and why we read your work!!! The AI startups must monetize something for their investors, so they might as well provide a service for tuning open models.
I wonder if and when vLLM will support Jet Nemotron models.